728x90
📌 핵심
- Task : Transformer, Self - Attention
✅ Self Attention
🔹 Seq2Seq learning
- NMT, QA, Summarization
- 가변 길이의 data 를 고정 크기의 vector 또는 matrix 로 표현하는 과정이 필수적

🔹 기존 RNN 계열 모델의 한계점
- RNN 계열의 모델은 병렬화가 불가능
- long-term dependency 를 잘 반영하지 못함 : LSTM, GRU 도 입력 시퀀스가 굉장히 긴 경우에 이를 잘 반영하지 못함

🔹 CNN 모델의 한계점
- CNN 은 병렬 처리가 가능하지만 long-term dependency 를 위해 다수의 레이어가 필요하다

🔹 Self attention
- 병렬화가 가능하고 각 토큰이 최단거리로 연결되기 때문에 long-term dependency 문제 해결도 가능하다.
- LSTM, RNN 같이 learning mechanism 으로 다양한 모델에 활용될 수 있다.

- 모델의 차원이 입력 시퀀스 길이보다 큰 경우가 많기 때문에 일반적으로 self-attention 의 연산량이 가장 작다

⭐ Self attention 은 각 토큰을 sequence 내 모든 토큰과의 연관성을 기반으로 재표현 하는 과정으로 해석할 수 있다.

🔹 Self attention Process
① Input 을 linear transformation 하여 query, key, value 생성

② Query 와 key pair 의 dot product 계산

③ Scaling 적용 : sclaed dot product attention
- attention score 들을 보다 다양한 벡터에 분산시키는 효과
- 스케일링을 하지 않으면 score 들의 분산이 커져서 gradient 전파가 잘 안이루어질 수 있다. gradient 전파 가 잘 이루어져 다양한 벡터들의 정보들을 잘 수합할 수 있도록 해야 한다.
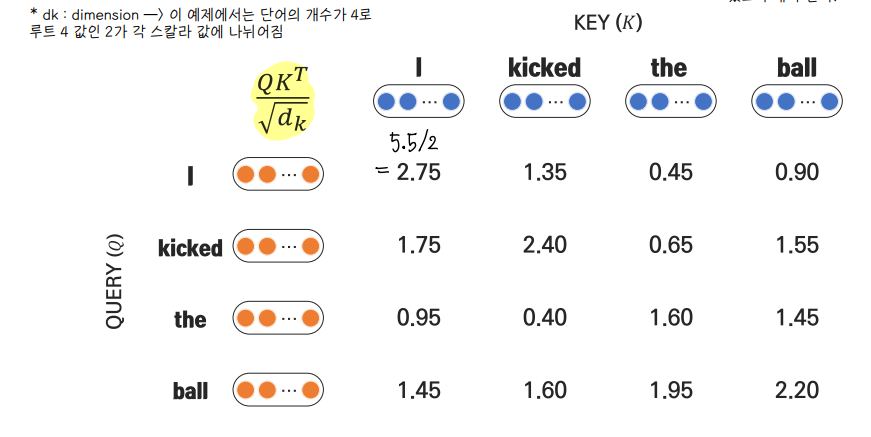
④ Softmax function 적용

⑤ Softmax output 을 weight 로 value vector 들의 weighted sum 을 산출

🔹 Self Head Attention
- 한 문장 내에도 다양한 정보가 존재하며 한 번의 attention 으로 모든 정보를 적절히 반영하기 어렵기 때문에, 다양한 attention weight 를 통해 값을 얻는다.
- 서로 다른 scaled dot product attention 을 ㅇ러번 적용하여 concat 한다.





✅ Transformer
🔹 구조
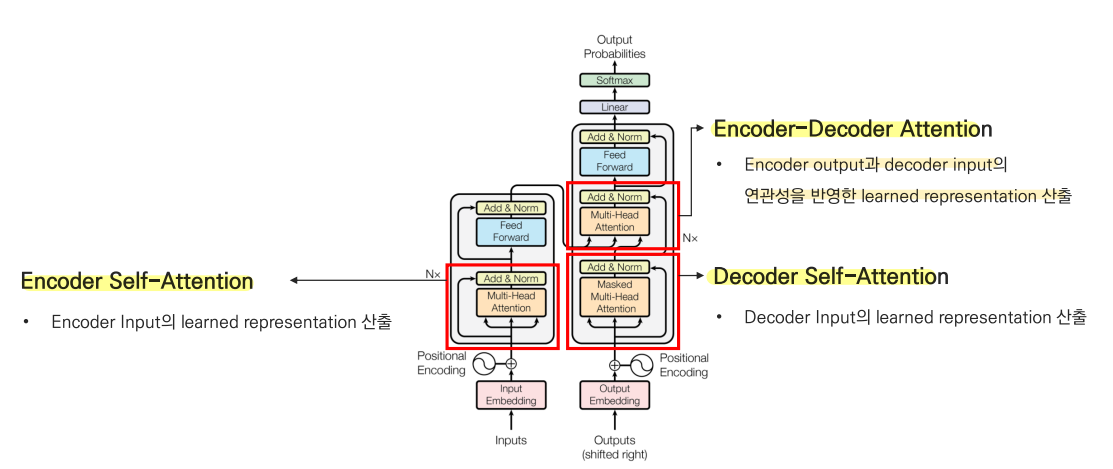
- Encoder self attention : Encoder input 의 learned representation 산출
- Decoder self attention : Decoder input 의 learned representation 산출
- Encoder - Decoder attention : Encoder output 과 decoder input 의 연관성을 반영한 representation 을 산출
🔹 Image Transformer

🔹 Music Transformer

728x90
'1️⃣ AI•DS > 📗 NLP' 카테고리의 다른 글
| [cs224n] Future NLP (2021 version) (0) | 2022.07.18 |
|---|---|
| [cs224n] 18강 내용정리 (0) | 2022.07.18 |
| [cs224n] 15강 내용정리 (0) | 2022.07.04 |
| [cs224n] 13강 내용정리 (0) | 2022.07.04 |
| NER 실습 (0) | 2022.06.02 |




댓글