💡 주제 : Contextual Word Representations and Pretraining
📌 핵심
- Task : Word representation (Word embedding) , pre-training
- ELMO, Transforemr, BERT

1️⃣ Reflections on word representations
1. Word representation
✔ word embedding
◽ 워드 임베딩을 통해 단어를 벡터로 표현하여 컴퓨터가 이해할 수 있도록 자연어를 변환해준다.
◽ Word2Vec, GloVe, fastText 등을 학습
2. Pre-trained word vectors
사전 훈련된 단어 벡터 모델이 학습한 Vocabulary 에서 각 단어마다 매칭되는 word vector 가 존재하고 index 를 사용해 필요한 단어의 word vector 를 불러올 수 있다.
✔ 2012 년 이전 word vector

◽ 2012 년 이전까지 POS tag task 과 NER task 에서 위와 같은 성능을 보였다.
◽ 당시 SOTA 는 딥러닝 모델이 아닌 Rule-based 방법론을 사용한 모델이었다.
◽ 세번째 모델 → word2vec 같은 unsupervised NN 을 supervised NN 과 결합한 방법
✔ 2014년 이후

◽ 2014년 이후 단어표현 방법으로는 pre-train 된 단어 벡터를 사용하는 것이 그렇지 않은 경우보다 성능이 좋다.
◽ Pre-trained word vector 를 사용하면 성능이 더 좋은 이유는, task 에 쓰이는 데이터보다 방대한 unlabeled 데이터에 의해 학습된 결과를 활용하기 때문이다.
✔ Pre-trained word vector 의 장점 : unk 토큰 처리에 효과적


◽ UNK 토큰 : 데이터 셋에서 잘 나타나지 않는 단어 (train 시 5회 이하로 등장하는 단어) 혹은 test 데이터에만 존재하는 단어를 UNK 토큰으로 분류한다.
◽ UNK 토큰은 비록 빈도가 낮지만, 만약 중요한 의미를 가지는 단어인 경우 뜻을 놓치게 될 수 있다. 특히 Question and Answering task 에서는 단어 간 대응을 하는 것이 중요한 task 로 이러한 문제에 주목할 필요가 있다.
💨 UNK 토큰을 처리하는 방법에는 char-level model 을 이용하여 단어 벡터 생성, random vector 를 부여해 단어사전에 추가하는 방법 등이 존재하지만 pretrain word vector 를 사용하는 것이 가장 효과적이다.
3. 단어 당 1개의 표현식을 갖는 경우 발생하는 문제
✔ same representation, but different context

◽ 1개의 단어를 1개의 벡터로 표현하면 동음이의어와 같은 문제를 발생시킨다.
◽ 즉, 문맥에 따라 달라지는 단어의 의미를 포착하지 못하는 문제와 단어의 언어적, 사회적 의미가 달라지는 측면을 고려하지 못하는 문제가 발생한다.
✔ Solution
Contextual Word vector : 문맥을 고려한 단어 벡터 생성

👀 Language model
💨 input : Pre-trained 단어
💨 output : Next word
◽ Neural Language model 로 문맥을 고려한 단어 벡터를 생성할 수 있다.
◽ LSTM 구조의 LM 모델은 문장 순서를 고려해 다음 단어를 예측하는 모델로 sequence 학습을 통해 문맥을 반영한 단어 표현이 가능해질 수 있도록 한다.
👉 이러한 특징을 활용한 모델이 바로 ELMo
2️⃣ Pre-ELMo and ELMO
1. Pre-ELMo
👉 ELMo 발표 이전에 제시한 TagLM 을 Pre-ELMo 라고 강의에서 지칭
👉 ELMo 와 아주 유사한 형태의 구조를 가짐
✔ 아이디어
🔹 NER task 를 위해 large unlabeled corpus 를 사용하여 neural Language model 을 Training 한다.

