07. LightGBM
📌 개요
💡 LightGBM
- XGBoost 와 예측 성능은 비슷하지만 학습에 걸리는 시간이 훨씬 적으며 다양한 기능을 보유하고 있다.
- 카테고리형 피처의 자동 변환(원핫인코딩을 하지 않아도 됨) 과 최적 분할 수행
- 균형 트리 분할 방식이 아닌 리프 중심 트리 분할 방식을 사용한다.
- 그러나 적은 데이터 세트 (10,000건 이하) 에 적용할 경우 과적합이 발생하기 쉽다.
- 리프중심 트리 분할 Leaf wise : 트리의 균형을 맞추지 않고 최대 손실값을 가지는 리프노드를 지속적으로 분할한다. 학습의 반복을 통해 결국 균형트리 분할 방식보다 예측 오류 손실을 최소화할 수 있게 된다.

📌 하이퍼 파라미터
- LightGBM 은 XGBoost 와 파라미터가 매우 유사하지만, 주의할점은 리프노드가 계속 분할되며 트리의 깊이가 깊어지므로 max_depth 와 같은 파라미터 설정에 유의해야 한다.
- 아래 파라미터는 파이썬 래퍼 LightGBM
| Parameter | 내용 |
| num_iterations | 디폴트 100. 반복수행하려는 트리의 개수를 지정. 크게 지정할수록 성능이 높아질 순 있으나 과적합에 주의해야한다. (=n_estimators) |
| learning_rate | 디폴트 0.1 로 0과 1 사이의 값을 지정하며 반복수행할 때 업데이트 되는 학습률 값 |
| max_depth | 디폴트 -1. 0보다 작은 값을 지정하면 깊이에 제한이 없다. 지금까지 소개한 Depth wise 방식과 다르게 LightGBM 은 Leaf wise 기반이므로 깊이가 상대적으로 더 깊다. |
| boosting | * gbdt : 일반적인 그래디언트 부스팅 결정 트리를 생성 * rf : 랜덤포레스트 방법으로 트리를 생성 |
| num_leaves | 디폴트 31. 하나의 트리가 가질 수 있는 최대 리프 개수로 모델의 복잡도를 제어하는 주요 파라미터이다. 개수를 높이면 정확도가 높아지나, 트리의 깊이가 깊어지고 복잡도가 커져 과적합 영향이 커진다. |
📌 실습 - 위스콘신 유방암 예측
from lightgbm import LGBMClassifier
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
ftr = dataset.data
target = dataset.target
X_train,X_test,y_train,y_test = train_test_split(ftr, target, test_size=0.2, random_state=156)
lgbm_wrapper = LGBMClassifier(n_estimators = 400)
evals = [(X_test, y_test)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds = 100, eval_metric = 'logloss',
eval_set = evals, verbose = True)
preds = lgbm_wrapper.predict(X_test)from sklearn.metrics import classification_report
print(classification_report(y_test, preds))from lightgbm import plot_importance
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10,12))
plot_importance(lgbm_wrapper, ax = ax)
10. 스태킹 앙상블
📌 개요
- 개별 알고리즘이 예측한 결과를 가지고 다시 최종 '메타 데이터 세트' 로 만들어, 별도의 ML 알고리즘 (메타 모델이라 부른다) 으로 최종 학습을 수행하고 테스트 데이터를 기반으로 최종 예측을 수행하는 방식
- 개별적인 여러 알고리즘을 서로 결합해 예측결과를 도출한다는 점에서 배깅과 부스팅 방식과 공통점이 있으나, 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 것이 큰 차이점이다.
