1️⃣ K-means clustering
👀 개요
💡 k-means clustering
✔ 군집화에서 가장 일반적으로 사용되는 알고리즘
✔ Centroid = 군집 중심점 이라는 특정한 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법이다.

1. k 개의 군집 중심점을 설정
2. 각 데이터는 가장 가까운 중심점에 소속
3. 중심점에 할당된 데이터들을 대상으로 평균값을 구하고 그것을 새로운 중심점으로 설정
4. 각 데이터는 새로운 중심점을 기준으로 다시 가장 가까운 중심점에 소속됨
👉 중심점의 이동이 더이상 없을 때까지 반복
💡 장단점
💨 장점
✔ 일반적인 군집화에서 가장 많이 활용되는 알고리즘
✔ 알고리즘이 쉽고 간결함
💨 단점
✔ 거리기반 알고리즘으로 속성의 개수가 많으면 군집화 정확도가 떨어진다. 따라서 PCA 차원축소를 적용하는 경우가 많다.
✔ 반복 횟수가 많을 경우 수행 횟수가 느려진다.
✔ 군집 개수 k 를 선택하는 것이 어렵다 (trial)
💡 사이킷런 k-means
💨 파라미터
| from sklearn.cluster import KMeans |
| Kmeans(n_clusters=k, init='k-means++', max_iter = n, random_state=0) |
→ n_clusters = 군집화할 개수
→ init = 초기 군집 중심점 좌표를 설정할 방식을 말하며 일반적으로 'k-means++' 로 설정함
→ max_iter = 최대 반복 횟수로 이 횟수 이전에 모든 데이터의 중심점 이동이 없으면 종료한다.
💨 주요 속성 정보
→ .labels_ : 각 데이터 포인트가 속한 군집 중심점 레이블
→ .cluster_centers_ : 각 군집 중심점 좌표 이를 이용해 군집 중심점 좌표를 시각화할 수 있다.
⭐ K-means clutering 은 개별 군집 내의 데이터가 원형으로 흩어져 있는 경우 매우 효과적으로 군집화가 수행될 수 있다.
📌 실습 iris data
🏃♀️ 라이브러리 임포트 + 데이터 로드
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
irisdf = pd.DataFrame(data=iris.data, columns = ['sepal_length','sepal_width','petal_length','petal_width'])
irisdf.head(3)
🏃♀️ 클러스터링 fit
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter = 300, random_state = 0)
kmeans.fit(irisdf)
print(kmeans.labels_)

🏃♀️ 원래 정답 target label 과 비교
# 결과 비교해보기
irisdf['target'] = iris.target
irisdf['cluster'] = kmeans.labels_
iris_result = irisdf.groupby(['target', 'cluster'])['sepal_length'].count()
# sepal_length 열을 기준으로 데이터를 target 기준 그룹화 이후 세부적으로 cluster 로 그룹화를 진행
print(iris_result)

🏃♀️ PCA 를 사용해 2차원 데이터로 시각화 (군집화 결과 시각화)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_transformed = pca.fit_transform(iris.data)
irisdf['pca_x'] = pca_transformed[:,0]
irisdf['pca_y'] = pca_transformed[:,1]
# cluster 값이 0, 1, 2 인 경우마다 별도의 Index로 추출
marker0_ind = irisdf[irisdf['cluster']==0].index
marker1_ind = irisdf[irisdf['cluster']==1].index
marker2_ind = irisdf[irisdf['cluster']==2].index
# cluster값 0, 1, 2에 해당하는 Index로 각 cluster 레벨의 pca_x, pca_y 값 추출. o, s, ^ 로 marker 표시
plt.scatter(x=irisdf.loc[marker0_ind,'pca_x'], y=irisdf.loc[marker0_ind,'pca_y'], marker='o')
plt.scatter(x=irisdf.loc[marker1_ind,'pca_x'], y=irisdf.loc[marker1_ind,'pca_y'], marker='s')
plt.scatter(x=irisdf.loc[marker2_ind,'pca_x'], y=irisdf.loc[marker2_ind,'pca_y'], marker='^')
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.title('3 Clusters Visualization by 2 PCA Components')
plt.show()