◽ RNN 으로 문맥에 담긴 뜻을 학습
◽ NER task 같이 일반적으로 학습에 사용되는 데이터는 크기가 작은 labeled data 이다 → Large unlabeled corpus 로 먼저 학습을 시키는 semi-supervised 접근 방식을 사용해보자!
✔ 전체적인 구조
pre-trained word vector + pre-trained language model
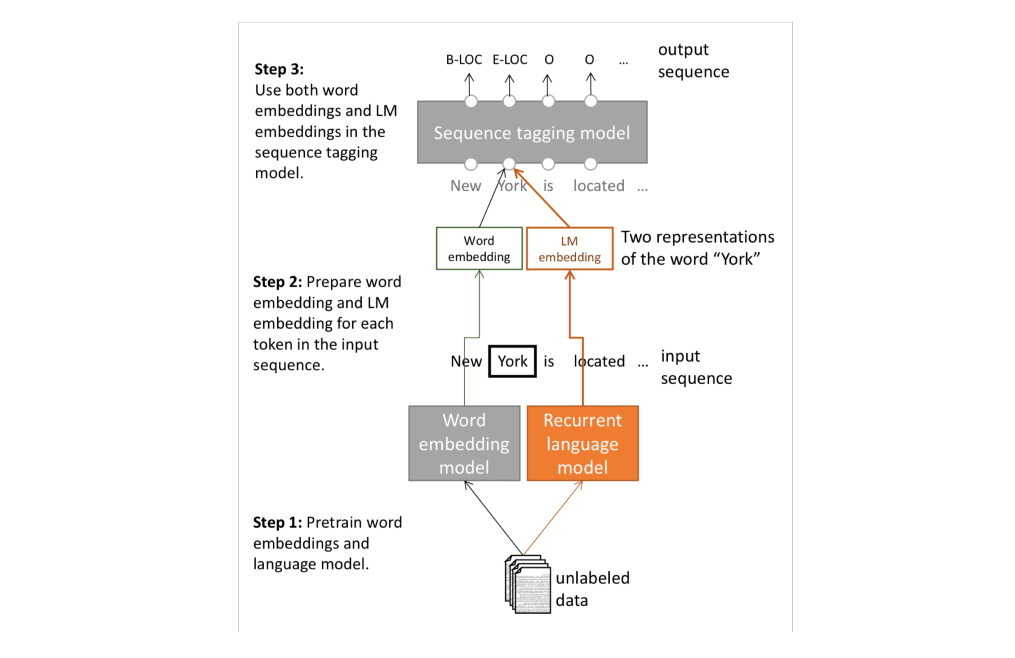
1. Word embedding 과 LM 을 Pre-training 한다.
- input 에 대해 Word2vec 같은 word embedding model 로 단어 벡터를 학습한다.
- input 에 대해 bi-LSTM 같은 RNN 이 적용된 word embedding 모델을 통과한다.
2. input sequence 의 단어 토큰 각각에 대해 word embedding 과 LM embedding 을 준비한다 → Two representations
- 2가지 접근법으로 만들어진 단어 벡터를 small task labeled 에 사용한다.
3. 두 임베딩 표현식을 사용해 sequence tagging model 에 입력한다.
- 단어의 특징 자체를 고려한 벡터와 문맥을 고려한 벡터를 모두 사용한다.
✔ 구조

◽ 왼쪽 : Word2Vec 의 token representation word vector 와 char-level CNN model 로 학습한 word vector
◽ 오른쪽 : pre-trained model 로 학습한 word vector
👉 두 word vector representation 을 모두 반영
✔ 학습
① Pretrian LM
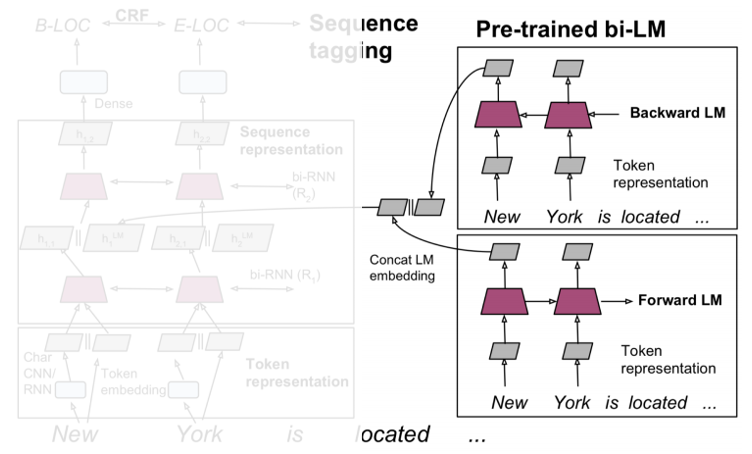
◽ 8억개의 단어가 있는 데이터셋인 'Billion Word Benchmark' 데이터 셋을 이용하여 사전훈련
◽ Bi-LM 로 pre-train 을 진행하여 Forward (순방향) LM, Backward (역방향) LM 에 input 이 각각 별도로 들어가게 된다.
◽ 각 LM 에서의 output 은 concat 된다.
② Word embedding and Char-CNN

◽ Pre-trained model 이 학습하는 동안, 모델은 현재 입력 단어가 주어지면 다음 단어를 예측한다.
◽ 이때 input 단어는 Word2Vec (token embedding) 과 Char CNN 으로 표현한다.
◽ output 은 concat 되어 2-layer Bi-LSTM 의 첫번째 레이어 input 으로 입력된다.
③ Use both word embeddings and LM for NER

◽ Bi-LSTM 의 first layer 의 output 은 사전훈련된 LM 에서의 최종 output 과 concat 되어 2nd layer 로 입력된다.

✔ 성능

◽ Bi-LSTM Language model 을 적용했을 때 1% 성능 향상을 보임
2. ELMo : Embedding from Language Models
✔ 아이디어
⭐ 모든 문장을 이용해 문맥이 반영된 word vector 를 학습한다.

