Summary
✨ Reinforcement Learning
◾ Any algorithms that solves MDP
◾ Learning to choose optimal action A → ㅠ*
◾ By learning evaluation functions like V(S), Q(S,A)
✨ Key
✔ next state function 을 알고있다면
◾ use dynamic programming to learn ܸV(S)
◾ once learned, choose action At that maximizes V(S_t+1)
✔ 미로 찾기처럼 next state function 을 모른다면
◾ Learn Q(St, At) = E[ V(S_t+1) ]
◾ 학습하기 위해 St x At → S_t+1 을 시도
◾ once learned, choose action At that maximizes Q(St, At)
👀 강화학습과 딥러닝은 별개의 학문이며 강화학습을 사용하는데에 딥러닝을 활용하기도 한다.
👀 강화학습은 머신러닝 분야 중 빼놓을 수 없는 중요한 분야!
1️⃣ Reinforcement Learning
① Reinforcement Learning
🔘 정의
보상을 최대화하기 위해 일련의 행동들을 어떻게 취해야할지 시행착오를 거쳐 학습을 진행

🔘 응용
◾ 벽돌깨기 게임
◾ 로봇

② Markov Decision Process
🔘 MDP
◾ S : Set of states
◾ A : Set of Actions
◾ 각 time 마다 agent 는 state 를 관찰하고 action 을 선택한다.

- Agent 는 enviroment 로 부터 state 를 관측한다.
- 관측된 결과로부터 action 을 취한다.
- action 을 취한 대가로 reward 보상을 받는다.
- state 는 다음 step 의 state 로 바뀐다.
⭐ Markov assumption
◾ 다음 state 는 현재와 과거에 있었던 모든 state 와 action 에 영향을 받겠지만 마르코프 가정은, 미래의 state 가 현재의 state 에만 의존되어 있다는 것

⭐ reward Markov
◾ 보상도 원래는 현재와 과거의 모든 state 와 action 에 영향을 받겠지만,마르코프 가정에서는 현재 보상은 현재의 state 와 action에만 의존적이라는 것! (과거와는 상관 없음)

⭐ Task : learn a policy ㅠ : S→A for choosing actions that maximizes

◾ 어떤 state 집합으로부터 어떤 action 을 취할 것인지에 대해 정의한 policy 를 학습한다. policy 만 정해주면 일련의 state 로부터 일련의 action 들을 결정할 수 있다.
◾ 일련의 action 들이 보상을 최대화하도록 정책을 학습하게 된다.
◾ ϒ : discount factor → 현재 시점에 가까운 보상에 가중치를 더 크게 부여하여 시간에 대한 간격을 반영하기 위해 reward 에 곱해지는 요소로 미래에 대한 reward 를 감소시키는 역할이다.
🔘 Example
◾ 벽돌깨기 게임

- 강화학습은 MDP 문제를 푸는 모든 알고리즘을 칭한다.
🔘 강화학습
⭐ Any alogithms that solve Markov Decision Process - 마르코프 결정과정을 푸는 알고리즘
⭐ reward 를 최대화하는 행동을 취하도록 학습한다.
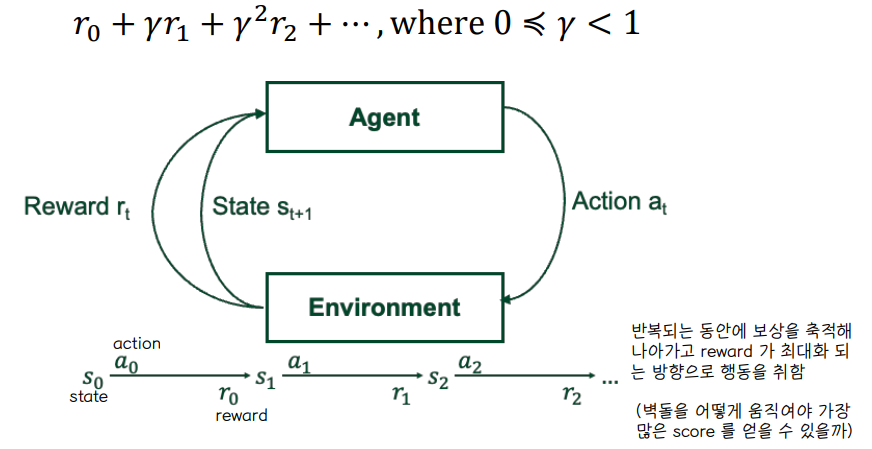
🔘 Task for Autonomous Agent
◾ 모든 state 로부터 environment 상황에서 action 을 실행하여 결과를 관측하고, reward 를 최대화시키는 policy 를 학습해나아간다.

