💡 주제 : Seq2Seq , Attention, 기계번역
📌 핵심
- Task : machine translation 기계번역
- Seq2Seq
- Attention
기계번역은 대표적인 Seq2Seq 형태의 활용 예제 중 하나이고, attention 이라는 방법론을 통해 성능이 개선되었다.

1️⃣ Machine Translation
1. 기계번역

✔ 정의
- 입력으로 들어온 Source language 를 target language 형태로 번역하는 Task
✔ 역사
➰ 1950's : The early history of MT
- 러시아어를 영어로 번역하는 등의 군사 목적으로 개발되기 시작하였다.
- Rule-based 의 번역 시스템으로 같은 뜻의 단어를 대체하는 단순한 방식을 사용했다.
➰ 1990s - 2010s : Statistical Machine Translation SMT
- 핵심 아이디어 : parallel 데이터로부터 확률모델을 학습시킨다 👉 서로다른 두 언어의 parallel 데이터로부터 확률 모델을 구축
- 입력문장 x 에 대해 조건부 확률을 최대화 하는 번역문장 y를 찾기

- By Bayes rule 💨 Translation model + Language model

0. Parallel data
- 번역할 문장과 이에 대응되는 번역된 문장 형태의 data pair : 번역이 된 문장쌍
- 가령 인간이 번역한 프랑스어와 영어 문장의 pair 쌍으로 이루어진 데이터를 의미한다.
1. Translation model
- 각 단어와 구가 어떻게 번역되어야 할지를 서로 다른 두 언어로 구성된 parallel data 로부터 학습한다.
- Fidelity 번역 정확도
2. Language model
- 어떻게 하면 좋은 번역문장을 생성할지 모델링한다.
- 가장 그럴듯한 target 문장을 생성하도록 단일 언어 데이터로부터 학습된다.
- fluency 좋은 문장 생성
- Ex. RNN, LSTM, GRU
➰ 2014s~ : Neural Machine Translation NMT
- Single end-to-end neural network model 인공신경망
- 2개의 RNN 으로 구성된 sequence to sequence model 👉 Encoder - Decoder
- 역전파를 활용하였기에 feature engineering 단계가 없고 모든 source-target pair 에 대해 동일한 방법을 적용하여 학습이 가능하다.
- SMT 보다 성능이 뛰어나기 때문에 현재는 대부분 NMT 기반의 번역기를 사용한다.
- 다만 여느 딥러닝 모델처럼 해석력이 부족하고, Rule 이나 guideline 을 적용하기 쉽지 않다는 문제점이 존재한다.
✔ SMT 개요
주어진 방대한 Parallel data 로부터 확률 모델을 구축한다.
- By Bayes rule 💨 Translation model + Language model
🤔 Translation model 을 어떻게 훈련시킬까?

Source-target 문장 간의 correspondence 를 매핑하는 alignment 를 사용한다.
- alignment : source~target 문장에서 일치하는 단어 또는 구를 찾아서 짝을 지어주는 작업

- source 와 target 문장을 단어 단위로 매핑시킬 때 언어별 어순의 차이를 반영하기 위해 매핑된 단어의 배열정보를 담는 alignment 라는 정보를 추가적으로 사용한다.
- 보통 alignment 가 위의 그림처럼 1:1로 명확히 정의할 수 없는 경우가 많다. alignment 를 학습하는 방법이 복잡해지고 여러 학습 알고리즘들이 연구되어 왔다. 👉 EM 알고리즘 같은 학습 방법이 사용된다.
Alignmnet is Complex 👉 기계번역을 수행하는 SMT 모델 성능을 저하시키는 요인이 됨
* 왼쪽이 source, 오른쪽이 target
1. No counterpart