📌 기본 스태킹 모델 실습
* 위스콘신 유방암 예제 데이터 로드
import numpy as np
# 스태킹 모델에 사용할 알고리즘
from sklearn.neighbors import KNeighborsClassifier # KNN
from sklearn.ensemble import RandomForestClassifier # 랜덤포레스트
from sklearn.ensemble import AdaBoostClassifier # 부스팅
from sklearn.tree import DecisionTreeClassifier # 결정트리
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀 (메타모델)
# 위스콘신 유방암 예제 데이터 로드
# metrics로 accuracy를 사용
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target
X_train, X_test, y_train, y_test = train_test_split(X_data, y_label, test_size=0.2)
👀 기반모델과 메타 모델 객체 생성 , 학습 , 예측
# 개별 머신러닝 모델 객체 생성 (기반모델)
knn_clf = KNeighborsClassifier(n_neighbors =4) # n_neighbors : 분류시 고려할 인접 샘플 수
rf_clf = RandomForestClassifier(n_estimators=100, random_state=30)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)
# 메타모델 (스태킹으로 만들어진 데이터 학습 및 예측)
lr_final = LogisticRegression(C=10) # C : 과대적합/과소적합 문제 해결을 위한 파라미터. 값이 크면 훈련을 복잡하게(약한규제)
# 개별 모델 학습
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train, y_train)
dt_clf.fit(X_train, y_train)
ada_clf.fit(X_train, y_train)
# 기반 모델 예측 세트와 정확도 확인
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)
print('KNN 정확도 :',accuracy_score(y_test, knn_pred))
print('RF 정확도 :',accuracy_score(y_test, rf_pred))
print('DT 정확도 :',accuracy_score(y_test, dt_pred))
print('ADA부스트 정확도 :',accuracy_score(y_test, ada_pred))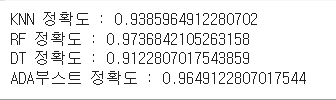
👀 기반 모델의 예측 결과를 스태킹
# 기반 모델의 예측 결과를 스태킹
stacked_pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred])
# transpose 를 이용하여 행과 열의 위치를 교환
# 칼럼 레벨로 각 모델의 예측 결과를 피처로 사용
stacked_pred = np.transpose(stacked_pred)
stacked_pred.shape # 4 : 모델의 개수 , 114 : 데이터 개수
# (114,4)
👀 메타모델의 학습 , 최종 정확도 도출
# 메타모델은 기반모델의 예측 결과를 기반으로 학습
lr_final.fit(stacked_pred, y_test)
final_pred = lr_final.predict(stacked_pred)
print('최종 메타 모델의 정확도 : ', accuracy_score(y_test, final_pred))
# 최종 메타 모델의 정확도 : 0.9912280701754386
📌 CV 세트 기반 스태킹
(참고)
[Python] 머신러닝 완벽가이드 - 04. 분류[스태킹 앙상블]
스태킹 앙상블
romg2.github.io
- 앞선 기본 스태킹 모델에 사용된 메타 모델인 로지스틱 회귀 모델에선 결국 y_test(테스트 데이터)를 학습했기 때문에 과적합 문제가 발생할 수 있다. 과적합을 개선하기 위해 최종 메타모델을 위한 데이터세트를 만들 때, 교차 검증 기반으로 예측된 결과 데이터 세트를 이용하는 방법을 사용한다.
⭐ 개별 모델이 교차 검증을 통해서 메타 모델에 사용되는 학습, 테스트용 스태킹 데이터셋을 생성하여 이를 기반으로 메타 모델이 학습과 예측을 수행하는 방식!
