05. GBM
📌 개요 및 실습
💡 부스팅 알고리즘
- 여러개의 약한 학습기를 순차적으로 학습 - 예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식이다.
- 대표 알고리즘 : AdaBoost, Gradient Booting Machine(GBM), XGBoost, LightGBM, CatBoost
1️⃣ AdaBoost
→ 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘 (교재 그림 확인)
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
clf = AdaBoostClassifier(n_estimators=30,
random_state=10,
learning_rate=0.1)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
print('AdaBoost 정확도: {:.4f}'.format(accuracy_score(y_test, pred)))
2️⃣ 그래디언트 부스트 (GBM)
→ AdaBoost 와 유사하나 가중치 업데이트를 경사하강법을 이용하는 것이 큰 차이다.
→ 경사하강법 : (실제값-예측값) 을 최소화하도록 하는 방향성을 가지고 반복적으로 가중치 값을 업데이트 한다.
→ 분류와 회귀 모두 가능하다.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train , X_test, y_train, y_test = train_test_split(X,y, test_size = 0.3, random_state=10)
gb_clf = GradientBoostingClassifier(random_state = 0)
# default 값 max_depth = 3
gb_clf.fit(X_train, y_train)
print(gb_clf.score(X_train, y_train)) # .score : 정확도 반환
# 0.1
print(gb_clf.score(X_test, y_test))
# 0.9777777777778from sklearn.metrics import accuracy_score
y_pred = gb_clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
# 0.9777777777777777- 일반적으로 GBM 이 랜덤포레스트보다는 예측 성능이 조금 뛰어난 경우가 많다. 그러나 약한 학습기의 순차적인 예측 오류 보정 때문에 수행 시간이 오래걸리고, 하이퍼파라미터 튜닝에 대한 노력도 필요하다.
📌 GBM 하이퍼파라미터
| Parameter | 설명 |
| n_estimator | 생성할 약한 학습기의 개수 (디폴트는 100) |
| max_depth | 트리의 최대 깊이 (디폴트는 3) 깊어지면 과적합 될 수 있으므로 적절한 제어 필요 |
| max_features | 최적의 분할을 위해 고려할 최대 feature 개수 |
| loss | 경사 하강법에서 사용할 비용함수 지정 (디폴트는 deviance) |
| learning_rate | 약한 학습기가 순차적으로 오류 값을 보정해 나아가는데 적용하는 계수로 0~1 사이의 값 지정 가능. 디폴트는 0.1 🔸 너무 작은 값을 지정하면 예측 성능은 높아질 수 있지만 수행시간이 오래걸릴 수 있고 반복이 완료되어도 최소 오류값을 찾지 못할 수 있음 🔸 너무 큰값을 지정하면 빠른 수행은 가능하나 최소오류값을 찾지 못하고 지나쳐 예측 성능이 저하될 수 있음 |
| subsample | 학습에 사용하는 데이터의 샘플링 비율로 0~1 값 지정 가능 (디폴트는 1로 즉 전체 학습 데이터 기반) |
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [100,500],
'learning_rate' : [0.05, 0.1]
}
grid_cv = GridSearchCV(gb_clf, param_grid = params, cv = 2, verbose = 1)
# verbose : iteration 마다 수행 결과 메시지를 출력하는 부분
# verbose = 0 : 메시지 출력 안함 (디폴트)
# verbose = 1 : 간단한 메시지 출력 , verbose = 2 : 하이퍼파라미터별 메시지 출력
grid_cv.fit(X_train, y_train)
print('최적의 하이퍼 파라미터 : \n', grid_cv.best_params_)
# {'learning_rate': 0.05, 'n_estimators': 100}
print('최고 예측 정확도 : {0:.4f}'.format(grid_cv.best_score_))
# 최고 예측 정확도 : 0.9334
gb_pred = grid_cv.best_estimator_.predict(X_test) # 최적으로 학습된 estimator 로 예측 수행
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도 : {0:.4f}'.format(gb_accuracy))
# GBM 정확도 : 0.9778
06. XGBoost
📌 개요 및 실습
💡 XGBoost
- 트리 기반의 앙상블 학습에서 가장 각광받고 있는 알고리즘 중 하나이다.
👀 장점
- 분류에 있어 일반적으로 다른 머신러닝보다 뛰어난 예측 성능을 나타낸다.
