Summary
✨ Federated learning
◾ Exploits huge amount of data across clients
◾ data is non-IID
◾ Brief indroduction of FedAvg
✨ Distributed learning
◾ Make training Faster
◾ Data evenly distributed
◾ data parallel : Forward pass, Backward pass , Weight update
👉 Communication : Allreduce - ring reduction, One-host reduction
◾ Model parallel
👉 inter-layer parallel (pipeline) : sub-minibatches, interleaved layers
👉 intra-layer parallel : row-wise partitioning , column-wise partitioning , Alternating partitioning
1️⃣ Federated learning
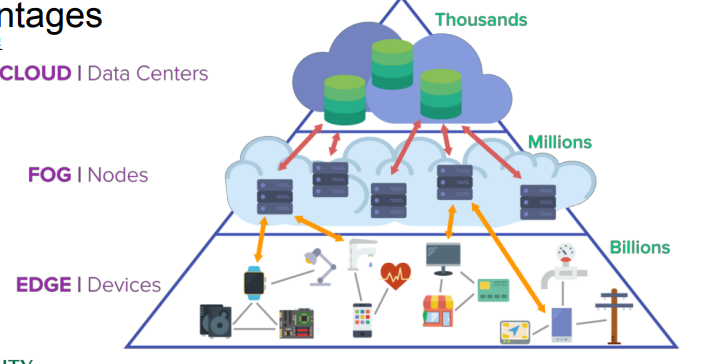
① Decentralized data
🔘 Data is born at the Edge
◾ 데이터는 edge 에서 생산된다.
◾ 수많은 스마트폰과 IoT 기기로부터 데이터가 계속 생산된다.
◾ 데이터로부터 학습을 진행하여 양질의 서비스를 만든다.

🔘 탈중앙화된 data
👀 Centralized dataset processed in integrated system
◾ 머신러닝의 표준적인 환경은 중앙화된 데이터셋이 있고 그것을 긴밀하게 연결된 대규모 서버로 학습하게 된다.
👀 Often decentralized
◾ 실세계에서는 데이터는 일반적으로 IoT 기기, 여러 기관 등 다양한 곳에서 생산되기 때문에 데이터가 분산화 되어 있는 경우가 많다.

🔘 중앙화된 data 방식의 한계점
👀 Sending the data is too costly
◾ edge device 로부터 중앙 서버로까지 데이터를 보내는 과정 자체가 매우 많은 비용을 소모한다.
◾ 자율주행 자동차는 하루에 Tera byte 단위의 데이터를 매일 생산하는데, 이렇게 큰 단위의 데이터를 네트워크를 통해 서버로 보내는 과정을 수반해야 하면 매우 오랜 시간 + 에너지 + 전력소모가 발생한다.
◾ 무선 기기들은 bandwidth 나 power 가 제한되어 있기 때문에 네트워크로 데이터를 보내는데 비용이 많이 든다.
👀 Data may be considered too sensitive : privacy
◾ 데이터 사생활 문제에 대한 규제/우려지점 : 분산화된 데이터를 가지고 있으면 각 소유자가 데이터를 소유하고 있는데 반하여, 중앙서버로 데이터를 보내는 순간, 데이터의 소유가 불명확해지며 데이터가 분실될 수도 있음
◾ 현대에는 데이터가 곧 권력이기 때문에 데이터를 가지고 있는 것이 비즈니스나 연구를 하는데 있어 경쟁력을 불어일으키게 된다. 때문에 데이터를 중앙 서버로 보낸다는 것은 데이터를 빼앗기는 것과 같다. 다른 party 에게 데이터를 전송하는 격이기 때문에 데이터 소유 측면에서 경쟁력을 잃게 된다.
② On Device
🔘 Data processing
👀 edge computing
◾ 디바이스에 분산화된 데이터 형식으로 바뀌고 있고, 데이터를 처리하는 것조차 서버에서 처리하는 것이 아닌, 디바이스 단에서 처리하는 것으로 바뀌고 있다.
👀 장점
◾ Improved latency : 속도 지연에 개선을 가져온다 → edge 에서 바로 데이터를 처리하므로 속도가 빠름
◾ Works offline : 네트워크에 연결되어 있지 않아도 오프라인에서 동작할 수 있게 된다.
◾ Better battery life : 배터리 소모량을 줄일 수 있게 된다.
◾ Privacy advantages : 데이터를 서버로 보내지 않아도 되므로 전송 중간에 데이터가 갈취되거나 중앙 서버가 해킹될 걱정이 없음 (다른 사람과 데이터를 공유하지 않기 때문에 보안유지가 가능함)
🔘 On-Device Training
◾ 디바이스에서 학습을 진행 : Perform ML learning on devices with its own data
👀 단점
◾ local dataset may be too small : 디바이스에서 수집된 데이터의 크기가 작기 때문에 오버피팅이 일어날 가능성이 높아 예측 성능이 좋지 않을 수 있다.
◾ local dataset may be biased : local dataset 이 편향되어 training 하고자 하는 target distribution 을 대변하지 않는 데이터셋일 수 있다.
👀 personalization
◾ 위와같은 단점을 때문에 on-device training 은 주로 개인화에 많이 사용된다.
👉 ex. 손글씨 인식 어플 : device 단에서 개인의 손글씨 데이터를 축적하고 서버에서 사전 훈련된 모델을 가져와 fine tuning 하는 과정을 통해 유저 손글씨에 인식률을 높인 서비스를 제공할 수 있다.
③ Federated learning
🔘 Federated learning
👀 collaboratively train a ML model while keeping the data decentralized
◾ 데이터가 분산 저장 되어 있을 때 머신러닝 모델을 연합해서 같이 훈련 하는 방식
◾ 이상적으로는, 최종 모델이 on-device 훈련으로 얻어진 모델보다 더 좋은 성능으로 혹은 중앙화된 서버에서 훈련한 모델과 비슷한 결과를 얻게끔 하는 것