◽ 기존 단어 임베딩이 window 를 이용해 주변 문맥만 이용한 것과 대조되는 방식이다.
◽ 또한 pre-ELMo 와 달리 word embedding 은 Char CNN 만을 사용한다. (Not Word2Vec)
◽ char-CNN 모델로 단어의 특징을 고려한 word vector 를 구한 후 이를 LSTM 의 input 으로 사용해 최종 word embedding 결과를 도출하는 과정을 가진다.

✔ 구조

◽ 2-layer Bi-LSTM : 순방향 LM 과 역방향 LM 이 모두 적용된 2개의 layer 구조를 가진다.
◽ 순방향 모델은 문장 sequence 에 따라 다음 단어를 예측하도록 학습
◽ 역방향 모델은 뒤에 있는 단어를 통해 앞 단어를 예측하도록 학습
◽ 모든 layer 의 출력값을 활용해 최종 word embedding 을 진행한다 → 최종 layer 값만 사용하던 이전 모델들과의 차이점
👉 순/역방향 layer 를 통해 특정 단어 및 해당 단어의 앞쪽/뒷쪽 정보를 포함한 단어에 대한 각 layer 별 출력 값이 존재하며 모든 layer 출력값을 활용해 최종 word vector 를 임베딩 한다.
✔ 학습
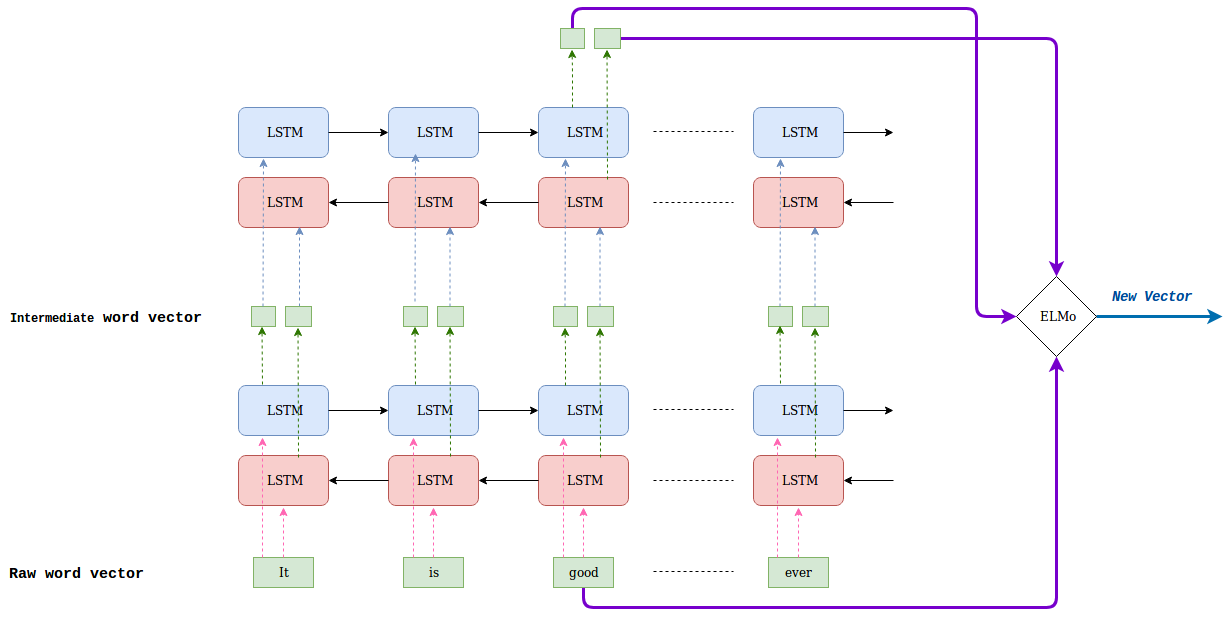
① Forward LM , Backward LM
◽ input 으로 들어오는 문장과 단어는 char-CNN 으로 임베딩 된다 → 단어 자체의 특징 도출
◽ first layer → char-CNN 결과에 residual connection 을 적용하여 문맥으로부터 영향을 받지 않도록 하며 (즉, 단어 제체의 특징을 유지) gradient vanishing 문제를 완화시킨다. output 으로는 중간 word vector 가 출력된다.
◽ second layer → fist layer 에서 얻은 결과를 바탕으로 중간 word vector 를 출력한다.
👉 I read a book yesterday 와 같은 문장에서, read 는 과거형과 현재형이 일치한다. 보통 모델은 현재형으로 동사 임베딩을 출력할 가능성이 높은데 이때 역방향 모델을 같이 활용하여 yesterday 같은 시간 표현으로 과거형임을 인지해 보다 정확한 임베딩을 뽑아낼 수 있다고 한다.