2️⃣ 군집 평가
👀 개요
💡 군집평가
✔ 대부분의 군집화 데이터 세트는 target 변수가 없는 경우가 훨씬 많다.
✔ 데이터 내에 숨어있는 별도의 그룹을 찾아내 의미를 부여하거나, 동일한 분류값이더라도 그 안에서 더 세분화된 군집화를 추구하거나, 서로 다른 분류값의 데이터라도 더 넓은 군집화 레벨화 등의 영역을 가지고 있다.
✔ 비지도학습이라는 특성상 정확하게 성능을 평가하기는 어려우나, 대표적으로 실루엣 분석을 사용한다.
💡 실루엣 분석
💨 실루엣 분석이란
✔ 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는가를 나타내는 것
- 다른 군집과의 거리는 떨어져 있고, 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐 있다는 의미
- 군집화가 잘 될수록 개별 군집은 비슷한 정도의 여유공간을 가지고 떨어져 있을 것
💡 실루엣 계수
✔ "개별 데이터" 가 갖는 군집화 지표
- 해당 데이터가 같은 군집 내의 데이터와는 얼마나 가깝게 군집화 되어있고, 다른 군집에 있는 데이터와는 얼마나 멀리 분리되어 있는지를 타나내는 지표이다.

- a(i) : 해당 데이터 포인트와 '같은' 군집 내에 있는 다른 데이터 포인트와의 거리를 평균한 값
- b(i) : 해당 데이터 포인트가 '속하지 않은' 군집 중 '가장 가까운' 군집과의 평균 거리
- b(i) - a(i) : 두 군집간의 거리 👉 값을 정규화해주기 위해 MAX(a(i), b(i)) 로 나눔
- s(i) : i번째 데이터 포인트의 실루엣 계수
✔ 값의 해석
- -1~1 사이의 값을 가짐
- 1에 가까울수록 근처의 군집과 더 멀리 떨어져 있다는 것 👉 good
- 0에 가까울수록 근처의 군집과 가까워 지는 것
- 음수에 해당하는 값은 아예 다른 군집에 데이터 포인트가 할당 되었다는 뜻
✔ 사이킷런 메서드
| sklearn.metrics.silhouette_samples( X, labels, metric = 'euclidean' ) |
- labels : 군집화된 레이블 값
- 각 데이터 포인트의 실루엣 계수를 계산해 반환한다.
| sklearn.metrics.silhouette_score( X, labels, metric = 'euclidean' , sample_size=None) |
- 전체 데이터의 실루엣 계수 값을 '평균해' 반환한다.
- 일반적으로 값이 높을수록 군집화가 어느정도 잘 되었다고 판단할 수 있다. 그러나 무조건 값이 높다고 해서 군집화가 옳게 되었다고는 판단하기 어렵다.
💡 좋은 군집화가 될 조건
💨 silhouette_score 값이 0~1 사이의 값을 가지며, 1에 가까울수록 좋다.
💨 전체 실루엣 계수의 평균값과 더불어 개별 군집의 평균값의 편차가 크지 않아야 한다. 즉, 개별 군집의 실루엣 계수 평균값이 전체 실루엣 계수의 평균값에서 크게 벗어나지 않는 것이 중요하다.
💡 군집별 평균 실루엣 계수의 시각화를 통한 최적의 K 찾기
💨 전체 데이터의 평균 실루엣 계수 값이 높다고 하여 반드시 최적의 군집 개수로 군집화가 잘 되었다고 볼 수 없다.
💨 특정 군집 내 실루엣 계수만 너무 높고, 다른 군집은 내부 데이터끼리의 거리가 너무 떨어져 있어 실루엣 계수가 낮아져도, 평균적으로 높은 값을 가질 수 있다.
💨 개별 군집별로 적당히 분리된 거리를 유지하면서 군집 내 데이터가 서로 뭉쳐 있는 경우에 적절한 군집개수 K 가 설정되었다고 볼 수 있다.
✔ k=2 인 경우 실루엣 계수 결과 해석

