💡 주제 : Backpropagation and Computation Graphs
📌 목차 정리
1. Matrix gradient for NN
(1) NN 의 과정
- feedforward : X * W = output vector = predict 값
- backpropagation : output vector 를 weight matrix 에 대해 미분
(2) 가중치 행렬 (parameter) 의 미분
- Chain Rule : 함수의 연쇄법칙을 기반으로 이루어지는 계산 규칙 (합성함수의 미분)
- NN 은 chain rule 을 이용해 최종 scalar 값을 weight 로 미분해가며 가중치를 업데이트 하는 방식으로 학습을 진행한다.

- dz/dw 를 계산하는 과정


(3) Gradient Tips
- 변수를 잘 정의하고 차원을 계속 생각하고 있을 것
- Chain Rule 을 잘 숙지할 것
- 모델 마지막 softmax 값에 대해서 correct class 와 incorrect class 에 대해 따로 미분하여 계산할 것
- 행렬 미분 방법이 헷갈리면 element-wise 부분 미분을 연습할 것
- Shape convention 을 이용할 것 ( error message
(4) Word vector 에 대한 미분
- window 단위로 단어 벡터를 정의하게 된다.
- 단어벡터들이 task 에 도움이 되는 방향으로 변화한다.

(4) Word vector 를 학습시키는 것 🤔

학습 데이터에 TV, telly 가 있고 television 은 없다고 가정해보자

👉 TV 와 telly 는 모델의 목적에 맞게 가중치를 업데이트 하며 움직임
👉 그러나 television 은 학습 데이터셋에 포함되지 않는다는 이유로 가중치가 업데이트 되지 못하여 다른 의미를 지닌 단어로 잘못 분류됨
👀 위의 경우에는 Pre-trained 된 모델을 사용하면 된다!
(5) Pre-trained Model
- 규모가 큰 corpus 데이터셋에 이미 학습되어 있는 모델
- Word2vec, Glove 모두 pre-trained 모델이다.
- pre-trained 모델을 사용하면 TV, telly, television 같이 비슷한 단어의 경우 훈련 데이터 셋 포함 유무에 관계 없이 일정 수준의 유사 관계가 형성된다.
- 데이터양이 100만개 이상이면 랜덤 워드 벡터로부터 시작해서 모델을 학습시켜도 괜찮음
(6) Fine - Tuning
- 기존에 학습된 모델을 기반으로 모델의 구조를 목적 task 에 맞게 변형하고 이미 학습된 Weight 로 부터 학습을 업데이트 하는 방법
- Training Dataset 이 많은 경우에 fine tuning 을 하여 word vector 를 학습시키면 성능이 좋아짐
* retraining : data 를 새로 가져와서 train 과정부터 다시 학습시키는 것
2. Computation Graphs and Backpropagation
(1) Computational Graph
- 계산 그래프 : 계산 과정을 그래프로 나타낸 것으로 여러개의 node 와 선(edge) 로 표현된다.

(2) Forward Propagation
- x (input) 에서 시작하여 s 를 구하는 방향까지의 연산 과정

(3) Back Propagation
- 순전파를 통해 얻어진 결과값과 실제값을 비교하여 오차를 계산 👉 오차를 미분하여 가중치를 업데이트!
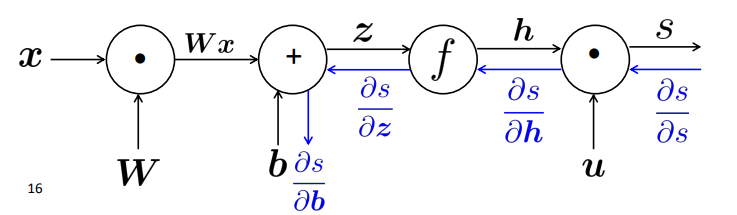
- Single Node (single input)
- upstream gradient → local gradient → downstream gradient
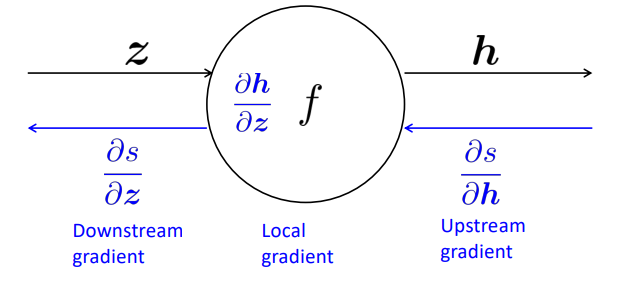
Downstream = Local * Upstrean
✨ chain rule ✨
- single node (muliple input)

- 계산 효율성 : 역전파를 수행할 때 효율적으로 미분값을 얻는 것

(4) Gradient 를 계산하는 2가지 방법
- Analytic 해석적 방법 👉 위에서 설명했던 computational graph 를 통한 Chain rule 기반 계산 방식으로 빠르게 연산이 가능하나 계산 과정에서 실수가 있을 수 있다는 단점이 존재
- 참고. pytorch 나 tensorflow 등의 딥러닝 프레임워크 발달 이전에는 직접 Gradient 를 계산하여 가중치를 업데이트 했었음
- Numerical 수치적 방법 : 쉽게 미분값을 얻을 수 있지만 연산량이 매우 많음

- (hybrid) : 특정 weight 에 대한 미분이 잘 계산되었는지 확인하기 위해 수치적 방법으로 check 하는 방식을 사용하기도 한다.
3. Tips for NN
(1) Regularization to prevent overfitting

- 과적합을 방지하기 위해 feature 들이 많은 데이터셋의 경우 θ 에 대한 규제를 추가한다.
(2) Vectorization
- for loop 을 사용해서 각 element 에 일일히 접근하는 연산보다 행렬 & 벡터 기반의 연산의 속도가 훨씬 빠르다.
(3) Nonlinearities

- ReLU 와 같은 비선형 활성화 함수를 사용하는 것이 좋다.
(4) Initialization
- 가중치를 small random value 로 초기화한다.
- 은닉층 & 출력층의 bias 는 0으로 초기화 한다.
- 다른 Weight들은 너무 크지도, 작지도 않은 범위 내의 Uniform distribution에서 임의로 추출한다.
(5) Optimizers
- SGD 을 보통 사용
- 복잡한 신경망일 땐 Adaptive 최적화 알고리즘을 사용하는 것이 좋다.
- Adaptive Optimizer 👉 계산된 Gradient 에 대한 정보를 축적하며 파라미터를 조절하는 방식
- Adagrad, RMSprop, Adam, SparseAdam
(6) Learning Rates
- 0.001 정도
- 값이 너무 크면 모델이 발산, 너무 작으면 업데이트양이 작아 학습이 느려짐
- 학습을 진행 시키면서 학습률을 감소시키는 것이 성능 향상에 도움이 됨!
'1️⃣ AI•DS > 📗 NLP' 카테고리의 다른 글
| [cs224n] 6강 내용 정리 (0) | 2022.03.24 |
|---|---|
| [cs224n] 5강 내용 정리 (0) | 2022.03.22 |
| NLP deep learning (0) | 2022.03.15 |
| [cs224n] 3강 내용 정리 (0) | 2022.03.14 |
| [cs224n] 2강 내용 정리 (0) | 2022.03.14 |




댓글