1️⃣ 시계열 문제
🔹 시계열 분석이란
↪ 시간에 따라 변하는 데이터를 사용해 추이를 분석하는 것으로 주가/환율변동, 기온/습도변화 등이 대표적인 시계열 분석에 해당한다.
↪ 추세파악, 향후전망 예측에 시계열 분석을 사용한다.
🔹 시계열 형태
↪ 데이터 변동 유형에 따라 구분할 수 있다.
| 불규칙변동 | 예측 불가능하고 우연적으로 발생하는 변동. 전쟁, 홍수, 지진, 파업 등 |
| 추세변동 | GDP, 인구증가율 등 장기적인 변화 추세를 의미한다. 장기간에 걸쳐 지속적으로 증가, 감소하거나 일정 상태를 유지하려는 성격을 띈다. |
| 순환변동 | 2~3년 정도의 일정한 기간을 주기로 순환적으로 나타나는 변동 |
| 계절변동 | 계절적인 영향과 사회적 관습에 따라 1년 주기로 발생하는 것을 의미 |
🔹 시계열 데이터
↪ 규칙적 시계열 vs 불규칙적 시계열
• 규칙적 시계열 : 트렌드와 분산이 불변하는 데이터
• 불규칙적 시계열 : 트렌드 혹은 분산이 변화하는 시계열 데이터
▸ 시계열을 잘 분석한다는 것은 불규칙성을 갖는 시계열 데이터에 특정한 기법이나 모델을 적용하여 규칙적인 패턴을 찾거나 예측하는 것을 의미한다.
↪ AR,MA,ARMA,ARIMA,딥러닝 기법 등이 사용된다.
2️⃣ AR, MA, ARMA, ARIMA
↪ 시계열 분석은 일반적인 머신러닝에서 "시간" 을 독립변수로 사용한다는 특징이 있다.
🔹 AR 모델

• Auto Regressive 자기회귀 모델
• 이전 관측값이 이후 관측값에 영향을 준다는 아이디어에서 시작한 것으로 이전 데이터의 '상태' 에서 현재 데이터의 상태를 추론한다.
• ① 번 부분 : 시계열 데이터의 현재시점
• ② 번 부분 : 과거가 현재에 미치는 영향을 나타내는 모수에 시계열 데이터의 과거 시점을 곱한 것
• ③ 번 부분 : 백색잡음, 시계열 분석에서의 오차항
🔹 MA 모델

• Moving average 이동평균 모델
• 트렌드 (평균 or 시계열 그래프에서 y 값) 가 변화하는 상황에 적합한 회귀모델
• window 라는 개념을 사용하여 그 크기만큼 이동한다 하여 이동평균 모델이라 부른다.
• ② 번 부분 : 매개변수 θ 에 과거 시점의 오차를 곱한 것으로, 이전 데이터의 오차에서 현재 데이터의 상태를 추론한다.
🔹 ARMA 모델
• 자기회귀 이동평균 모델, 주로 연구기관에서 사용한다.
• AR, MA 두 가지 관점에서 과거의 데이터를 사용한다.

🔹 ARIMA 모델
• 자기 회귀 누적(integrated) 이동 평균 모델 : AR과 MA 를 모두 고려하는 모형인데, ARMA 와 달리 과거 데이터의 선형적 관계 뿐 아니라 추세까지 고려한 모델이다.
from statsmodels.tsa.arima_model import ARIMA
• ARIMA(data, order = (p,d,q))
▸p : 자기회귀차수
▸d : 차분차수
▸q : 이동평균차수
▸model.fit() : 훈련
▸model.forecast() : 예측
3️⃣ RNN
🔹 Recurrent Neural Network