② Forward LM, Backward LM 의 각 layer 의 출력값을 추출하고 이를 층별로 concat 한다.
③ layer 별 concat 출력 결과에 정규화 된 가중치를 곱함으로써 선형 결합하여 학습을 통해 최적화 한다.
④ 모든 layer 의 벡터를 더해 하나의 임베딩 word vector 를 생성한다.
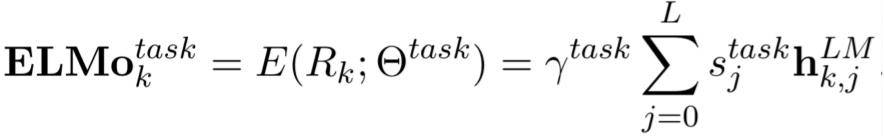

👉 문법적 특징을 고려한 lower layer 정보와 의미론적 특징을 고려한 higher layer 정보를 모두 활용하여 효과적인 word vector 결과를 얻는다.
👀 참고
💨 syntax 문법적 정보 → tagging, NER 같은 단어 자체가 가지고 있는 특징을 의미
💨 semantics 문맥적 정보 → 문맥이 고려된 특징
👀 ELMo 의 트릭
💨 Fine-Tuning 단계에서는 Bi-LSTM layer 가 동일한 단어 시퀀스를 입력받지만 Pre-training 단계에서는 forward, backward 네트워크를 별개의 모델로 보고 서로 다른 학습 데이터를 입력한다. 즉, 각 layer 의 hidden vector 를 더하거나 합치지 않고 각각 독립적으로 학습한다.
✔ 성능
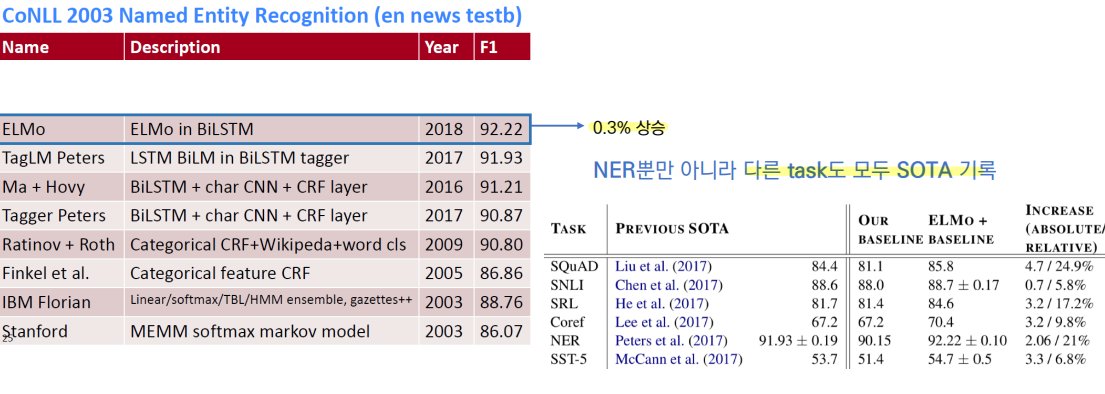
◽ NLP 분야에서 굉장한 놀라움을 선사한 모델로 NER 뿐만 아니라 대부분의 task 에서 SOTA 의 성능을 보여주었다.
3️⃣ ULMfit and onward
1. ULMfit
Universal Language Model Fine-Tuning for Text Classification
✔ transfer learning

◽ NLP 에서 본격적으로 transfer learning 이 도입되게 된 시점으로 ULMFit 은 NLP 에서 본격적으로 Transfer learning 을 도입한 첫 사례이다.
◽ transfer learning : 대량의 다른 데이터로 일반적인 학습을 진행한 뒤, 특정 task 의 목적에 맞게 다시 튜닝으로 성능을 개선하는 것
◽ ULMfit 은 text classification 를 목적으로 한다.
2. 구조

(a) 일반 언어 모델 학습
◽ 대량의 corpus 를 기반으로 LM 학습 → Pre-trained
◽ 논문에서는 위키피디아의 정제된 28,595개의 문서와 단어를 기반으로 3 layer Bi-LSTM 언어 모델을 학습했다.
(b) task 맞춤형 LM 튜닝
◽ 학습된 언어 모델을 토대로 주어진 task 에 맞게 추가 학습을 진행한다.
◽ 가령 100개의 text 와 그에 따른 label 데이터로 구성된 task 라면, 해당 데이터만을 가지고 다시 학습 및 업데이트 과정을 거친다.
💨 Discriminative Fine-tuning : layer 별 학습률을 서로 다르게 조정하는 fine-tuning 방법으로 깊은 layer 에 대해서는 더 작은 학습률을 부여한다.
💨 Slanted triangular learning rates : 튜닝 횟수에 따라 초반에는 작은 학습률을 적용하다가 점차 학습률을 증가시켜 200번의 학습 후 다시 학습률을 점진적으로 감소시킨다.
(c) Classifier fine-Tuning
◽ 분류 layer (softmax) 를 추가하여 학습을 진행해 word vector 가 분류기로 출력된다.
◽ 마지막 layer 로부터 서서히 gradient 를 흘려보내는 gradual unfreezing 기법을 이용한다.
3. 성능