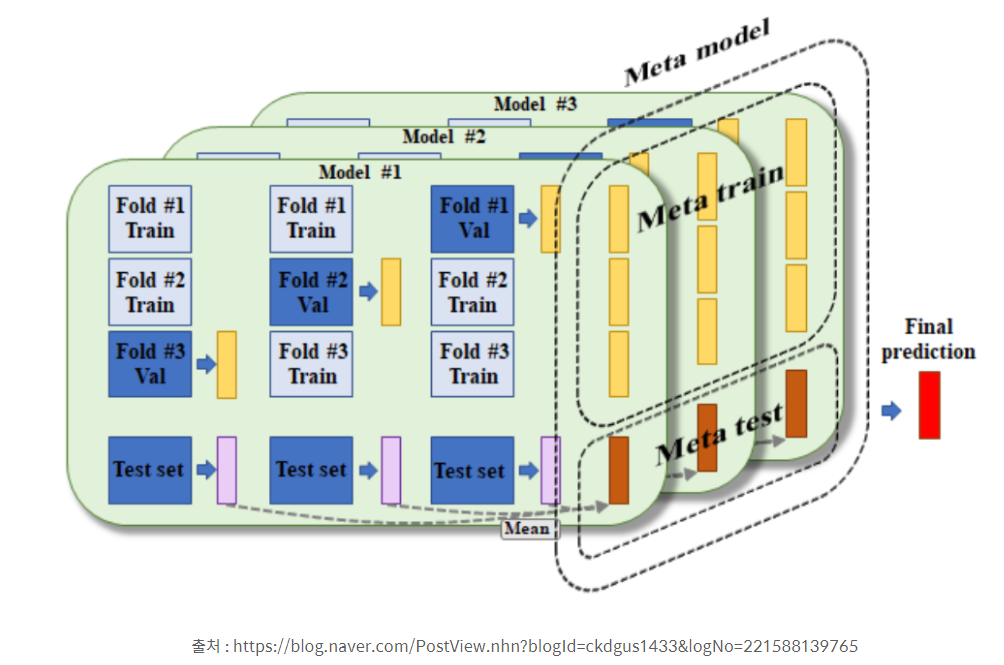
1. 훈련 set 를 N 개의 fold 로 나눈다. (3개라고 가정)
2. 2개의 fold 를 학습을 위한 데이터로, 1개의 fold 를 검증을 위한 데이터로 사용
3. 2개 폴드를 이용해 개별 모델을 학습, 1개의 검증용 fold 로 데이터를 예측한 후 결과를 저장
4. 3번 단계를 3번 반복 (검증용 폴드를 변경해가면서) , 이후 test set 에 대한 예측의 평균으로 최종 결과값 생성
4. 4번에서 생성된 최종 예측 결과를 메타 모델에 학습 및 예측 수행
👉 train meta data 와 test meta data 가 만들어진다는 것이 핵심!
* 위스콘신 유방암 예제 데이터
👀 메타 데이터 생성
from sklearn.model_selection import KFold
from sklearn.metrics import mean_absolute_error
# 개별 모델별 메타 데이터
def get_stacking_base_datasets(model, X_train, y_train, X_test, n_folds):
# KFold 생성
kf = KFold(n_splits=n_folds, shuffle=True, random_state=0)
# 메타 데이터 반환을 위한 기본 배열
train_cnt = X_train.shape[0]
test_cnt = X_test.shape[0]
train_meta = np.zeros((train_cnt, 1))
test_meta = np.zeros((test_cnt, n_folds))
print(model.__class__.__name__ , ' model 시작 ')
# train 데이터를 기반으로 fold를 나눠 학습/예측
for i , (train_fold_idx, test_fold_index) in enumerate(kf.split(X_train)):
# train, test fold 생성
print(f'\t 폴드 세트: {i+1} 시작 ')
x_train_fold = X_train[train_fold_idx]
y_train_fold = y_train[train_fold_idx]
x_test_fold = X_train[test_fold_index]
# train_fold로 학습
model.fit(x_train_fold , y_train_fold)
# train 메타 데이터 생성 (x_test_fold 예측)
train_meta[test_fold_index, :] = model.predict(x_test_fold).reshape(-1,1)
# test 메타 데이터 생성 (x_test 예측) - 평균 전
test_meta[:, i] = model.predict(X_test)
# test 메타 데이터 생성 - 평균 진행
test_meta_mean = np.mean(test_meta, axis=1).reshape(-1,1)
# train test 메타 데이터 반환
return train_meta , test_meta_mean
👀 훈련
knn_train, knn_test = get_stacking_base_datasets(knn_clf, X_train, y_train, X_test, 7) # knn
rf_train, rf_test = get_stacking_base_datasets(rf_clf, X_train, y_train, X_test, 7) # 랜덤포레스트
dt_train, dt_test = get_stacking_base_datasets(dt_clf, X_train, y_train, X_test, 7) # 결정트리
ada_train, ada_test = get_stacking_base_datasets(ada_clf, X_train, y_train, X_test, 7) # 에이다부스트
👀 모델별 학습, 테스트 데이터 합치기
Stack_final_X_train = np.concatenate((knn_train, rf_train, dt_train, ada_train), axis=1)