👀 학습 과정
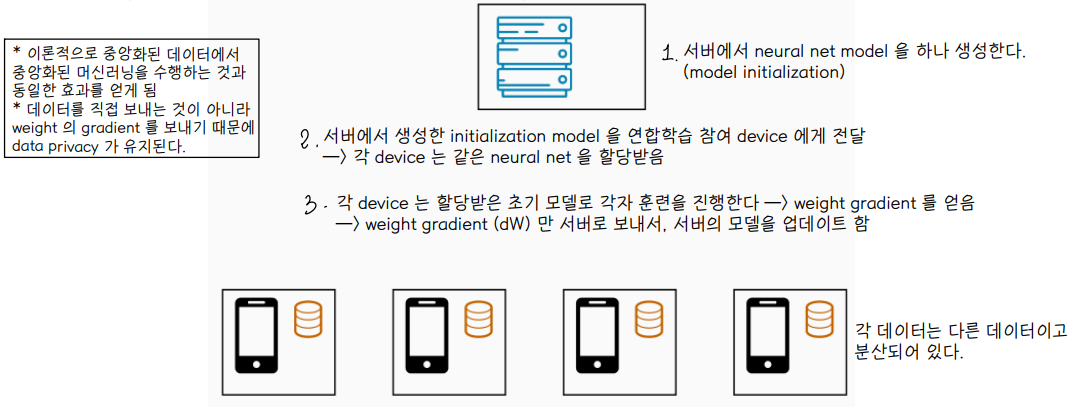
1. Model initialization : 서버에서 neural network model 을 생성한다.
2. 서버에서 생성한 초기 모델을 연합학습에 참여하는 device 에게 전달한다.
👉 각 device 는 동일한 neural network model 을 할당받음
3. 각 device 는 할당받은 초기 모델로 각자 훈련을 진행한다.
4. 각 device 에서 훈련을 통해 얻은 weight gradient (dW) 들만 서버로 보내서 서버의 모델을 업데이트 한다.
⭐ 데이터를 직접 보내는 것이 아니라 weight gradient 를 보내기 때문에 data privacy 가 유지된다.
🔘 특징
1. 데이터는 local 에서 생성된며 데이터는 서버에 모이지 않고, 분산화된 채로 존재한다.
2. 각 client (device) 가 본인의 데이터를 가지고 있고, 다른 client 의 데이터에 접근할 수 없다.
👉 privacy 가 보존된다.
3. client 는 weight gradient 값만 서버로 보낸다.
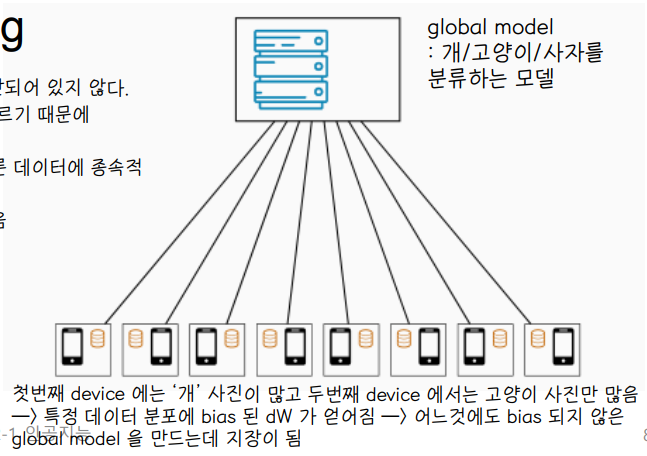
4. Data 는 non-IID 특징을 가진다 : 데이터가 비 독립적이고 동일하게 분산되어 있지 않다.
→ not identically distributed
: data distribution 이 client data 마다 다르기 때문에 학습이 전혀 다른 양상으로 이루어짐
→ not independently
: 데이터가 비독립적이다라는 것은 한 데이터가 다른 데이터에 종속적 일 수 있다는 것
⭐ 이러한 특징으로 인해 연합학습은 global 하게 최적화된 모델을 만들기 어렵다. 따라서 연합학습 연구의 최신 흐름은 non-IID 상황에서도 훈련이 global 하게 이루어지도록 하는 것에 집중되어 있다.
5. 연합학습의 baseline 알고리즘 : FedAvg
④ FedAvg
👉 FedAvg 는 strong non-IID에서 잘 동작하지 않는다.
👉 FedAvg가 최초의 연합학습 알고리즘이라 non-IID 동작 여부가 불안정하다.
🔘 Notations
◾ K clients
◾ Each client k holds dataset Dk of nk samples
◾ D : joint dataset
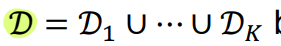
◾ n : total number of samples
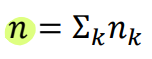
👀 loss 를 최소화하는 파라미터 θ 를 찾기
👉 F(θ ; D) : loss function

👉 즉, 각 client 가 각각의 데이터셋으로 학습을 수행할 것이고, 그것을 평균한 것이 최종 loss function이 된다. 이 loss function 을 최소화하는 것이 목표!
🔘 Local SGD

⭐ Client sampling rate ρ
⭐ ClientUpdate : 병렬적으로 weight update 를 수행
⭐ Local step L, Batch size B
💨 classic parallel SGD

💨 local SGD

→ local SGD 로 훈련하는 것이 IID data 형태로 수렴한다는 것이 증명되어있다
👀 Federated learning VS Distributed learning
① Federated learning
◾ 실용화 단계까지 가지 못함
◾ client 로 분산화된 데이터를 활용하는 것이 주 목표
◾ 데이터가 본질적으로 분산되어있고 국지적으로 생산된다.
◾ data 가 non-IID 성질을 가지며 불균형하게 분포한다.
◾ privacy 를 강화한다.
◾ limited reliability/availability : 각 참여자의 제한된 reliability 를 고려해야 한다. 연합학습을 하면서 특정 client 가 offline 이 되거나, 네트워크가 불안정해질 수 있다는 상황도 고려해야 한다는 뜻!
◾ robustness against malicious clients : 악의적인 client 에 대응하여 잘 동작해야 한다.
② Distributed learning
◾ 주된 목표 : 학습을 분산해서 처리하겠다 (데이터 관점에서의 분산이 아님) 👉 학습을 여러 컴퓨터로 분산해서 수행 👉 병렬성을 이용해 더 빠른 학습을 하도록 함
◾ client (worker) 들이 데이터를 직접 분산시켜줌
◾ 일반적으로 랜덤하게 uniform 분포를 가지고 분산된다.