◽ train dataset 이 부족함에도 불구하고 pre-trained 된 ULMfit 모델을 사용하게 되면 error rate 이 낮음을 알 수 있다.
4. Onward ∘∘∘


◽ ULMfit 이후로 모델의 파라미터를 늘리고 데이터 양을 늘려 기하급수적으로 리소스가 필요한 모델이 등장하게 된다.
◽ GPT, BERT 와 같은 모델은 글로벌 기업에서 엄청난 양의 데이터를 기반으로 학습한 pre-trained 모델을 제공하며, 모두 Transformer 기반의 모델임을 알 수 있다.
4️⃣ Transformer architectures
1. Motivation of Transformer
✔ RNN 알고리즘의 한계
◽ Sequential 하게 데이터를 처리하므로 병렬적인 계산이 가 불가능하여 속도가 매우 느리다.
◽ input 데이터의 seqeuntial 한 특징으로 인해 입력이 길어질 수록 멀리 위치한 정보에 대한 값이 희박해진다 👉 Long-term dependency
✔ LSTM, GRU
◽ Long-term dependency 를 해결하기 위한 모델들이 등장했지만 여전히 긴 문장에 대해서는 잘 동작하지 못함
✔ Attention
◽ 어떤 State (time step) 으로도 이동할 수 있게 해주는 모델 구조 → 모든 state 를 참조
◽ Seq2Seq 구조에서 RNN 계열 모델들과 함께 사용되다가 Attention 만을 이용하는 Transformer 모델이 등장
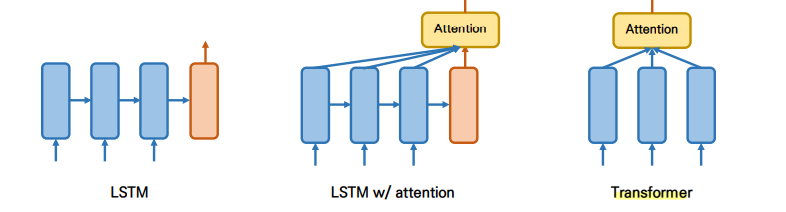
2. Overview

✔ None-recurrent Seq2Seq encoder-decoder model
◽ machine translation with parallel corpus
◽ 기계번역을 위한 input 은 encoder 로 output 은 decoder 로 할당됨
◽ Decoder 의 특정 time-step 의 output 이 encoder 의 모든 time-step 의 output 중 어떤 부분과 가장 연관성이 있는지 파악 👉 decorder 에서 output 으로 나오는 매 time step 마다 encoder 의 전체 step 을 참고
✔ input
Attention(Q, K, V) = Attention Value
◽ Query, ket, value → Query 와 key-value pair 의 유사성을 비교
◽ 처음 단어벡터 input 에서는 Q=K=V → 문장이 자기 자신을 보며 단어 간 유사성을 파악한다.
◽ Tokenizing → byte-pair encoding , 시간 순서 고려 → positional encoding
✔ Output
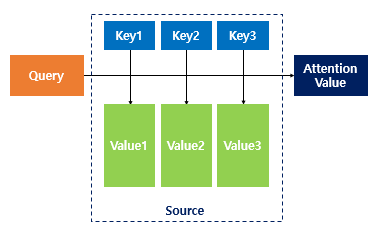

◽ weight : query 와 key 간 유사성 👉 key 와 맵핑 된 각각의 Value 에 반영 👉 유사도가 반영된 Value 를 모두 더해서 반환 = Attention Value

✔ Scaled Dot-product Attention
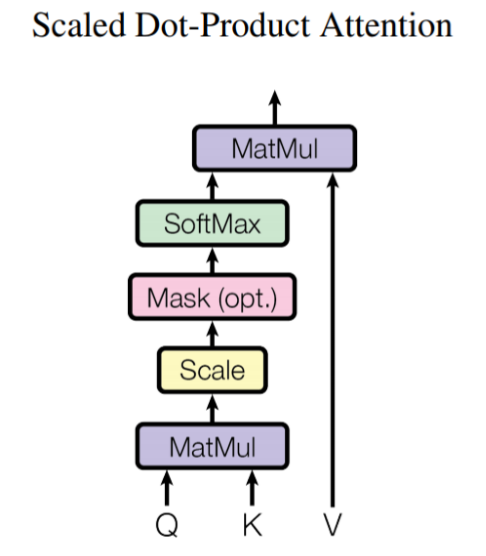
◽ Problem : 단어 사전의 차원(dk)이 커지면 내적 값 q'k 분산 (값의 차이) 이 증가 → softmax 를 통과하면 값이 커짐 → graidnet 를 더 작게 만들어 학습에 악영향 초래
◽ Solution : 길이 scale 보정 (dk) 을 통해 gradient 최적화를 유도한다.
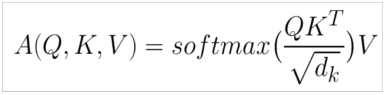
3. 구조
✔ Self Attention
◽ 입력 데이터 Query 가 있을 때, 검색 대상이 되는 key-value pair 데이터 테이블이 Query 자기 자신인 경우
◽ 문장 내 단어들 간의 관계 파악
✔ Multi-head attention