Stack_final_X_test = np.concatenate((knn_test, rf_test, dt_test, ada_test), axis=1)
print('원본 학습 피처 데이터 shape', X_train.shape, '원본 테스트 피처 데이터 shape', X_test.shape)
print('스태킹 학습 피처 데이터 shape:', Stack_final_X_train.shape, '스태킹 테스트 피처 데이터 shape : ', Stack_final_X_test.shape)
👀 예측 수행
lr_final.fit(Stack_final_X_train, y_train)
stack_final = lr_final.predict(Stack_final_X_test)
print('최종 메타 모델의 예측 정확도 : ', accuracy_score(y_test, stack_final))
# 최종 메타 모델의 예측 정확도 : 0.9736842105263158
catboost
📌 개요
💡 Boosting 의 기본 아이디어 = Residual Boosting
- 실제 값들의 평균과 실제 값의 차이인 잔차를 구한다 👉 잔차를 학습하는 모델 생성 👉 예측 👉 예측 값에 학습률을 곱해 값을 업데이트 한다 (반복)
- bias 를 작게 만드는 장점을 가지고 있으나 분산-편향 트레이드 오프 관계에 의해 high variance 즉 오버피팅이 발생할 경우가 높다.
💡 CatBoost
- 결정트리에서의 그래디언트 부스팅 알고리즘을 기반으로 한다.
- 검색, 추천시스템, 날씨 예측 등의 작업에 많이 사용된다.
- 데이터셋 대부분이 범주형 변수일 때 좋은 성능을 보인다.
- Target leakage 로 인한 과적합을 막아준다.
➕ Target leakage : https://m.blog.naver.com/hongjg3229/221811766581
복습. GBM : 경사하강법을 통해 가중치를 업데이트 하면서 여러 개의 약한 학습기를 순차적으로 학습-예측하는 앙상블 학습 방식
- 대칭트리 구조는 예측 시간을 감소시켜 학습 속도를 빠르게 만든다.
💡 특징
- GBM 의 단점인 과적합 문제와 학습속도 문제, 하이퍼 파라미터에 따라 성능이 달라지는 문제를 개선한 알고리즘
- 범주형 변수를 원핫인코딩, label 인코딩 등 인코딩 작업을 하지 않고 그대로 모델의 input 으로 사용할 수 있다.
- 수치형 변수가 많은 데이터의 경우 학습 속도가 느리다. 범주형 변수가 많을 때 적합한 알고리즘이다.
- Level-wise tree : Feature 를 모두 동일하게 대칭적인 트리 구조를 형성하게 된다 👉 예측 시간을 감소시킴
- Ordered boosting : 기존 부스팅 모델이 일괄적으로 모든 훈련 데이터를 대상으로 잔차를 계산했다면, catboost 는 일부만 가지고 계산한 뒤, 모델을 만들고 그 뒤에 데이터의 잔차는 모델로 예측한 값을 사용한다.

- Random Permutation : ordered boosting 을 할 때 데이터 순서를 섞지 않으면 매번 같은 순서대로 잔차를 예측하게 되므로 이런 것을 감안하여 데이터를 셔플링하여 뽑아낸다 👉 트리를 다각적으로 만들어 오버피팅을 방지
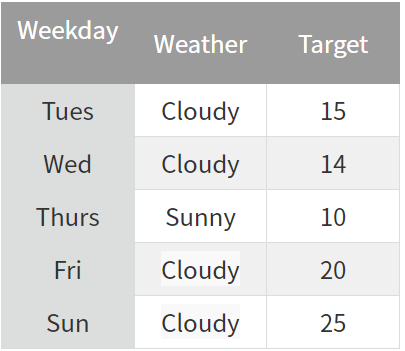
- Orderd Target Encoding : 범주형 변수를 수치형으로 변환할 때 임의로 시계열적인 (순차적인) 아이디어를 적용해 인코딩 한다. 예를들어 아래의 표에서 금요일에 해당하는 Cloudy 를 인코딩 할때 앞서 얻은 Tues, Wed 에 해당하는 Target 값의 평균을 이용하여 인코딩 한다. (15+14)/2 = 14.5 동일하게 일요일에 대한 Cloudy 는 (15+14+20)/3 = 16.3 이렇게 계산한다. 즉, 과거의 데이터를 이용해 현재의 데이터를 인코딩 하는 원리이다. 이렇게 하면 data leakage 문제를 방지할 수 있다.