- 빨간색 점선 👉 '전체' 평균 실루엣 계수 값
- 1번 군집의 모든 데이터는 평균 실루엣 계수 값 이상이지만, 2번 군집의 경우는 평균보다 적은 데이터 값이 매우 많다.
- 데이터를 시각화해본 결과에서도, 1번 군집의 경우에는 0번 군집과 멀리 떨어져 있고 내부 데이터끼리도 잘 뭉쳐져 있으나, 0번 군집의 경우에는 내부 데이터끼리 많이 떨어져 있음을 확인할 수 있다.
✔ k=3 인 경우 실루엣 계수 결과 해석

✔ k=4 인 경우 실루엣 계수 결과 해석

💡 이너셔와 엘보우
💨 최적의 군집 개수 k 찾기 (K-means clustering)


✔ mode.inertia_ 를 통해 시각화
💡 AIC 와 BIC
💨 k-means 에서 사용하는 이너셔, 실루엣 등의 방식은 클러스터가 타원형이거나 크기가 다르면 안정적이지 않으며 가우시안 혼합 모델에서는 사용할 수 없다.
💨
AIC, BIC 값을 최소화하는 군집개수 k 를 선택한다. 💨 GMM 모델에도 적용이 가능하다. 최적의 n_components 도출하기

✔ model.bic , model.aic 로 AIC, BIC 값을 불러와 시각화 하기
💡 가능도함수
✔ P(X|θ) = 파라미터 θ 를 알고있을 때, 그 모델이 x를 출력하는 것이 얼마나 그럴 듯 한가 = x의 함수
✔ L(θ|X) = 관측된 데이터 x를 알고 있을 때, 특정 파라미터 θ 가 얼마나 그럴 듯 한가 = θ 의 함수
✔ 가능도가 최대가 되는 파라미터 θ 가 되는 경우의 클러스터 개수를 찾는 것
📌 실습 iris data
🏃♀️ 실루엣 계수 값 계산하기
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
# ⭐ 실루엣 분석 metric
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
iris = load_iris()
feature_name = ['sepal_length','sepal_width','petal_length','petal_width']
irisdf = pd.DataFrame(data=iris.data, columns = feature_name)
kmeans = KMeans(n_clusters=3, init = 'k-means++', max_iter=300, random_state=0).fit(irisdf)
irisdf['cluster'] = kmeans.labels_
# 모든 개별 데이터에 대해 실루엣 계수값 구하기
score_samples = silhouette_samples(iris.data, irisdf['cluster']) # X, labels
print('실루엣 계수 return 값의 shape', score_samples.shape)
irisdf['실루엣계수'] = score_samples
# 모든 데이터의 평균 실루엣 계수값 구하기
average_score = silhouette_score(iris.data, irisdf['cluster'])
print('붗꽃 데이터셋 실루엣계수 점수 : {0:.3f}'.format(average_score))
irisdf.head(3)
#📌 cluster 1 에 해당하는 데이터의 실루엣 계수값은 0.8로 높지만, 다른 군집의 실루엣 계수 값이 평균보다 낮아
# 전체 데이터의 실루엣 계수 최종 평균 값은 0.553
#📌 군집별로 실루엣 계수 값을 살펴볼 필요가 있다.

irisdf.groupby('cluster')['실루엣계수'].mean()
#📌 군집별로 평균의 차이가 크게 발생하고 있다.