4️⃣ Distributed learning
① Parallelism Taxonomy
🔘 병렬 학습의 종류
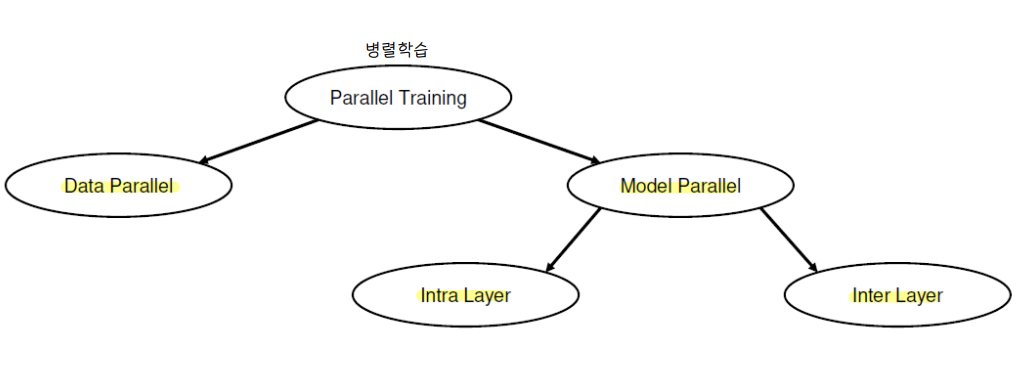
🔘 학습 과정에서의 연산 단계
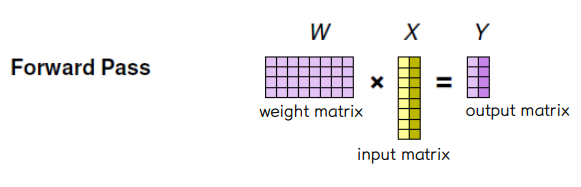
💨 Forward pass : W•X = Y
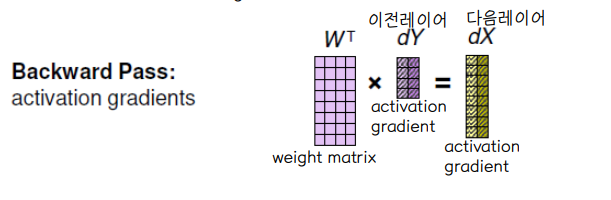
💨 Backward pass (weight gradients) : dY•X' = dW

💨 Backward pass (activation gradients) : W'•dY = dX
💨 Weight update

② Data parallel
🔘 연산개요
👀 Each worker
◾ 전체 entire neural network model 의 복사본을 가지고 있다.
◾ 전체 neural network 을 통해 data 의 일부를 계산하게 된다 → training minibatch
👀 Forward pass
◾ 각 worker 가 각자 담당한 미니배치 데이터셋 만큼의 output activation 을 계산한다.
⭐ No communication is needed
👀 Backward pass
◾ 각 worker 가 각자 담당한 미니배치 데이터셋 만큼의 activation gradient 을 계산한다.
⭐ communication is needed
: Computes contribution to the weight gradient based on its portion of minibatch → weight gradient 는 (미니배치에 대해 업데이트 하지 않고) 전체 batch 에 대해서 업데이트를 해주기 때문에자기가 맡은 부분의 gradient 값을 전체 모델에 공유한다.
👀 Weight update
◾ Each worker updates its copy of the model with combined gradients → 각 worker 가 가지고 있는 모델에 대해 전체 weight 업데이트를 시켜줌
🔘 Multi-GPU
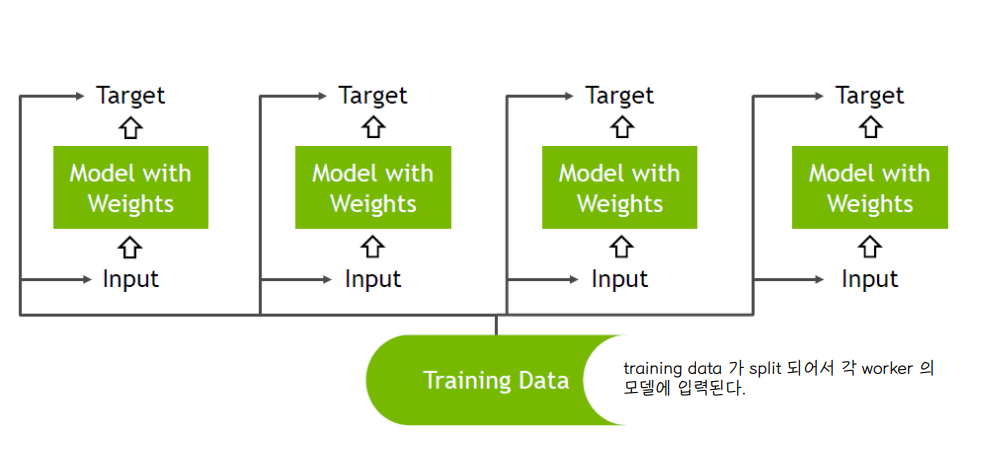
◾ 각 GPU 는 model 의 복사본을 가지고 있다.
🔘 Forward Pass

◾ 각 worker 는 동일한 weight matrix W 를 가지고 나눠받은 input X 의 일부분을 가지고 output activation Y 를 구한다.
◾ 각 worker 에 대해 output 만 계산하면 되므로 worker 들 사이에 communication 은 필요하지 않다.
🔘 Backward Pass
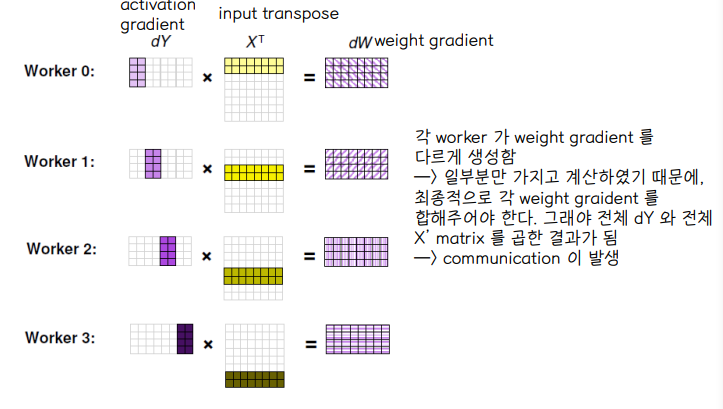
◾ 각 worker 는 서로 다른 weight gradient dW 를 계산하게 된다.
◾ 각 worker 는 entire model 구조를 가지고 있기 때문에 entire weight update 를 위해서는 각자 연산한 dW 를 공유해야 한다. 따라서 worker 사이에 communication 이 발생한다.