- GBM 에 기반하고 있지만, GBM 의 단점인 느린 수행시간 및 과적합 규제 부재 등의 문제를 해결하여 매우 각광받고 있다. 병렬 학습이 가능해 기존 GBM 보다 빠르게 학습을 완료할 수 있다.
- 과적합 규제 (Regularization) 기능이 있다. (GBM 은 없음)
- Tree prunning (나무 가지치기) : max_depth 파라미터로 분할 깊이를 조정하기도 하지만, tree prunning 으로 더 이상 긍정 이득이 없는 분할을 가지치기 해서 분할 수를 더 줄이는 추가적인 장점을 가지고 있다.
- 자체 내장된 교차 검증 : 교차검증을 수행해 최적화된 반복 수행 횟수를 가질 수 있으며 평가 값이 최적화 되면 반복을 중간에 멈출 수 있는 조기 중단 기능이 있다.
- 균형트리분할 : 최대한 균형잡힌 트리를 유지하면서 분할한다. (트리의 깊이 최소화, 과적합 방지)
- 결손값 자체 처리
📌 하이퍼파라미터
- GBM 과 유사한 하이퍼 파라미터를 동일하게 가지고 있으며 여기에 조기중단 (early stopping) , 과적합을 규제하기 위한 하이퍼 파라미터 등이 추가 되었다.
- XGBoost 자체적으로 교차검증, 성능평가, 피처 중요도 등의 시각화 기능을 가지고 있다.
1️⃣ 파이썬 래퍼 XGBoost
import xgboost
| Parameter | 설명 |
| eta | GBM 의 학습률과 같은 파라미터로, 0에서 1 사이의 값을 지정한다. 파이썬 래퍼 기반의 디폴트는 0.3 |
| num_boost_rounds | GBM 의 n_estimators (약한 학습기의 개수) 와 같은 파라미터이다. |
| min_child_weight | (디폴트 1) 트리에서 추가적으로 가지를 나눌지를 결정하기 위해 필요한 weight 의 총합. 값이 클수록 분할을 자제한다. 과적합을 조절하기 위해 사용한다. |
| gamma | (디폴트 0) 리프노드를 추가적으로 나눌지를 결정할 최소 손실 감소 값이다. 해당 값보다 큰 손실이 감소된 경우에 리프노드를 분리한다. 값이 클수록 과적합 감소 효과가 있다. |
| max_depth | 트리 기반 알고리즘의 max_depth 와 같다. 0을 지정하면 깊이에 제한이 없다. 보통 3~10 사이의 값을 적용한다. |
| sub_sample | GBM 의 subsample 과 동일하다. 트리가 커져서 과적합 되는 것을 제어하기 위해 데이터를 샘플링하는 비율을 지정한다. 0.5로 지정하면 전체 데이터의 절반을 트리를 생성하는 데 사용한다. 0에서 1 사이의 값이 가능하나, 일반적으로 0.5~1 사이의 값을 사용한다. |
| lambda | L2 규제 적용값. 피처 개수가 많을 경우 적용을 검토하며, 값이 클수록 과적합 감소 효과가 있다. |
| alpha | L1 규제 적용값. 피처 개수가 많을 경우 적용을 검토하여, 값이 클수록 과적합 감소 효과가 있다. |
👉 과적합 문제 방지하기
- 0.01~0.1 정도 eta 값을 낮춘다.
- n_estimator 를 높인다. (num_round)
- max_depth 값을 낮춘다.
- min_child_weight 값을 높인다.
- gamma 값을 높인다.
- subsample 과 colsample_bytree 를 조정하여 트리가 너무 복잡하게 생성되는 것을 막아 과적합 문제가 발생하지 않도록 한다.
⭐ 자체적으로 교차 검증, 성능 평가, 피처 중요도 등의 시각화 기능을 가지고 있다.
⭐ 조기중단 기능이 있어서 부스팅 반복 횟수에 도달하지 않아도 예측 오류가 개선되지 않으면 중단한다.