- Categorical Feature Combination : 정보가 중복되는 범주형 변수 처리. 정보가 동일한 두 feature 를 하나의 feature 로 묶어서 데이터 전처리에 있어 feature selection 부담을 줄인다.
- One-Hot Encoding : 범주형 변수들 중 값의 level 수가 일정 개수보다 작으면 해당 범주형은 원핫인코딩 방식으로 처리해준다. 즉 중복도가 높은 범주형 변수들에게 적용하는 방식
- Optimized Parameter Tuning : 하이퍼 파라미터에 의해 크게 성능이 좌우되지 않는다.
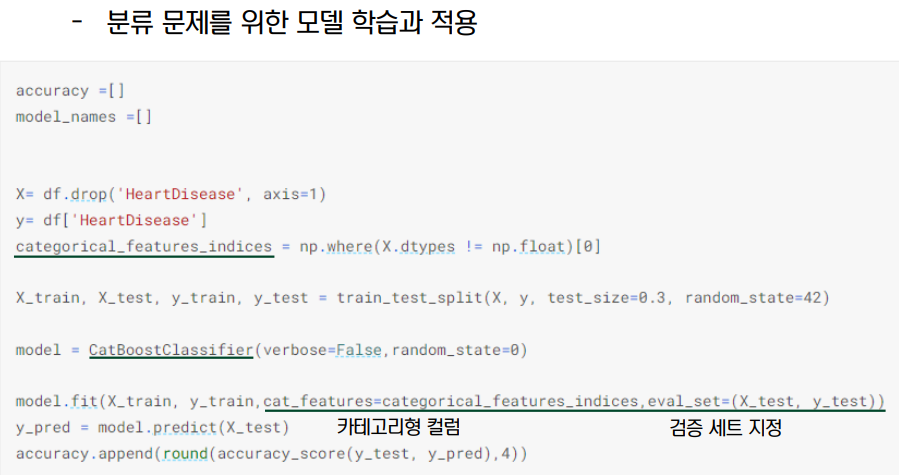
- catboost 는 파라미터 튜닝에 크게 신경쓰지 않아도 된다. 부스팅 모델들의 파라미터 튜닝의 이유는 트리의 다형성과 오버피팅 문제를 해결하기 위함인데, catboost 는 내부적인 알고리즘으로 해결하고 있기 때문이다. 해준다면 learning_rate, random_strength, L2_regulariser 정도
💡 한계
- Sparse 한 행렬은 처리하지 못한다. (즉, 결측치가 매우 많은 데이터셋에는 부적합한 모델이다)
- 데이터 대부분이 수치형 변수인 경우 학습 속도가 lightGBM 보다 느리다.
참고자료
➕ https://dailyheumsi.tistory.com/136
➕ https://techblog-history-younghunjo1.tistory.com/199
➕ https://www.kaggle.com/code/prashant111/catboost-classifier-in-python/notebook
'1️⃣ AI•DS > 📕 머신러닝' 카테고리의 다른 글
| [05. 클러스터링] K-means, 평균이동, GMM, DBSCAN (0) | 2022.05.07 |
|---|---|
| [06. 차원축소] PCA, LDA, SVD, NMF (0) | 2022.04.24 |
| [05. 회귀] 선형회귀, 다항회귀, 규제회귀, 로지스틱회귀, 회귀트리 (0) | 2022.03.25 |
| [04. 분류] GBM, XGboost (0) | 2022.03.14 |
| [01,02] 머신러닝 개요 (0) | 2022.03.13 |




댓글