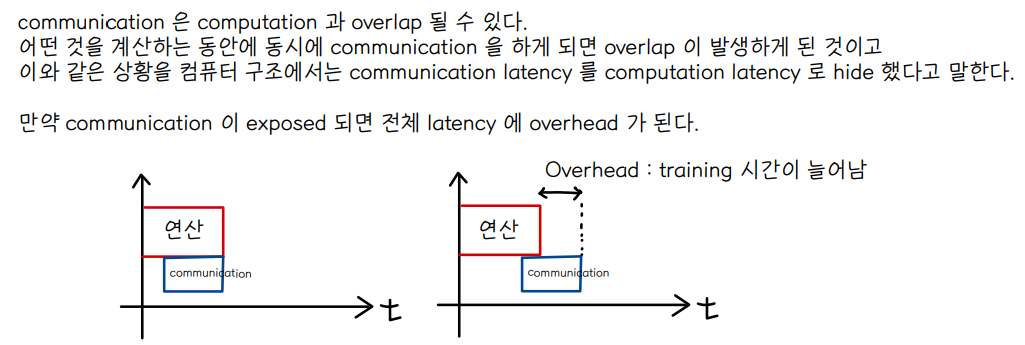
🔘 Communication
👀 communication 을 잘할수록 속도가 빨라진다.
👀 communication 을 어떻게 하느냐에 따라 data parallel 의 effciency 가 달라진다.
⭐ Allreduce
◾ Sum : 각 worker 들의 gradient 값을 모두 더해준다.
◾ Distribute : 더해진 gradient 를 각 worker 에게 분배시킨다.
◾ After Allreduce : allreduce 가 끝나면 각 worker 는 동일한 global gradient 값을 가지게 됨 → 각 worker 들이 다음 step 의 훈련을 하기 위해선 같은 copy 의 weight 를 가지고 있어야함
◾ dW를 먼저 계산하고 서로 공유하는 과정이 이루어지기 때문에 communication overhead 가 불가피하게 발생한다
🔘 Allreduce
👀 Allreduce = reduce + broadcast
◾ reduce = (N-1) 개의 주변 worker 로부터 1/N 만큼의 gradient 들을 받아 모두 더한다.
◾ broadcast = 더해진 값을 다시 (N-1) 개의 주변 worker 들에게 분배시킨다.
◾ reduce 와 broadcast 를 어떤 방식으로 하느냐에 따라 2개로 나뉜다.
👀 Ring reduction
◾ ring 형태의 topology 를 가진 경우