◽ self-attention 을 여러번 적용한 개념
◽ self-attention 을 여러 weight 로 진행해 다양한 맥락/정보를 파악할 수 있게 한다 👉 head 수 만큼 attention 을 진행한 후 concat 한다.
✔ transformer Encoder block
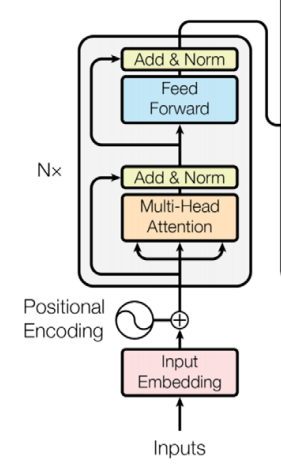
◽ Multi-head attention block , feed forward with ReLU activation , Residual connection & layer normalization
✔ transformer Decoder block
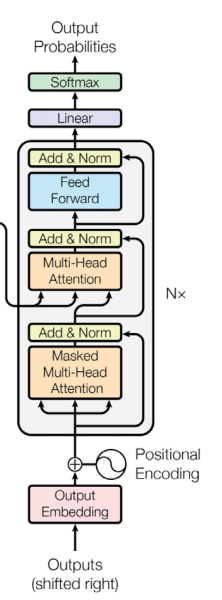
◽ target sequence 번역 대상에 multi-head attention 적용
◽ Masked Multi-head attention : Making 을 통해 query 단어가 이전 timestep 의 key 단어만 보도록 설정
◽ 두 번째 block 에서 Encoder block 의 output 을 key-value 로 받아 target sequence query 와 self attention 을 진행
✔ 정리
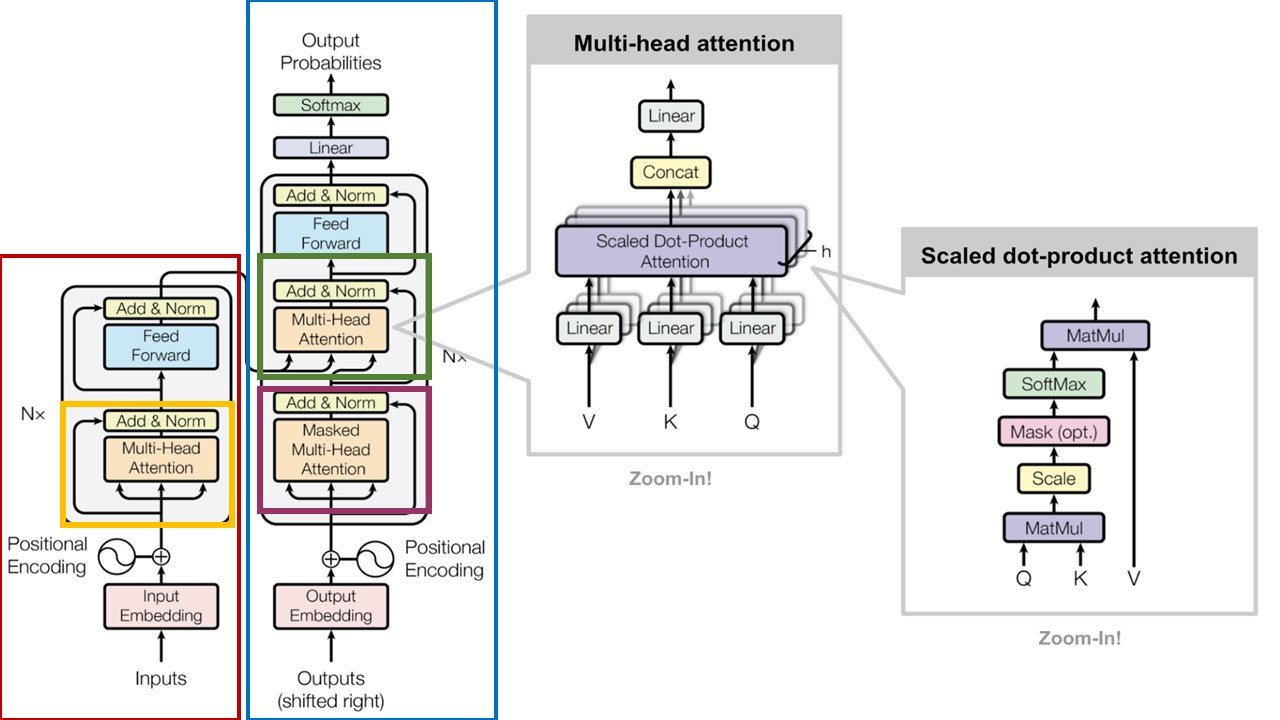
1. Encoder 에서 Self attention (노랑) ← 번역 대상 문장
2. Decoder 에서 Self-attention (자주) ← 번역 결과 문장
3. Encoder 와 Decoder 에서 attention (초록)
✔ Result