🏃♀️ 실루엣 계수 시각화
def viz_silhouette(cluster_lists, X_features) :
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import math
n_cols = len(cluster_lists)
fig,axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols)
for ind, n_cluster in enumerate(cluster_lists) :
clusterer = KMeans(n_clusters = n_cluster, max_iter = 500, random_state=0)
cluster_labels = clusterer.fit_predict(X_features)
sil_avg = silhouette_score(X_features, cluster_labels)
sil_values = silhouette_samples(X_features, cluster_labels)
y_lower = 10
axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \
'Silhouette Score :' + str(round(sil_avg,3)) )
axs[ind].set_xlabel("The silhouette coefficient values")
axs[ind].set_ylabel("Cluster label")
axs[ind].set_xlim([-0.1, 1])
axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10])
axs[ind].set_yticks([]) # Clear the yaxis labels / ticks
axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1])
for i in range(n_cluster) :
ith_cluster_sil_values = sil_values[cluster_labels==i]
ith_cluster_sil_values.sort()
size_cluster_i = ith_cluster_sil_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_cluster)
axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \
facecolor=color, edgecolor=color, alpha=0.7)
axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
axs[ind].axvline(x=sil_avg, color="red", linestyle="--")
from sklearn.datasets import load_iris
iris=load_iris()
viz_silhouette([ 2, 3, 4,5 ], iris.data)

👀 데이터 양이 늘어나면 수행 시간이 크게 늘어난다는 단점 존재
3️⃣ 평균 이동
👀 개요
💡 평균이동
✔ K-means clustering 과 유사하게 군집의 중심으로 중심을 지속적으로 움직이며 군집화를 수행한다.
✔ 이때 데이터가 모여있는 밀도가 가장 높은 곳으로 중심을 이동시킨다 👉 데이터의 분포도 (확률밀도함수) 를 이용해 군집 중심점을 찾는다
✔ 군집 중심 = 확률밀도함수가 피크인 지점 = 데이터가 가장 모여있는 지점
✔ 확률밀도함수를 찾기 위해 KDE 를 이용한다 : 특정 데이터와 주변 데이터와의 거리 값을 KDE 함수 값으로 입력한 뒤 반환값을 현재 위치에서 업데이트하며 이동하는 방식
| from sklearn.cluster import MeanShift |
- .cluster_centers_ 속성으로 군집 결과 시각화 시 군집 중심의 좌표를 표시할 수 있다.
meanshift = MeanShift(bandwidth=0.8)
cluster_labels = meanshift.fit_predict(X)
print('cluster labels 유형 :' , np.unique(cluster_labels))
🤸♀️ KDE 개념이해 참고 자료 : https://darkpgmr.tistory.com/147
→ 관측된 데이터 각각에 커널함수를 적용한 값을 모두 더하고 데이터 건수로 나눠 확률밀도함수를 추정한다.
→ Non-parametic 한 밀도추정 방법으로 히스토그램 방법의 문제점을 개선
→ 대표적인 커널 함수 : 가우시안 분포 함수
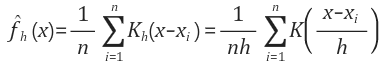
🤸♀️ 커널함수란
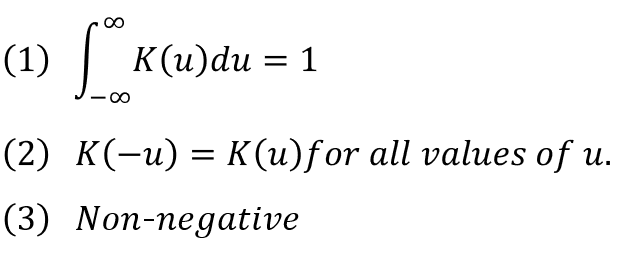
💡 대역폭 h
✔ KDE 형태를 부드러운 또는 뾰족한 형태로 평활화 하는데 적용된다.
✔ h 값에 따라 확률밀도 추정 성능을 크게 좌우할 수 있다. 작은 h (1.0) 값은 좁고 뾰족한 KDE 를 가지며 과적합 되기 쉽다. 반면 매우 큰 h (10) 값은 과도화게 평활화 smoothing 되어 지나치게 단순화된 방식으로 확률밀도함수를 추정하므로 과소적합 되기 쉽다.
✔ 적절한 대역폭 h 를 도출해내는 것이 KDE 기반의 평균이동 군집화에서 매우 중요하다.