2️⃣ 사이킷런 래퍼 XGBoost
from xgboost import XGBClassifier
| Parameter | 설명 |
| learning_rate | 학습률 |
| subsample | 트리가 커져서 과적합 되는 것을 제어하기 위해 데이터를 샘플링하는 비율을 지정한다. 0.5로 지정하면 전체 데이터의 절반을 트리를 생성하는 데 사용한다. 0에서 1 사이의 값이 가능하나, 일반적으로 0.5~1 사이의 값을 사용한다. |
| reg_lambda | L2 규제 적용값. 피처 개수가 많을 경우 적용을 검토하며, 값이 클수록 과적합 감소 효과가 있다. |
| reg_alpha | L1 규제 적용값. 피처 개수가 많을 경우 적용을 검토하여, 값이 클수록 과적합 감소 효과가 있다. |
✔ 조기중단 관련 파라미터 : early_sropping_rounds 로 fit() 의 인자로 입력하면 된다.
✔ eval_metric : 조기중단을 위한 평가지표
✔ eval_set : 성능 평가를 수행할 데이터셋
📌 위스콘신 유방암 예측
✔ 악성종양(malignant) , 양성종양(benign) 인지 분류하는 문제
✔ 피처 : 종양의 크기, 모양 등 다양한 속성값이 존재
1️⃣ 파이썬 래퍼 XGBoost
import xgboost as xgb
from xgboost import plot_importance
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# 01. 데이터 로드
dataset = load_breast_cancer()
X_features = dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data = X_features, columns = dataset.feature_names)
cancer_df['target'] = y_label
# 02. target 분포 확인
print(cancer_df['target'].value_counts())
### 1 357
### 0 212# 03. 훈련셋, 테스트셋 생성
X_train, X_test, y_train, y_test = train_test_split(X_features, y_label, test_size = 0.2, random_state = 156)
## 파이썬 래퍼의 xgboost 적용에서는 훈련, 테스트 데이터 셋을 DMatrix 객체로 만들어야 한다.
dtrain = xgb.DMatrix(data = X_train, label = y_train)
dtest = xgb.DMatrix(data = X_test, label = y_test)# 04. 하이퍼 파라미터 설정, 훈련
# 하이퍼파라미터 설정 : 딕셔너리 형태로 지정
params = {
'max_depth' : 3 , #트리의 최대 깊이는 3
'eta' : 0.1 , # 학습률은 0.1
'objective' : 'binary:logistic', # 예제 데이터가 0 또는 1 이진분류 이므로 목적함수는 이진 로지스틱
'eval_metric' : 'logloss', # 오류 함수의 평가 성능 지표
'early_stoppings' : 100 # 조기중단
}
num_rounds = 400 # 부스팅 반복 횟수는 400회
wlist = [(dtrain, 'train'), (dtest, 'eval')]
xgb_model = xgb.train(params = params, dtrain = dtrain, num_boost_round = num_rounds,
early_stopping_rounds = 100, evals = wlist)
# 조기중단할 수 있는 최소반복횟수 : 100
# loss 가 지속적으로 감소함을 확인해볼 수 있음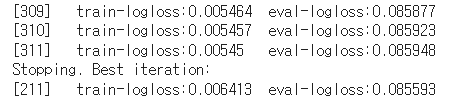
🧐 logloss 란?
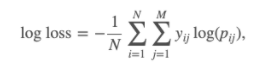
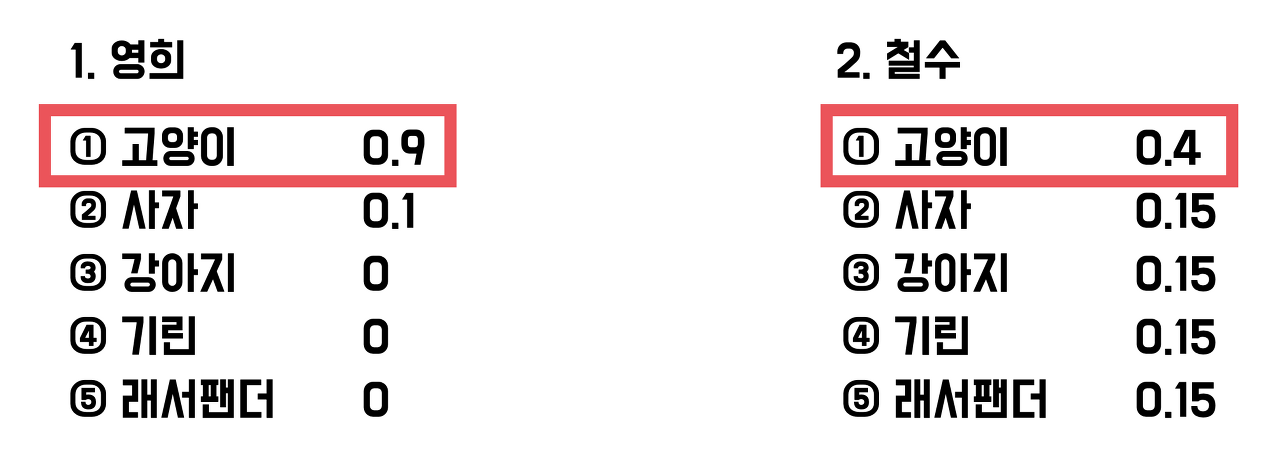
- 다중 클래스 분류 모델 (target 이 3개 이상) 을 평가하는 방법이다.