5️⃣ BERT
Transformer 는 기계번역을 위한 seq2seq translation model
⭐ BERT 는 Transformer 의 encoder 부분을 차용한 Bi-directional language model
👀 2018년 11월 구글이 공개한 언어모델
1. Bi-direction Encoder Representations from Transformers
✔ bi-directional Transformer Encoder 로 Language model Pre-training
◽ 기존 LM 은 Unidirectional 한 방향으로만 동작 (왼쪽/오른쪽 context 를 사용) 👉 조건부 확률의 개념을 성립하게 하기 위해 방향성을 도입한 것임
◽ Bi-directional 의 순방향, 역방향도 각각 독립적으로 진행되므로 sequence 에 따라 진행된다는 특징에 따라 단어를 예측함에 있어 전체 단어를 모두 활용할 수 없다는 문제점을 갖는다.
◽ Bi-directional Encoder 에서는 단어들이 자기 자신을 볼 수 있다.

2. Masked Language Model
✔ 문장의 15% 를 [MASK] 토큰으로 변경 한 후 원래 단어를 예측

✔ Next sentence prediction

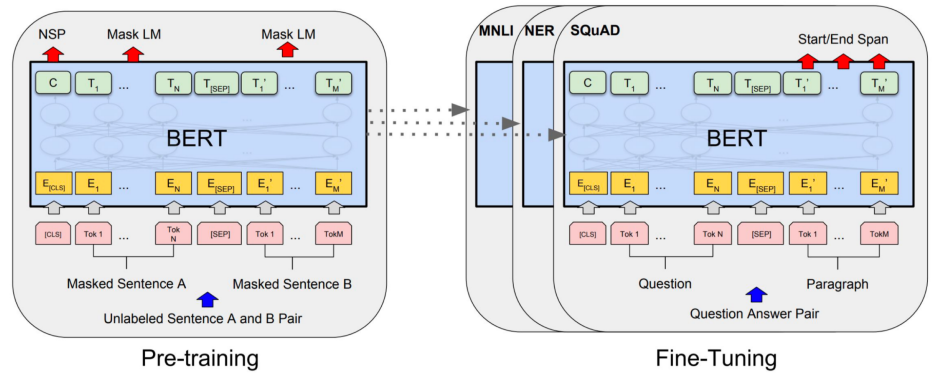
✔ Pre-Training
BERT 모델의 구조는
(1) 대량의 텍스트에 대한 semi-supervised 과정인 Pre-training : MLM, NSP
(2) target task 에 대한 supervised 과정인 Fine Tuning 으로 구성된다.
🔸 Transformer 의 Encoder 만을 이용해 Language model 학습을 수행한다.
◽ Self-attention 👉 attention 으로만 이루어져 긴 문장이라도 학습에 동등한 기회를 갖는다.
◽ layer 당 한 번의 계산만 필요 👉 병렬계산이 가능, GPU/TPU 에 효율적
🔸 두 종류의 모델이 존재
◽ BERT-Base : 12 layer, 768 hidden , 12 head 👉 SOTA (GPT) 모델과 비교 목적
◽ BERT-Large : 24 layer, 1024 hidden , 16 head
3. Training , Tuning
🔸 위키피디아와 bookcorpus 를 이용해 학습
- 대량의 텍스트 데이터에 대해 semi-supervised 를 진행해 언어의 패턴을 학습한다.
✔ Input : Sentence Pair encoding
◽ Token embedding : Word piece embedding 단어 단위의 임베딩
◽ Segment Embedding : Next sentence prediction 을 위한 부분
◽ Position Embedding : 단어 위치에 대한 정보 인코딩