- 대역폭 h 가 클수록 평활화된 KDE 로 인해 적은 수의 군집 중심점을 가진다.
- 평균이동 군집화는 미리 군집의 개수를 지정하지 않으며, 오직 대역폭의 크기에 따라 군집화를 수행 👉 최적의 h 를 설정해주는 것이 매우 중요 👉 estimate_bandwidth
| from sklearn.cluster import estimate_bandwidth |
bandwidth = estimate_bandwidth(X)
print('최적의 bandwidth 값 : ' , bandwidth)
💡 장단점
💨 장점
✔ 데이터 세트의 형태를 특정한 형태로 가정하지 않기 때문에 유연한 군집화가 가능하다.
✔ 이상치의 영향력이 크지 않다.
✔ 미리 군집의 개수도 정할 필요가 없다.
💨 단점
✔ 알고리즘 수행시간이 오래걸린다.
✔ h 에 따른 군집화 영향도가 매우 크다.
👉 평균이동 군집화 기법은 분석 업무 기반의 데이터 세트보단 컴퓨터 비전 영역 (object detection, motion detection) 에서 뛰어난 역할을 수행하는 알고리즘이다.
📌 실습 iris data
🏃♀️ 최적의 bandwidth h 값 도출
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.cluster import MeanShift
from sklearn.cluster import estimate_bandwidth
iris = load_iris()
feature_name = ['sepal_length','sepal_width','petal_length','petal_width']
irisdf = pd.DataFrame(data=iris.data, columns = feature_name)
bandwidth = estimate_bandwidth(iris.data)
print('대역폭 값 : ', bandwidth)
## 대역폭 값 : 1.2020768127998687
🏃♀️ 최적의 bandwidth 로 평균이동 군집화
irisdf['target'] = iris.target
meanshift = MeanShift(bandwidth = bandwidth)
cluster_labels = meanshift.fit_predict(iris.data)
print('cluster labels 유형 : ', np.unique(cluster_labels))
## cluster labels 유형 : [0 1] 📌 2개의 군집
🏃♀️ 시각화

🏃♀️ target 분포와 비교
print(irisdf.groupby('target')['meanshift_label'].value_counts())
4️⃣ GMM
👀 개요
💡 Gaussian Mixture Model

✔ 군집화를 적용하고자 하는 데이터가 여러개인 가우시안분포를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정하에 군집화를 수행하는 방식 👉 데이터를 여러 개의 가우시안 분포가 섞인 것으로 간주한다.
✔ 가우시안분포 (정규분포) 👉 좌우대칭의 종 형태를 가진 연속 확률 함수
✔ 전체 데이터 세트는 서로 다른 정규분포 형태를 가진 여러 가지 확률 분포 곡선으로 구성되며, 이렇게 서로 다른 정규분포에 기반해 군집화를 수행함 👉 데이터 세트로 부터 여러 개의 정규분포곡선을 추출하고 개별 데이터가 이 중 어떤 정규분포에 속하는지 결정한다.
💨 모수추정
① 개별 정규 분포의 평균과 분산
② 각 데이터가 어떤 정규분포에 해당되는지의 확률
💨 EM 알고리즘 (Iterative 한 알고리즘) 으로 모수 추정을 진행 : 사이킷런의 GaussianMixture 클래스 지원
✔ GMM, EM 알고리즘 참고자료 : https://angeloyeo.github.io/2021/02/08/GMM_and_EM.html
→ 정규분포를 가정한 채, 랜덤하게 모수를 주어준 뒤 라벨을 얻고, 그 라벨들을 이용해 다시 분포를 얻는 방식으로 clustering을 수행
| from sklearn.mixture import GaussianMixture |
⭐ n_components : 가우시안 모델의 총 개수 (K-means clustering 의 K 에 해당하는 부분)
💨 kmeans vs GMM

💨 이상치 탐지에서의 활용 : 밀도 임계값을 정해 밀도가 낮은 지역에 있는 모든 샘플을 이상치로 판단한다.