◾ Example : robot grid world, deterministic reward r(s,a) 👉 현재 state 와 action 이 결정되면 보상도 결정되는 구조

◾ policy 는 ㅠ : S→A 형태로 이루어져 있으나, training sample 은 <s,a> 구조로 이루어져있지 않다 👉 training sample 이 (A,right), (B,right) 처럼 이루어져 있지 않다는 소리
◾ 대신 < <s,a>, r > 구조로 이루어져 있다 👉 <s,a> 만 있으면 미리 프로그래밍 된 로봇처럼 학습이 쉬워지겠으나 reward 까지 고려하면서 강화학습이 복잡한 구조를 가지게 된다.
2️⃣ Value function
① Value function for each policy
⭐ 각 policy 에 대해 value function 을 정의한다.
🔘 ㅠ : S → A

◾ 가치함수 : expected reward 를 모두 합한 값
🔘 optimal policy ㅠ*
◾ 가치함수를 최대화 하는 정책

- policy 마다 와 r 이 다르고, 그 중 optimal 한 정책 ㅠ 를 찾아야 함
◾ 마르코프 결정과정에서는 최적화된 정책을 언제든 찾을 수 있다.
◾ V*(S) 와 P(S_t+1 | St, a) 가 주어졌을 때 ㅠ*(S) 를 계산할 수 있다.
- optimal 한 policy 를 따를 때의 가치함수가 있고 state, action 이 주어졌을 때 다음 state 가 무엇인지 알려져 있으면 optimal policy 를 계산할 수 있게 된다.

② V(S)
🔘 임의의 policy 에 대한 계산 예제

- S : start point
③ V*(S)
🔘 optimal policy 에 대한 계산 예제

🔘 Recursive Definition for V*(S)
◾ Value function 에 대해 recursive 한 식을 생성할 수 있다.

◾ 파란색 부분 → s2 에서 시작하는 optimal value function 으로 변환할 수 있다.
🔘 Value Iteration for Learning V*
◾ V* 를 찾기위한 반복문 → dynamic programming

◾ P(s' | s,a) 를 알고 있다고 가정한 상태에서의 반복문임
3️⃣ Q learning
① Q-learning
🔘 실제로는 P(St | S_t-1, a_t-1) 을 모름
◾ 미로찾기처럼 가령 B에서 up 을 하면 A 상태가 된다는 것 자체를 모르는 것
◾ ⭐ 따라서 Q 값을 도입한다.

◾ Q(s,a) 를 알고있다면 P(S_t+1 | St, a) 를 모르더라도 최적의 optimal action 을 선택할 수 있다.


② Getting Q(s,a)
🔘 Q(s,a) 를 얻는 방법 example
◾ r(s,a) 와 V*(S') 가 주어졌을 때

③ Training Rule to Learn Q
🔘 Q 를 학습하는 방법
◾ V* 는 Q 와 밀접한 관계가 있다.

◾ Q hat : 미래의 Q 값을 알 수는 없기 때문에 s 라는 상태에서 action 을 직접 실행해보고 그때의 s' state 로 계산하는 과정에서 trial error 가 발생한다.

④ Q learning for Deterministic Worlds

④ Q hat example
🔘 현재상태 s1에서 s2로 갈 때의 reward 중에서 가장 큰 값을 선택하여 Q hat 값을 업데이트한다.

🔘 Q값은 time step 마다 증가하며 upper bound 로 real Q 를 가지므로, Q 의 추정값은 실제 Q 값으로 수렴하는 구조를 가진다.
⑤ Deep Q-learning
🔘 Q 를 estimate 할 때 딥러닝을 사용한다.

⑥ Reinforcment Learning in AlphaGo
🔘 알파고의 강화학습 구조

◾ P(a|s) 를 통해 policy 를 학습하여 이동한다
◾ 가치함수를 학습하여 현재 판세를 평가한다.
'1️⃣ AI•DS > 📒 딥러닝' 카테고리의 다른 글
| [인공지능] Federated Learning , Distributed Learning (0) | 2022.06.15 |
|---|---|
| [인공지능] Meta learning , Transfer learning (0) | 2022.06.14 |
| [인공지능] GNN (0) | 2022.06.14 |
| [인공지능] 추천시스템 (0) | 2022.06.13 |
| [인공지능] GAN (0) | 2022.06.13 |




댓글