- 모델이 예측한 확률값을 직접적으로 반영하여 평가한다. 즉, 정답을 맞췄다고 해도, 정답을 더 높은 확률로 예측할 수록 더 좋은 모델이라고 평가하는 것
- logloss 값이 작을수록 (= pij 확률이 1에 가까울수록 = 0에 가까운 값이므로) 좋은 모델이다.
- ex. 100% 확률(확신)으로 답을 구한 경우의 logloss 는 -log(1.0) = 0 이고, 60%의 확률의 경우에는 -log(0.6) = 0.51082 이다.
➕ https://seoyoungh.github.io/machine-learning/ml-logloss/
# 05. 예측
pred_probs = xgb_model.predict(dtest)
print('predict 결과 10개 표시, 예측 확률값으로 표시됨')
print(np.round(pred_probs[:10],3))
## [0.934 0.003 0.91 0.094 0.993 1. 1. 0.999 0.997 0. ]
preds = [1 if x > 0.5 else 0 for x in pred_probs]
# 0.5 보다 크면 1, 아니면 0으로 레이블링
print('예측값 10개만 표시 : ', preds[:10])
## 예측값 10개만 표시 : [1, 0, 1, 0, 1, 1, 1, 1, 1, 0]# 06. 성능평가지표
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, preds)
# array([[35, 2],
# [ 1, 76]])
from sklearn.metrics import classification_report
print(classification_report(y_test, preds))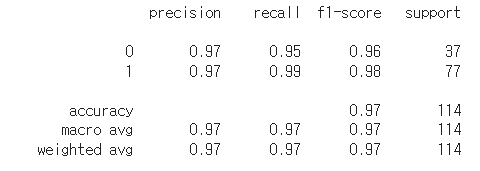
# 07. 변수 중요도 출력
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10,12))
plot_importance(xgb_model, ax = ax)
# 변수 중요도 출력 : f1 스코어를 기반으로 각 피처의 중요도를 나타낸다.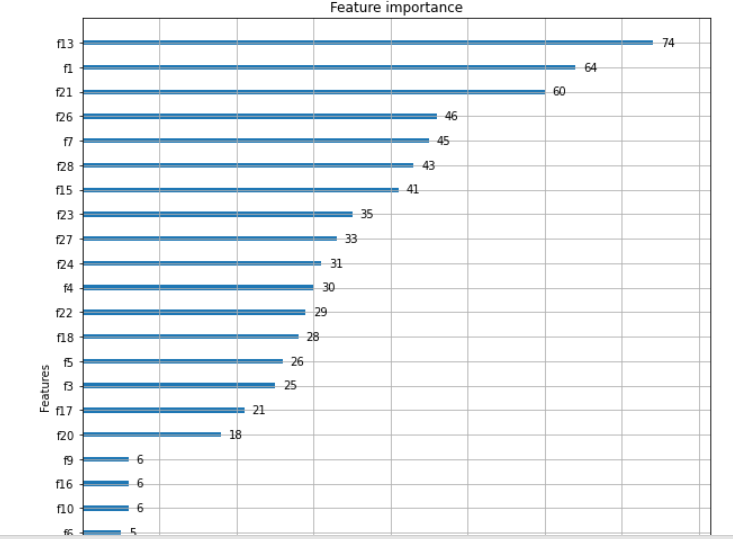
⭐ https://wikidocs.net/22881 : 로지스틱 회귀(이진분류), 인공 지능 알고리즘이 하는 것은 결국 주어진 데이터에 적합한 가중치 w와 b를 구하는 것입니다.