2. Many to one

3. One to many

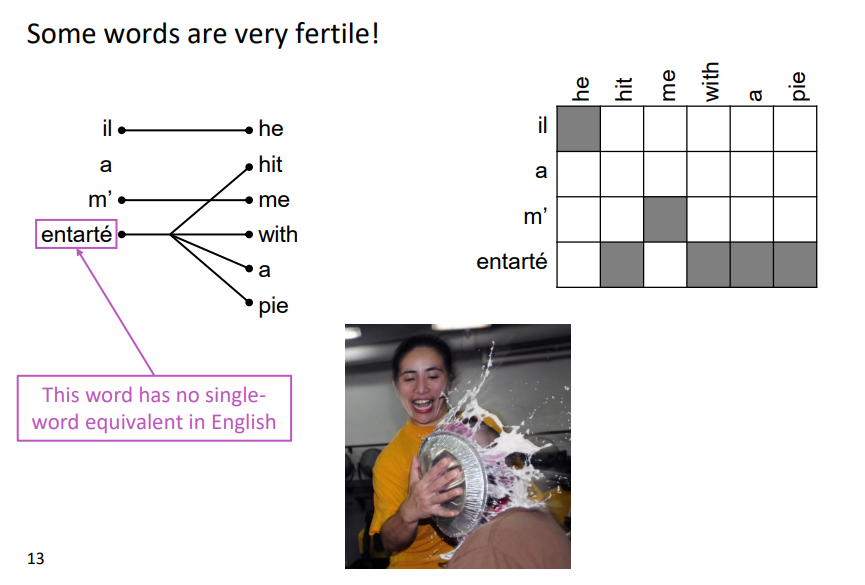
source 의 특정한 하나의 단어가 매우 많은 뜻을 포함하여 상당히 많은 번역 단어와 대응되는 경우 → Very fertile
4. Many to many _ phrase level

many-to-many 형태의 alignment 로 학습이 이루어져야 하기 때문에 복잡함
💨 Translation model 은 단어의 위치, 번역 단어 대응 개수 등을 고려한 다양한 형태의 조합을 학습해야함
- Probability of particular words aligning also depends on position in sent
- Probability of particular words having particular fertility (number of corresponding words)
✔ Decoding for SMT
Decoding 👉 학습한 translation model 과 language model 을 통해 최적의 번역 문장을 생성하는 과정

- 가능한 모든 번역문 y 의 확률을 비교하는 것은 너무 많은 계산량을 필요로 한다.
- Answer : 여러 factor 로 분리하고 각각의 최적해 조합으로 global optimal (가장 적절한 번역문) 을 찾는 Dynamic programming 방식으로 decoding 한다 👉 Heuristic search algorithm
Decoding 과정


✔ SMT 의 단점
- Extremely complex : alignment 같은 많은 하위 시스템 (subcomponents) 으로 전체 시스템을 설계하기 때문에 과정이 복잡하다.
- 성능향상을 위해 특정한 언어 현상을 포착해야하므로 Feature enginnering 이 필요하다.
- 성능을 위해 동일한 의미를 가진 문장어구를 확보하는 등의 추가적인 resource 가 필요하다.
- 모델의 개발 및 유지를 위해 사람의 노력이 많이 필요하다 : paried dataset 구축, subcomponent 의 학습 등
2️⃣ Sequence to Sequence
1. neural Machine Translation

✔ Sequence to Sequence 개요
- 2개의 RNN 으로 구성된 모델
Encoder 💨 source sentence encoding
- source 문장의 context 정보를 요약한다.
- context 요약 정보인 last hidden state 를 decoder 로 전달하여 initial hidden state 로 사용한다.
Decoder 💨 generates target sentence
- encoding 을 condition 으로 target sentence 를 생성하는 conditional language model
- target sentence 특정 단어가 주어졌을 때, 그 다음에 올 단어를 예측하기 때문에 language model 이라 칭할 수 있다.
- source sentence 의 context 요약 정보를 기반으로 target sentence 를 생성한다.
💨 Train : target sentence 의 각 timestep 별 단어가 다음 timestep 의 단어를 예측하기 위한 입력으로 사용된다.
💨 Test : target 문장이 주어지지 않는다고 가정하고, Decoder RNN 의 timestep 별 output 이 다음 timestep 의 입력으로 사용된다.
➕ Teach-Forcing : train 시 decoder 에서 실제 정답 데이터를 사용할 비율을 설정하는 하이퍼 파라미터
- 초기에 잘못 생성한 단어로 인해 계속하여 잘못된 문장이 생성되어 학습이 잘 안되는 것을 방지
- 과적합 되지 않도록 적절히 설정해주어야 함
✔ Sequence to Sequence 활용
- 여러 text task 훈련 모델로 활용된다.
1. Machine Translation 번역
2. Dialogue 다음 대화 내용을 예측
3. Parsing 문장 구문 분석
4. time series 시계열
5. Text summarization 텍스트 요약
6. voice generation
7. Code generation
✔ NMT 의 train

- SMT 는 베이즈룰을 사용하여 모델을 2개로 분리해 훈련한 반면, NMT 는 conditional probaility 를 직접 계산한다.
- How ? 👉 big parallel corpus + End-to-End training


- 역전파를 사용하는 NN 의 loss min 문제로 정의함 👉 negative log likelihood 를 계산하여 loss 로 사용
2. Seq2Seq
✔ Multi-layer RNNs