💡 Bayesian Gaussian Mixture Model
✔ 불필요한 클러스터의 가중치를 0 또는 0에 가깝게 만드는 방식
✔ 최적의 클러스터 개수를 수동으로 찾을 필요가 없다.
✔ 사이킷런의 BayesianGaussianMixture 클래스를 사용
✔ n_components 를 최적의 클러스터 개수보다 크게 지정하여도 자동으로 불필요한 클러스터를 제거하여 준다.
from sklearn.mixture import BayesianGaussianMixture
bgm = BayesianGaussianMixture(n_components = 10, n_init = 10, random_state=0)
bgm.fit(X)
bgm_label = bgm.fit_predict(X)
clusterdf['bgm_label] = bgm_label
# 시각화
np.round(bgm.weights_, 2)
## array([0.34, 0.34, 0.33, 0. , 0., 0., 0., 0., 0., 0.])
→ .weights_ 로 가중치를 확인해보면 지정한 10개의 클러스터 중 3개가 필요함을 알 수 있다. 나머지 클러스터의 가중치는 모두 0이 됨
📌 실습 iris data
🏃♀️ GMM clustering
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=3, random_state=0).fit(iris.data)
gmm_cluster_labels = gmm.predict(iris.data)
irisdf['gmm_cluster'] = gmm_cluster_labels
irisdf['target'] = iris.target
iris_result = irisdf.groupby(['target'])['gmm_cluster'].value_counts()
print(iris_result)
🏃♀️ 시각화
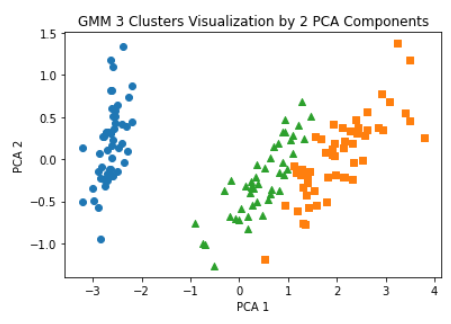
👉 K-means 결과보다 더 효과적인 분류 결과가 도출됨을 파악할 수 있는데, 이는 어떤 알고리즘이 더 뛰어나다는 의미가 아닌, 붓꽃 데이터 세트가 GMM 군집화에 더 효과적으로 작용하는 것이다.
⭐ GMM 의 경우는 Kmeasn (→ 원형 모양 외에, 예를들어 타원 모양 분포 데이터 셋에는 잘 작동하지 않음) 보다 유연하게 다양한 데이터 세트에 잘 적용될 수 있다. 그러나 수행 시간이 오래걸린다.
5️⃣ DBSCAN
👀 개요
입실론 주변 영역의 최소 데이터 개수를 포함하는 밀도 기준을 충족하는 core point를 연결하며 군집화

💡 DBSCAN
✔ 밀도 기반 군집화의 대표적인 알고리즘
✔ 특정 공간 내에 데이터 밀도 차이를 기반으로 하기 때문에 데이터의 분포가 기하학적으로 복잡한 데이터 세트에도 효과적인 군집화가 가능
💡 파라미터
| from sklearn.cluster import DBSCAN |
✔ epsilon : 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역 👉 eps
→ 보통 1 이하의 값을 설정한다.
→ 값을 크게하면 반경이 커져 포함하는 데이터가 많아지므로 노이즈 데이터 개수가 작아짐
✔ min points : core point 가 되기 위해 입실론 주변 영역 내 포함되어야 할 데이터의 최소개수 👉 min_samples
→ 값을 크게 하면 반경 내에 더 많은 데이터를 포함시켜야 하므로 노이즈 데이터 개수가 커짐