2️⃣ 사이킷런 래퍼 XGBoost
# 사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate = 0.1, max_depth = 3)
xgb_wrapper.fit(X_train, y_train)
w_preds = xgb_wrapper.predict(X_test)
from sklearn.metrics import classification_report
print(classification_report(y_test, w_preds))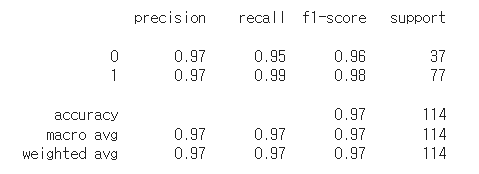
# 조기중단 사용해보기
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate = 0.1, max_depth = 3)
evals = [(X_test, y_test)] # 성능평가를 수행할 데이터셋
xgb_wrapper.fit(X_train, y_train, early_stopping_rounds = 100, eval_metric = 'logloss', eval_set = evals, verbose = True)
ws100_preds = xgb_wrapper.predict(X_test)
# 211 번 반복시 logloss 가 0.085593 인데, 311번 반복시 logloss가 0.085948로 지정된 100번의 반복동안 성능평가지수가 향상되지 않았기에 조기종료
print(classification_report(y_test, ws100_preds))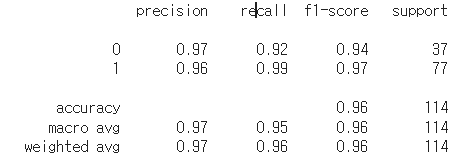
xgb_wrapper.fit(X_train, y_train, early_stopping_rounds = 10, eval_metric = 'logloss', eval_set = evals, verbose = True)
ws10_preds = xgb_wrapper.predict(X_test)
print(classification_report(y_test, ws10_preds))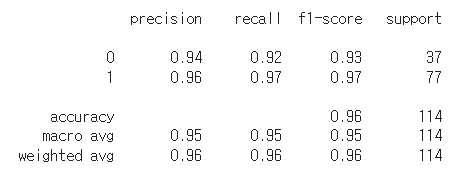
# 변수 중요도
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10,12))
plot_importance(xgb_wrapper, ax = ax)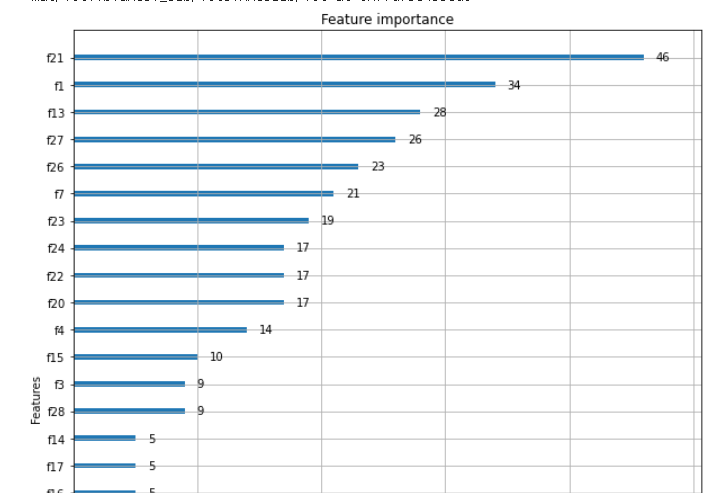
'1️⃣ AI•DS > 📕 머신러닝' 카테고리의 다른 글
| [05. 클러스터링] K-means, 평균이동, GMM, DBSCAN (0) | 2022.05.07 |
|---|---|
| [06. 차원축소] PCA, LDA, SVD, NMF (0) | 2022.04.24 |
| [05. 회귀] 선형회귀, 다항회귀, 규제회귀, 로지스틱회귀, 회귀트리 (0) | 2022.03.25 |
| [04. 분류] LightGBM, 스태킹 앙상블, Catboost (0) | 2022.03.20 |
| [01,02] 머신러닝 개요 (0) | 2022.03.13 |




댓글