◾ 각 worker 가 양옆의 2개의 이웃과 통신함
◾ 총 2(N-1) 단계가 소요되고, 각 worker 는 총 데이터의 1/N 만큼의 양을 보내거나 받는다.
👀 One-shot reduction
◾ fully-connected 형태의 topology 를 가진 경우
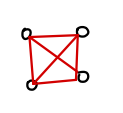
◾ 각 worker 는 서로 한번씩 연결되어 있는 형태이기 때문에 (N-1) 개의 이웃 worker 들과 통신하게 된다
◾ 각 worker 기준으로, 주변 worker 들로부터 받고, worker 들에게 전달하는 총 2 단계의 과정이 소요된다 (each with (N-1) substeps)
🔘 Rring allreduce example
◾ weight gradient 를 ring tolopgy 에서 공유하는 과정
👀 Reduce
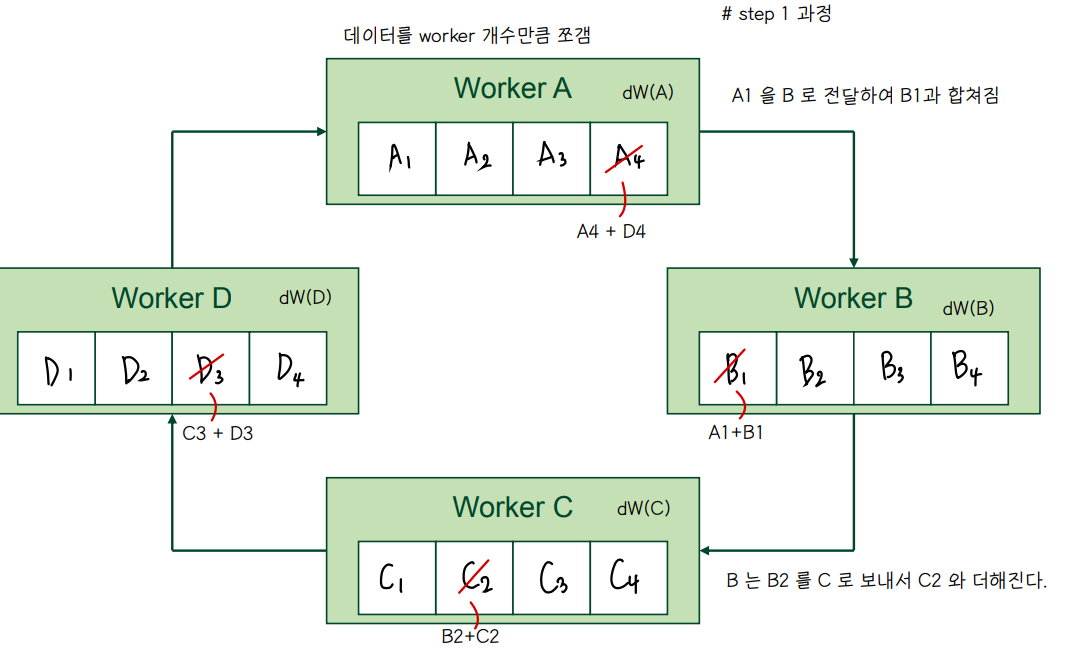
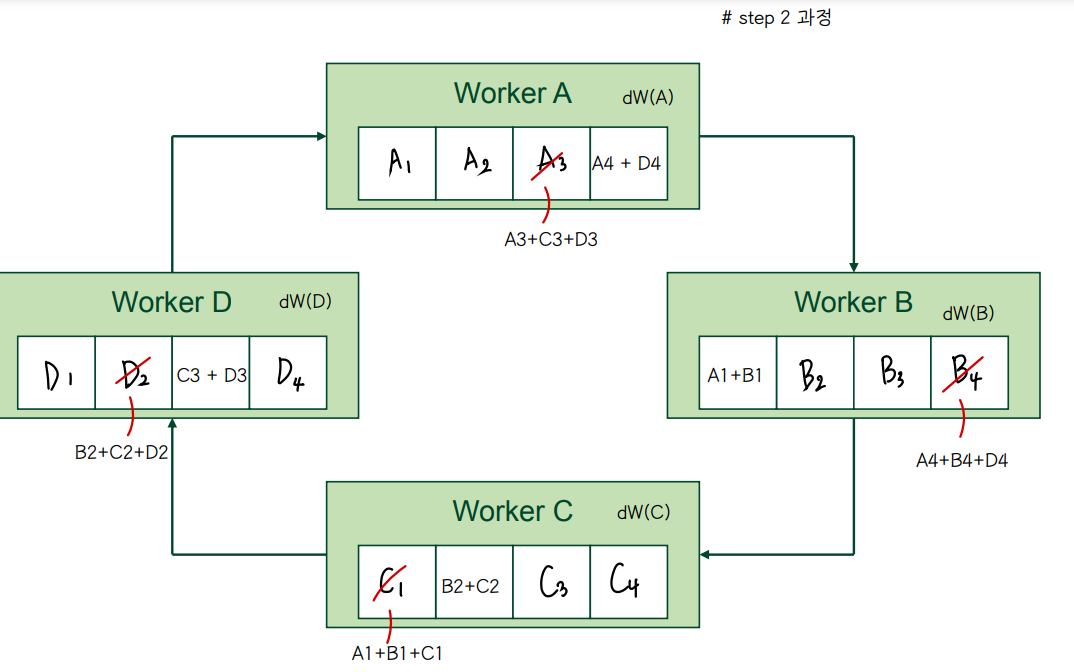
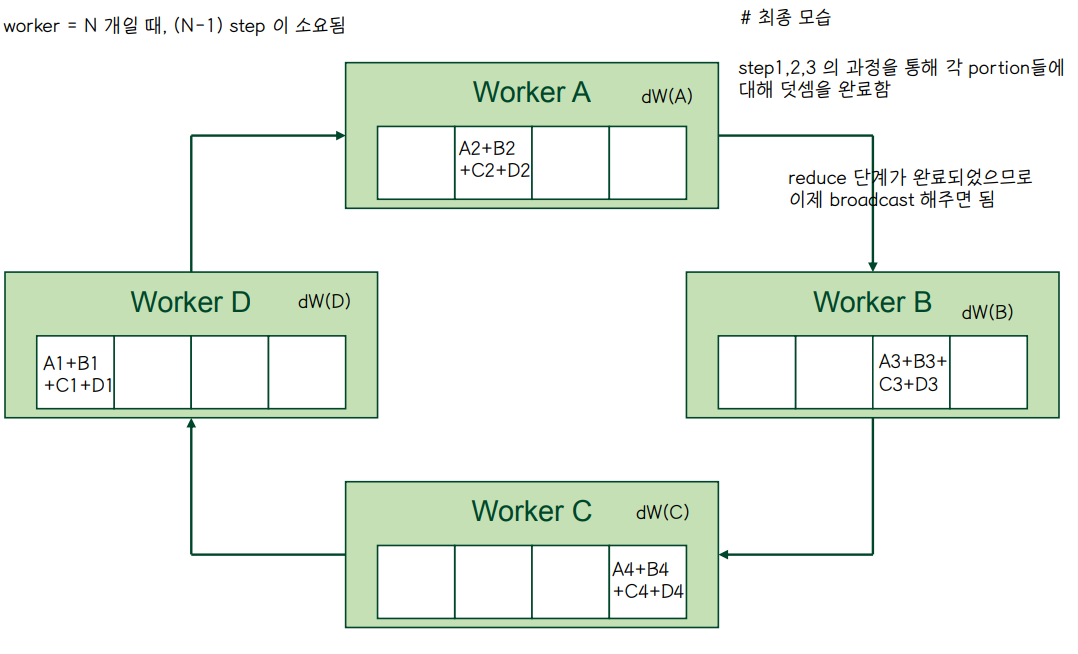
👀 Broadcast
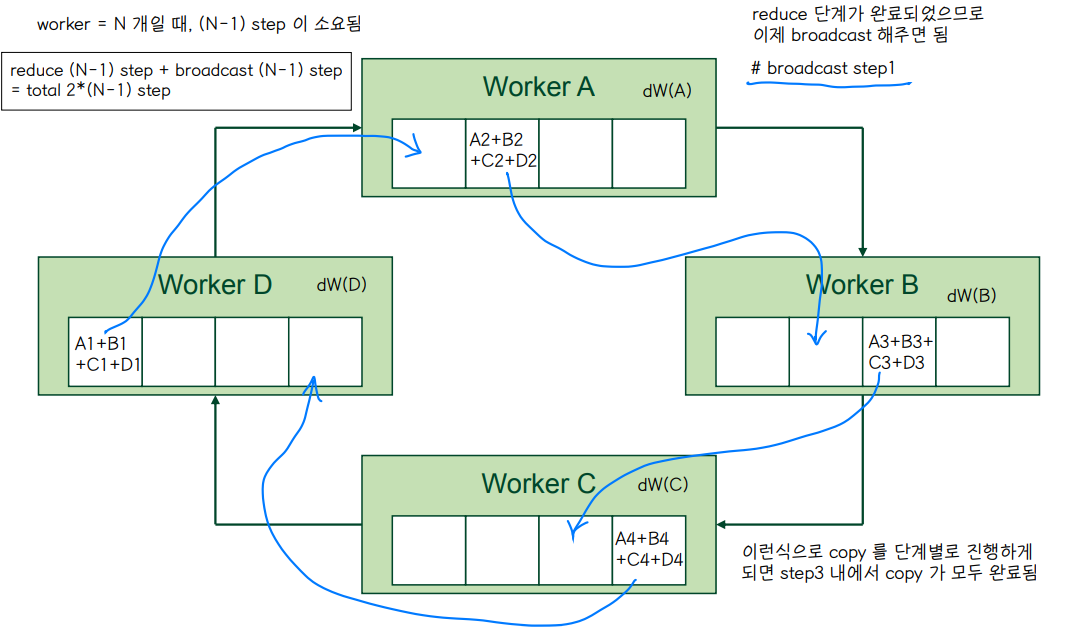
👉 2*(N-1) = 2*3 = 6 단계가 소요됨
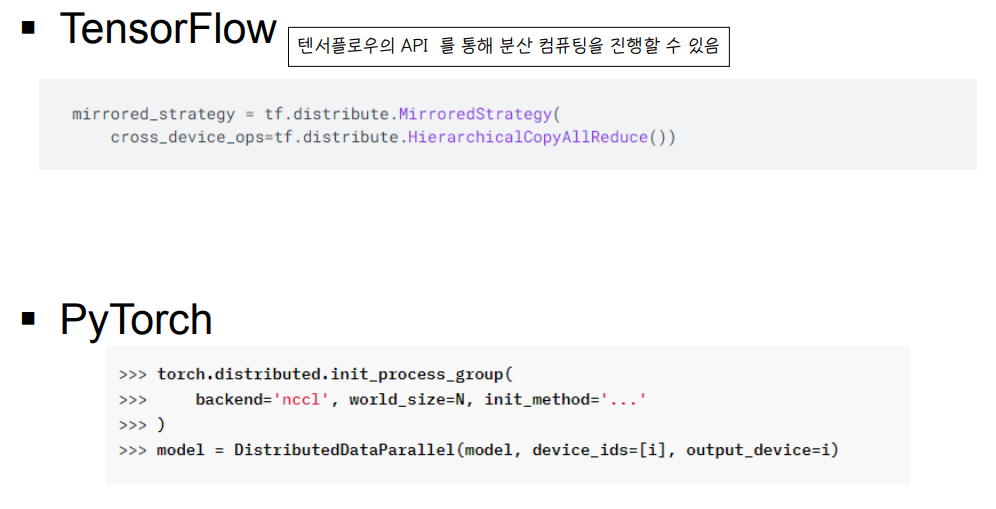
🔘 API
◾ API 를 통해 분산 컴퓨팅을 진행할 수 있다.