💡 주요 개념
◽ Core point : 주변 영역 내 최소 데이터개수 이상의 데이터를 가지고 있는 경우 (점 A)
👉 특정 core point 에서 직접 접근이 가능한 다른 core point 를 서로 연결하면서 군집화를 구성한다.
◽ Neighbor point : 주변 영역 내에 위치한 다른 데이터
◽ Border point : 주변 영역 내 최소 데이터 개수 이상의 데이터를 가지고 있진 않으나, core point 를 이웃 포인트고 라지고 있는 데이터 (점 B)
👉 군집의 외곽을 형성한다.
◽ Noise point : 최소 데이터 개수 이상의 이웃 데이터개수가 없으며 core point 도 이웃 포인트로 가지고 있지 않는 데이터 (점 C)
📌 실습
🏃♀️ DBSCAN 군집화
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.6, min_samples = 8, metric = 'euclidean')
dbscan_label = dbscan.fit_predict(iris.data)
irisdf['dbscan_clutser'] = dbscan_label
iris_result = irisdf.groupby(['target'])['dbscan_clutser'].value_counts()
print(iris_result)
#📌 0과 1 2개의 군집으로 분류를 수행
#📌 -1 : 노이즈에 속하는 군집을 의미한다.
#📌 DBSCAN 은 군집의 개수를 알고리즘에 따라 자동으로 지정해줌

🏃♀️ 시각화

👉 세모값은 노이즈에 해당하는 데이터로, 이상치를 한눈에 파악할 수 있다.
👉 eps 를 0.8로 증가시키면 노이즈 개수가 줄어든다.
6️⃣ 병합 군집
👀 개요
💡 병합군집 Agglomerative clustering
✔ 각각의 데이터 포인트를 하나의 클러스터로 지정하고, 지정된 개수의 클러스터가 남을 때까지 가장 비슷한 두 클러스터를 합쳐 나가는 알고리즘

✔ 두 클러스터를 합쳐 나가는 방식
a. Ward : 모든 클러스터 내의 분산을 가장 작게 증가시키는 두 클러스터를 합치는 방식으로 크기가 비교적 비슷한 클러스터가 만들어진다.
b. Average : 클러스터 포인트 사이의 평균 거리가 가장 짧은 두 클러스터를 합치는 방식
c. Complete : 클러스터 포인트 사이의 최대 거리가 가장 짧은 두 클러스터를 합치는 방식
💨 클러스터에 속한 포인트 수가 많이 다를 때 (하나의 클러스터가 다른 것보다 매우 클때) average 나 complete 방법이 더 좋다.
✔ 병합군집은 계층적 군집을 만든다. 즉, 작은 클러스터들이 모여 큰 클러스터를 이루는 계층적 구조를 가지는 것이다.
💡 계층적 군집
✔ 계층적 트리 모형을 이용해 개별 데이터 포인트들을 순차적, 계층적으로 유사한 클러스터로 통합하여 군집화를 수행하는 알고리즘
✔ 사전에 클러스터 개수를 정하지 않아도 학습 수행이 가능하다.
✔ 덴드로그램 : 계층 군집을 시각화 하는 도구로 다차원 데이터 세트를 처리할 수 있다.

- 덴드로그램을 가로선으로 분할하면 클러스터를 임의로 나눌 수 있다. 즉 군집화 하기 전 클러스터 개수를 정해주어야 하는 k-means 알고리즘과 달리 병합 군집 같은 계층적 군집 알고리즘은 군집화를 완료한 후에 사용자가 시각화된 덴드로그램을 보고 클러스터를 나눌 수 있는 것이다.
- 그러나 kmeans 와 마찬가지로 데이터 간 거리를 기반으로 하기 때문에 복잡한 형상의 데이터 세트는 구분하지 못한다.
'1️⃣ AI•DS > 📕 머신러닝' 카테고리의 다른 글
| 데이터마이닝 Preprocessing ② (0) | 2023.03.15 |
|---|---|
| 데이터마이닝 Preprocessing ① (1) | 2023.03.15 |
| [06. 차원축소] PCA, LDA, SVD, NMF (0) | 2022.04.24 |
| [05. 회귀] 선형회귀, 다항회귀, 규제회귀, 로지스틱회귀, 회귀트리 (0) | 2022.03.25 |
| [04. 분류] LightGBM, 스태킹 앙상블, Catboost (0) | 2022.03.20 |




댓글