✔ MLM , NSP

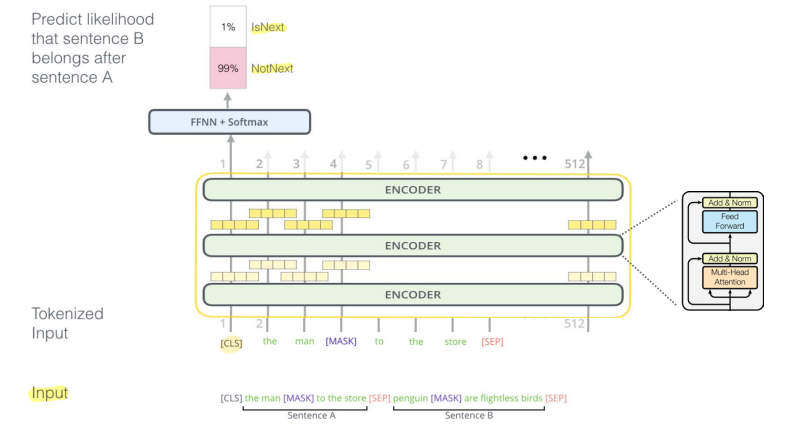
◽ Masked Language Modeling : 전체 단어의 15%를 선택한 후 그 중 80%는 [MASK], 10% 는 현재 단어 유지, 10%는 임의의 단어로 대체한다.
◽ Next Sentence Prediction : [CLS] 토큰으로 문장 A와 문장 B의 관계를 예측하는 것으로 A 다음 문장이 B 이면 True, A 다음 문장이 B 가 아니면 False 로 예측
✔ Fine-tuning
◽ Pre-trained model 위에 task 에 맞는 분류기를 붙여 학습을 진행
✔ 완전 양방향 모델
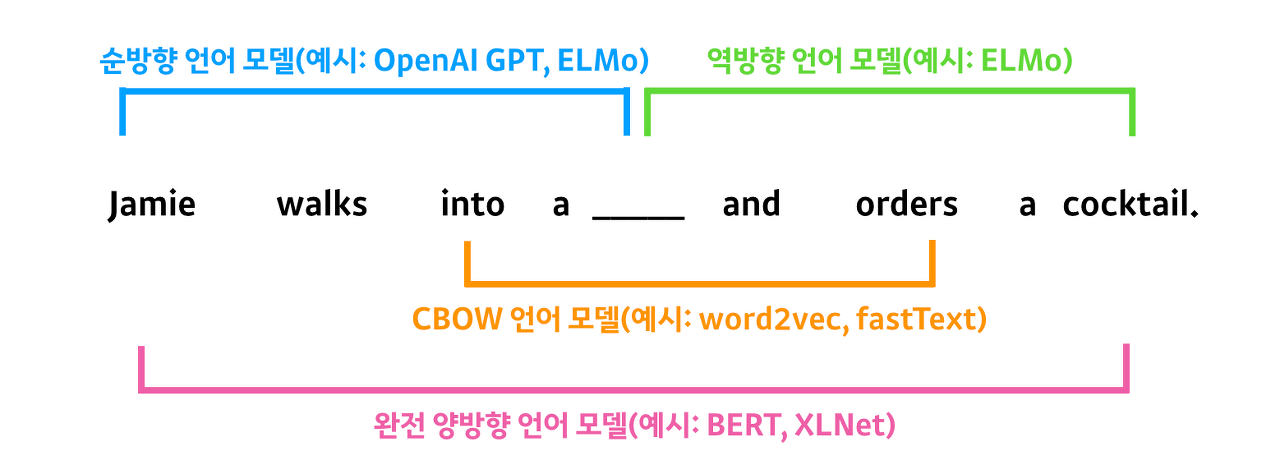
👉 BERT 는 MLM 을 통해 단어 앞뒤 시퀀스를 동시에 보는 완벽한 양방향 모델을 구축했다.
👉 MLM 으로 모든 문맥을 한 번에 고려하고, NSP 를 통해 문장 간 관계를 학습한다.
✔ Result
◽ GLUE task

◽ NER task

◽ SQuAD 1.1/2.0

◽ Model size
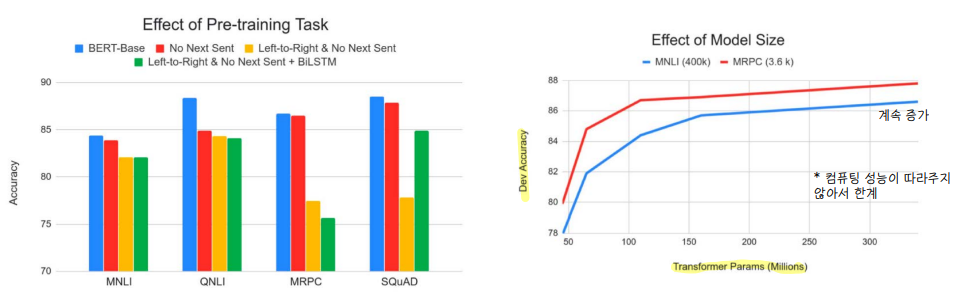
4. KoBERT
✔ 신문기사/백과사전 등 23GB 의 데이터를 이용해 학습
◽ BERT-base 와 동일한 구조


'1️⃣ AI•DS > 📗 NLP' 카테고리의 다른 글
| [cs224n] 18강 내용정리 (1) | 2022.07.18 |
|---|---|
| [cs224n] 15강 내용정리 (0) | 2022.07.04 |
| NER 실습 (0) | 2022.06.02 |
| Glove 실습 (0) | 2022.05.31 |
| [cs224n] 12강 내용정리 (2) | 2022.05.23 |




댓글