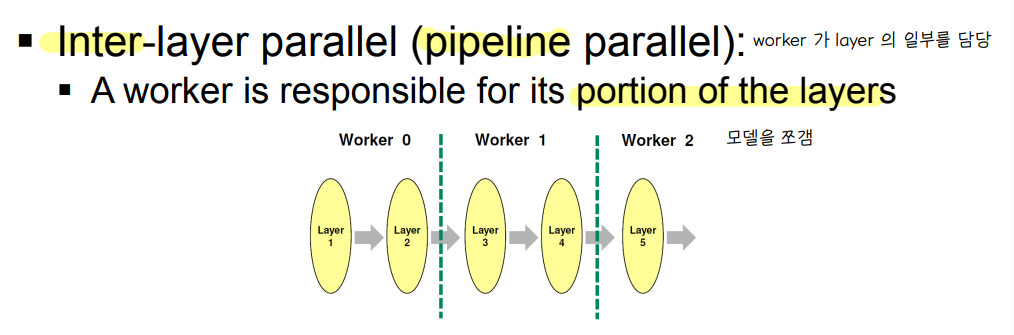
③ Model parallel
🔘 model parallel
💨 Inter layer parallel = pipeline parallel
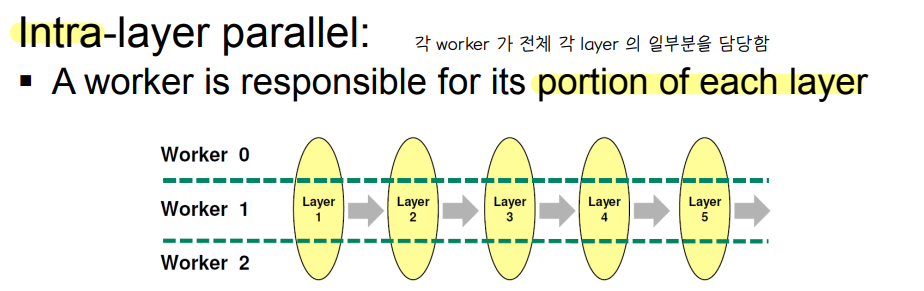
💨 Intra layer parallel
🔘 Pipeline parallel
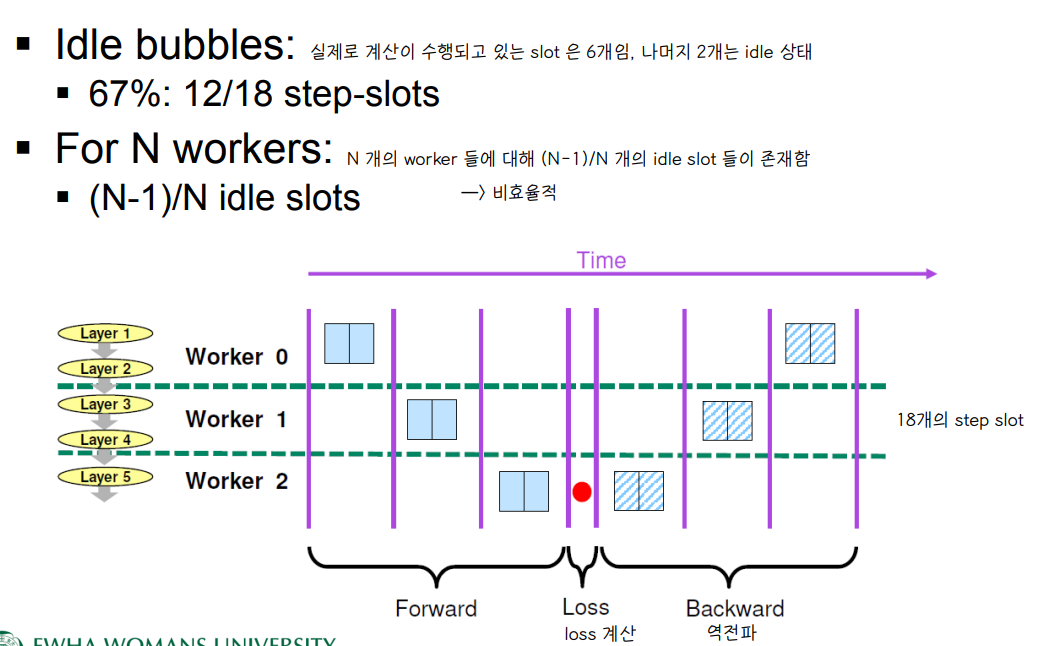
💨 Idle bubbles
📌 N 개의 worker 들에 대해 (N-1)/N 비율 만큼의 idle slot 이 존재함 → 비효율적
💨 Sub-minibatches
📌 비효율성을 줄이기 위해 하나의 minibatch 를 k개의 subminibatch 로 나눈다
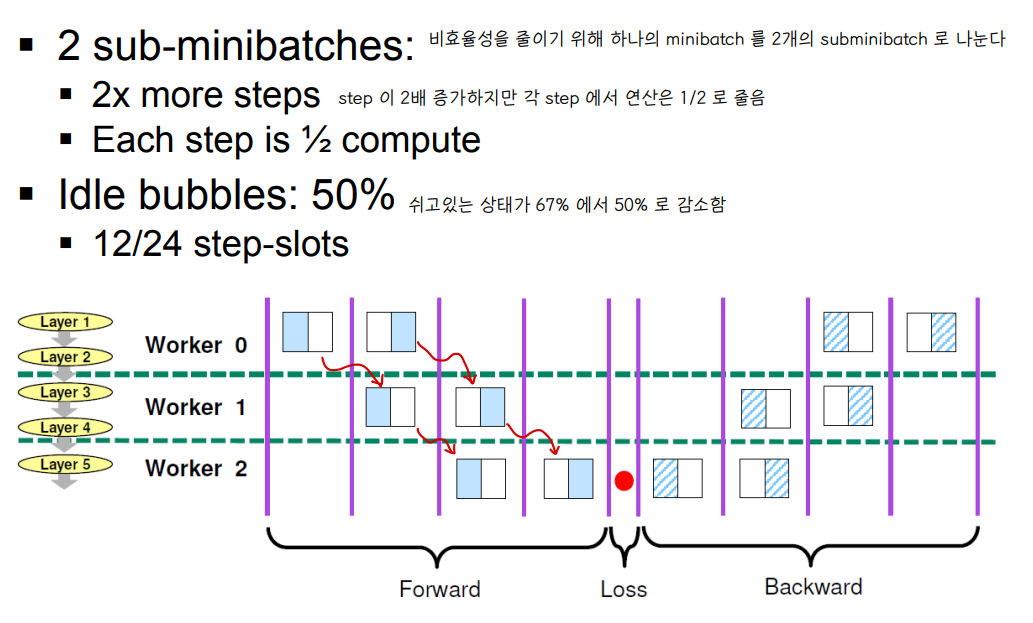
📌 N 이 커질수록 idel slot 의 개수가 줄어든다

💨 Interleaved Layers
📌 각 worker 가 layer 를 불연속적으로 담당하여 훈련한다.