- Time step 의 진행과 평행하게 layer 를 추가하여 좀 더 높은 레벨의 feature 를 학습할 수 있게 함
- 좋은 성능을 내는 RNN 모델은 대부분 Multi-layer RNN 구조를 사용한다. 그러나 일반적인 NN 이나 CNN 처럼 매우 깊은 구조는 사용되지 않는다.
- Encoder 2~4개, Decoder 4개 layer 💨 가장 좋은 성능을 보였다고 함
- 이후 Transformer base model 등장 이후 12 or 24개 layer 를 사용하는 경우도 생김 (BERT)
✔ NMT Decoding method
1) Greedy decoding


- 매 step 마다 가장 확률이 높은 다음 단어를 선택하는 방법 💨 argmax word
- 최적의 해를 보장하진 않기 때문에, 이미 선택한 단어를 이후 단어와의 조합을 사용하여 번복할 수 없어, 부자연스러운 문장이 생성될 수 있다.
- Exhaustive 방법보다 효율적으로 동작
2) Exhaustice search decoding

- 생성될 수 있는 모든 target 문장을 비교하여 확률이 가장 높은 문장을 선택하는 방법
- O(V) 계산 복잡도가 너무 크다는 단점
3) Beam Search decoding
- 핵심 아이디어 : K 개의 best translation 을 유지하며 decoding 하는 방식
- 보통 k (beam size) 는 5~10 사이의 숫자로 설정한다.

- k*k 개의 후보군을 비교하고 k 개의 best hypotheses 를 선택하는 과정을 반복한다.
- 최적해를 보장하진 않으나, 더 다양한 번역문이 등장할 수 있기 때문에 greedy search 가 놓칠 수 있는 더 나은 후보군을 유지할 수 있다.
- EOS 토큰의 등장이나 사전에 정의된 max timestep T, 또는 n 개의 완성된 문장을 종료조건으로 한다. 이를 통해 디코딩 과정이 너무 길어지는 것을 방지할 수 있다.
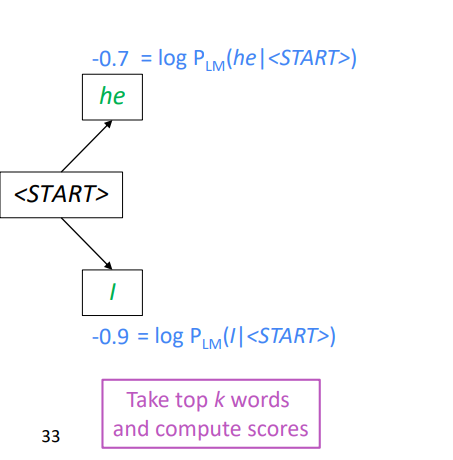



- log likelihood 값이 큰 두 개의 후보를 계속해서 선택하는 과정을 반복하며, EOS 토큰이 생성되는 문장 종료시까지 반복한다.

- NLL loss 합을 생성된 문장 길이로 나눠서 normalize 함 👉log likelihood 합으로 생성된 단어 조합을 비교할 때 더 긴 문장에서 log likelihood 합이 작아져 짧은 문장을 우선적으로 선택하는 것을 막기 위해 문장 길이로 likelihood 를 나누는 normalize 과정이 추가로 사용된다.
3. NMT 장단점
👀 장점
- Better Performance : more fluent, better use of context, better use of phrase similarities
- Single NN to be optimized end to end : subcomponent 가 필요 없다.
- less human engineering effort
👀 단점
- difficult to control : rule, guideline 적용이 어려움
- less interpretable → hard to debug
4. BLEU Bilingual Evaluation Understudy
기계번역 성능 평가 지표 👉 N-gram precision 방식을 사용
- 기계번역된 문장과 사람이 번역한 문장의 유사도를 계산하여, 디코딩 과정 이후 생성된 문장의 성능을 평가한다.
- N-gram precision 기반의 similarity score + penalty for too short translation
- 그러나 정성적으로 더 좋은 문장임에도 score 가 낮게 나올수 있는 불완전한 지표이다.