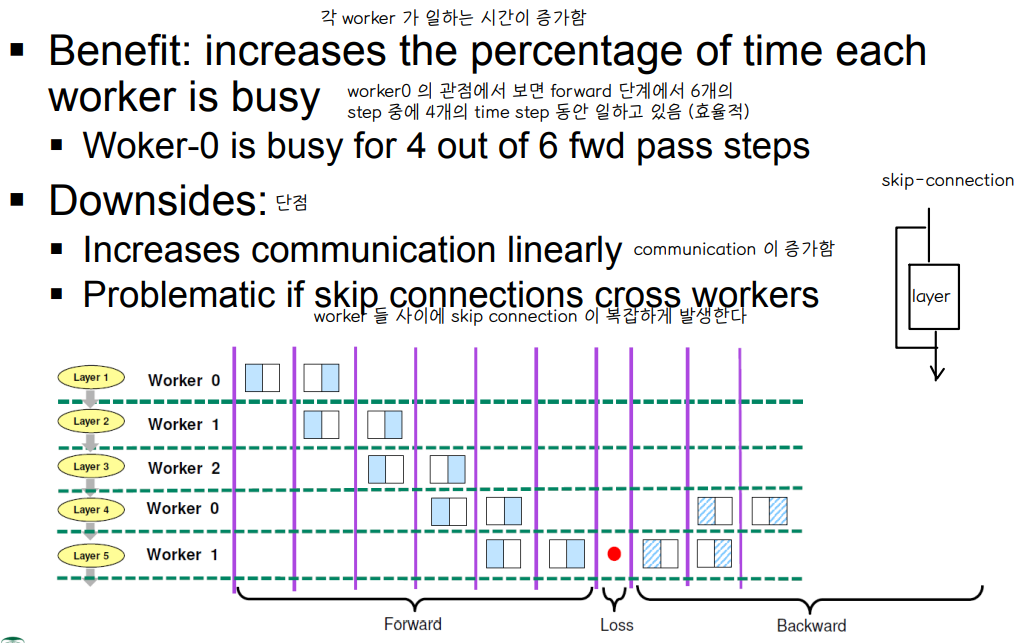
◾ 장점 : worker 가 일하는 시간이 증가한다.
👉 worker0 의 관점에서 보면 forward 단계에서 6개의 step 중에 4개의 time step 동안 일하고 있음 (효율적)
◾ 단점
👉 communication 횟수가 증가함 : worker 가 여러 layer 를 연속적으로 담당하여 훈련을 진행하는 것이 아니기 때문에, weight gradient 의 전달 횟수가 증가하게 된다.
👉 skip connection cross worker 이 복잡하게 발생한다 : worker0 이 가진 결과를 worker2 와 결합하는 과정에서 worker1 을 건너 뛰고 값을 전달해야하는데 이 과정에서 발생하는 communication 이 복잡하다.
💨 Communication in Inter-layer parellel
◾ 2개의 neighbor 와 통신 → worker1 을 기준으로 worker0 으로부터 데이터를 받고, worker2 에게 데이터를 전달하는 과정
◾ forward 와 backward step 마다 communication 이 발생함
◾ forward 에서는 activation 을 넘겨주고 backward 에서는 activation gradient 를 넘겨줌
◾ 연산과 통신을 overlap 시키는 것이 매우 어렵다. 연산이 끝나야만 통신이 가능한 구조이므로 통신부분이 온전히 overhead 로 작용하게 된다.
🔘 Intra layer parallel
◾ layer weight 를 worker 간에 잘라서 수행함
◾ idle slot , load imbalance 문제를 해결할 수 있다.
💨 weight matrix 를 어떻게 나누어 담당하는지 따라 2개로 나뉜다.
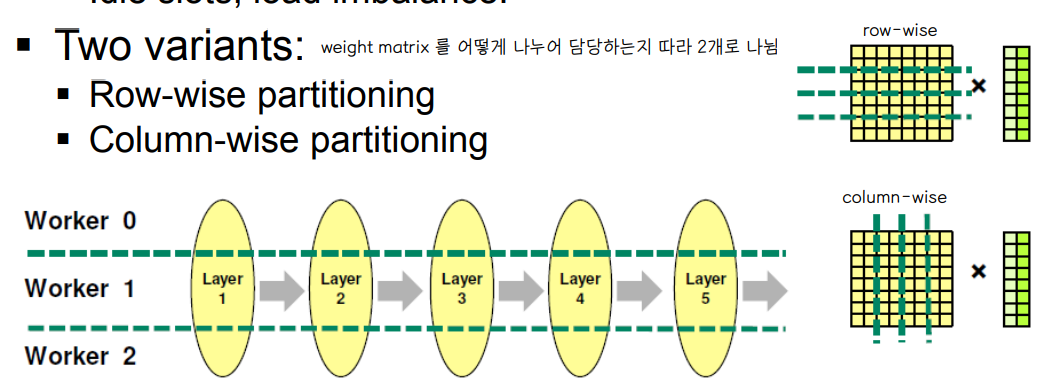
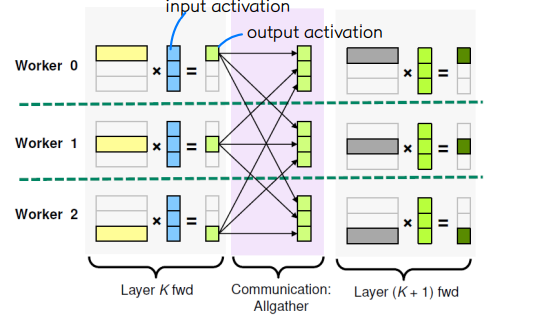
💨 Row-Wise partitioning
📌 각 worker 가 weight 의 일부 행 부분과, 모든 input activation 을 가지고 연산을 수행하여 output activation 값을 도출한다.