5. NMT 한계점

- 관용표현 해석 오류
- Bias 학습 : source 언어에서 성별에 대한 언급이 없었음에도 번역문에선 직업에 대한 성별 bias 를 가지고 있음
- Uninterpretable : 해석할 수 없는 표현에 대해 번역 모델은 임의의 문장을 생성한다 👉 사람과 달리 모델에서 학습하지 않은 입력에 대해 취약하다.
- Out of vocabulary words
- Domain mismatch between train and test data
- Maintaining context over longer text
- Low-resource language pairs
3️⃣ Attention
1. Bottleneck problem
✔ source 문장의 마지막 encoding 만을 입력으로 사용

- information bottleneck 정보의 손실이 발생한다.
- 적절한 번역문을 생성하려면 인코딩이 source 문장에 필요한 모든 정보를 담고 있어야 하는데 대부분 그러기에 충분하지 않음
2. Attention
✔ bottleneck problem 의 해결책
- Decoder 의 각 step 에서 source sentence 의 특정 부분에 집중할 수 있도록 Encoder 와 Connection 을 추가한다.
✔ Attention 이 decoding 에 반영되는 순서
① Encoder 의 step 별 encoding 과 Decoder hidden state 의 dot product 를 통해 similarity 를 계산하여 attention score 를 게산한다.
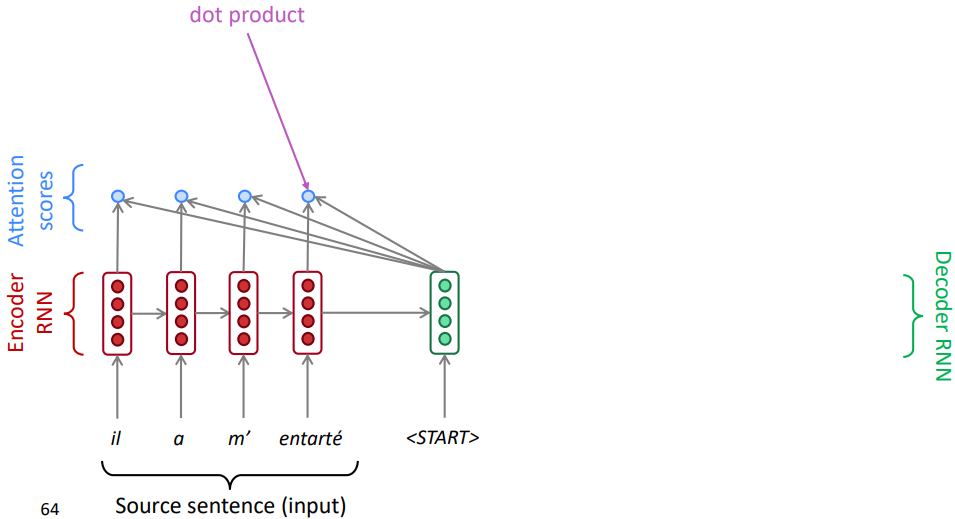
② softmax 를 통과시켜 attention distribution (attention weight) 을 계산한다.

③ Attention distribution 을 사용해 encoder hidden state 를 가중합하여 attention output 을 계산한다.

④ Attention output 과 decoder hidden state 를 concat 하고 해당 step 의 word 를 생성한다.

⑤ 각 step 별 decoder hidden state 마다 적용




✔ 수식으로 살펴보기


✔ Attention is great
1. NMT 의 성능 향상 💨decoder 가 source sentence 의 특정 영역에 집중할 수 있도록 함
2. Source sentence 의 모든 임베딩을 참고하는 구조를 사용해 bottleneck problem 을 해결함
3. Shortcut 구조를 사용하여 기울기 소실 문제를 줄임 + connection 은 멀리 떨어진 hidden state 간의 지름길을 제공하여 기울기 소실 문제를 해결
4. Attention probability 를 통해 결과에 대한 해석력을 제공함
✔ Attention 은 딥러닝 기술에 해당한다.
👀 Example
- 차량 리뷰 데이터를 통해 문장의 긍부정을 분류하는 감정분석을 수행한다.
- 문장단위, 단어 단위로 attention layer 를 사용하는 계층적 attention module 을 모델로 사용한다.

- 부정적으로 평가한 결과에 대해 어떤 문장과 어떤 단어에 대해 attention score 가 높았는지 확인해 볼 수 있다.
👀 Attention 의 일반적인 정의

'1️⃣ AI•DS > 📗 NLP' 카테고리의 다른 글
| [cs224n] 10강 내용 정리 (0) | 2022.05.13 |
|---|---|
| [cs224n] 9강 내용 정리 (0) | 2022.05.09 |
| [cs224n] 7강 내용 정리 (0) | 2022.04.21 |
| [cs224n] 6강 내용 정리 (0) | 2022.03.24 |
| [cs224n] 5강 내용 정리 (0) | 2022.03.22 |




댓글