📌 forward communication : Allgather → 다음 layer 에서 필요한 activation 형태를 위해 모두 더함
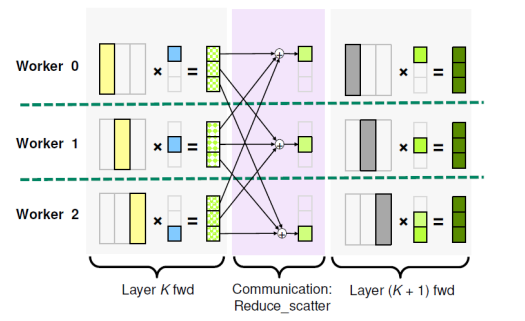
💨 Column-Wise partitioning
📌 각 worker 가 weight 의 일부 칼럼 부분과, input activation 의 일부분을 가지고 연산을 수행하여 partial activation 값을 도출한다.
📌 forward communication : Reduce_scatter → 각 worker 의 output 에 대해 각 위치에 맞게 값을 더해 partial activation 을 얻는다.
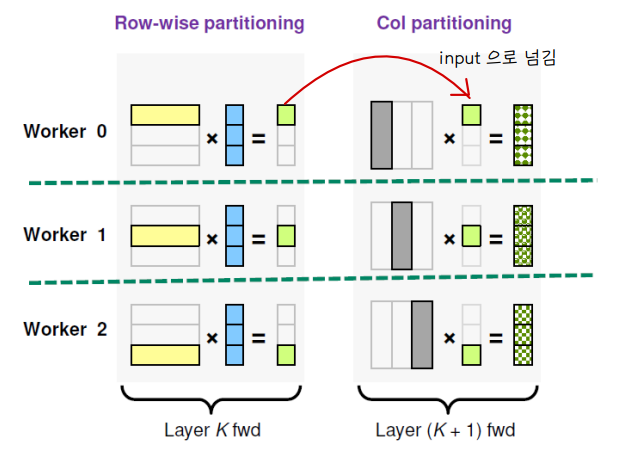
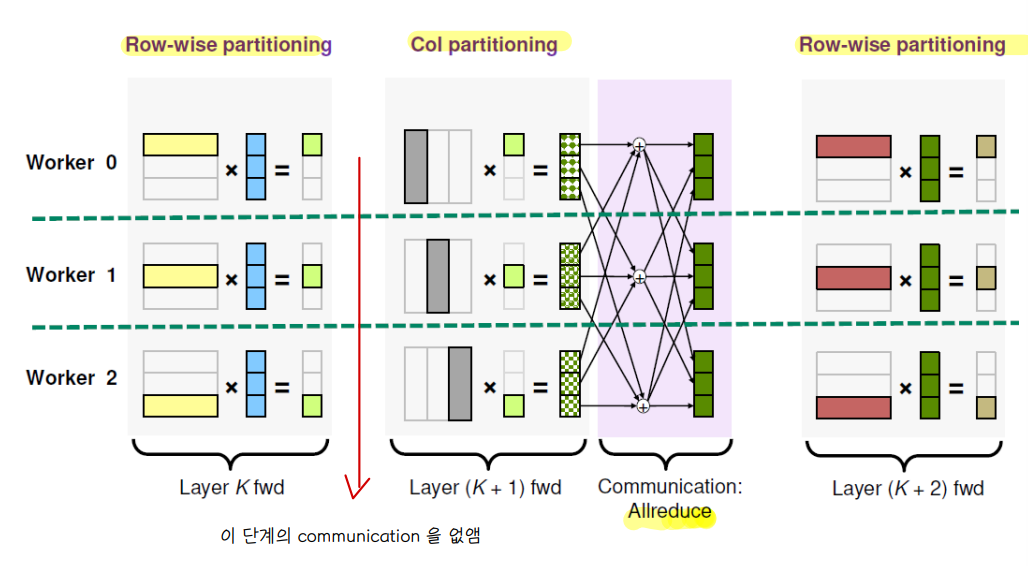
💨 Alternating partitioning
📌 row-wise 와 column wise 를 번갈아 사용하면 communication 과정이 필요 없음
📌 단, col 에서 row 로 다시 넘어갈 땐 Allreduce 과정이 필요
④ Communication pattern summary
🔘 Data parallel
- Allreduce of weights
- Can be overlapped with computation (overhead 를 조금이라도 줄일 수 있다)
🔘 model Inter parallel
- Point-wise communication : 서로다른 neighbor 와 1:1 communication 이 발생
- Hard to overlap with computation (overhead 가 불가결하게 발생)
- Hard to load-balance (어떤 worker 는 더 많은 일을 하게 됨)
🔘 model Intra parallel
- Allgather, reduce_scatter of activations and activation gradients
- row wise 와 col wise 를 동시에 번갈아 사용하면 Allreduce 가 발생
- Hard to overlap with computation
👉 model parallel 은 overlap이 어렵기 때문에 주로 초거대 AI 인 경우에만 사용한다.
'1️⃣ AI•DS > 📒 Deep learning' 카테고리의 다른 글
| [Pytorch 딥러닝 입문] 파이토치 기초 (0) | 2022.09.14 |
|---|---|
| [인공지능] 딥러닝 모델 경량화 (0) | 2022.06.21 |
| [인공지능] Meta learning , Transfer learning (0) | 2022.06.14 |
| [인공지능] Reinforcement Learning (0) | 2022.06.14 |
| [인공지능] GNN (0) | 2022.06.14 |




댓글