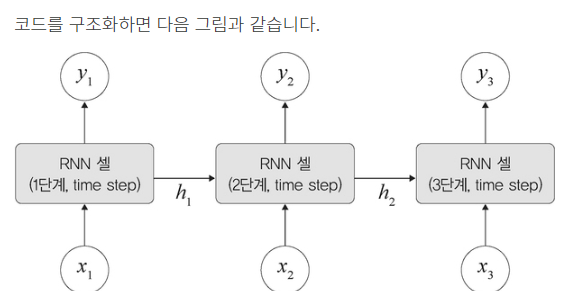
• 이전 은닉층이 현재 은닉층의 입력이 되면서 반복되는 순환 구조를 갖는다.
• 이전의 정보를 기억하고 있기 때문에 최종적으로 남겨진 기억은 모든 입력 전체를 요약한 정보가 된다.
• 음성인식, 단어의 의미판단 및 대화 등의 자연어처리에 활용되거나 손글씨, 센서데이터 등의 시계열 데이터 처리에 활용된다.
🔹 다양한 유형의 RNN
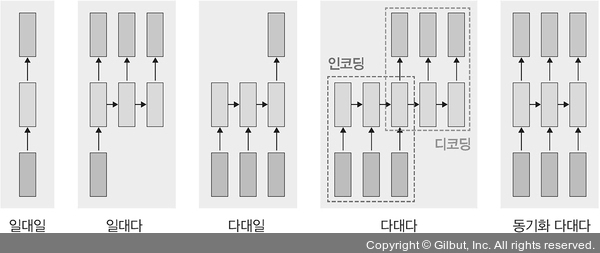
• 일대다 : 입력이 하나고 출력이 다수인 구조이다. 이미지를 입력해, 이미지에 대한 설명을 문장으로 출력하는 이미지 캡션이 대표적인 사례이다.
• 다대일 : 입력이 다수고 출력이 하나인 구조로, 문장을 입력해 긍/부정을 출력하는 감성분석기에서 사용되는 구조이다.
# 다대일 모델
self.em = nn.Embedding(len(TEXT.vocab.stoi), embedding_dim) # 임베딩 처리
self.rnn = nn.RNNCell(input_dim, hidden_size) # RNN 적용
self.fc1 = nn.Linear(hidden_size, 256) # 완전연결층
self.fc2 = nn.Linear(256,3) # 출력층
• 다대다 : 입력과 출력이 다수인 구조, 자동번역기가 대표적인 사례이다. 파이토치에서는 아래의 한줄 코드로 간단하게 구현이 가능하나, 파이토치에서는 seq2seq 구조를 사용하는 방식으로 구현된다.
keras.layers.SimpleRNN(100, return_sequences = True, name='RNN')
↪ 텐서플로우에서는 return_sequences =True 옵션으로 시퀀스를 리턴할 수 있도록 한다
▸ 파이토치로 구현
# 다대다 모델
Seq2Seq(
(encoder) : Encoder(
(embedding) : Embedding(7855,256)
(rnn) : LSTM(256, 512, num_layers=2, dropout=0.5)
(dropout) : Dropout(p=0.5, inplace=False)
)
(decoder) : Decoder(
(embedding) : Embedding(5893,256)
(rnn) : LSTM(256, 512, num_layers=2, dropout=0.5)
(fc_out) : Linear(in_features=512, out_features=5893, bias = True)
(dropout) : Dropout(p=0.5, inplace=False)
)
)
• 동기화 다대다 : 입력과 출력이 다수인 구조로, 프레임 수준의 비디오 분류가 대표적인 사례이다.
🔹 RNN 계층과 셀
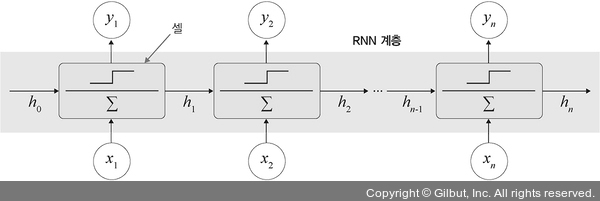
• Cell 셀 : 오직 하나의 단계 time step 만 처리하는 단위를 의미한다. 실제 계산에서 사용되는 RNN 계층의 구성요소로 단일 입력과 과거 상태를 가져와 출력과 새로운 상태를 생성한다.
↪ 셀 유형
| nn.RNNCell | Simple RNN 계층에 대응되는 RNN 셀 |
| nn.GRUCell | GRU 계층에 대응되는 GRU 셀 |
| nn.LSTMCell | LSTM 계층에 대응되는 LSTM 셀 |
• Layer 계층 : 셀을 래핑해 동일한 셀을 여러 단계에 적용한다.
👀 파이토치에서는 레이어와 셀을 분리해서 규현하는 것이 가능하다.
4️⃣ RNN 구조
🔹 구조

• x(t-1) 에서 h(t-1) 을 얻고, 다음 단계에서 h(t-1) 과 x(t) 를 사용해 과거 정보와 현재 정보를 모두 반영한다.
• 가중치
↪ Wxh : 입력층에서 은닉층으로 전달되는 가중치
↪ Whh : t 시점의 은닉층에서 t+1 시점의 은닉층으로 전달되는 가중치
↪ Why : 은닉층에서 출력층으로 전달되는 가중치
▸ 모든 시점에 가중치 값은 동일하게 적용된다.
🔹 t 시점의 RNN 계산
① 은닉층 계산
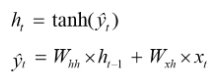
↪ 현재 입력값과 이전 시점의 은닉층을 가중치 계산한 후, 하이퍼볼릭 탄젠트 활성화 함수를 사용해 현재 시점의 은닉층을 계산한다.
② 출력층

↪ 출력층 가중치와 현재 은닉층을 곱하여 소프트맥스 함수를 적용한다.
③ 순방향 학습 및 오차 E
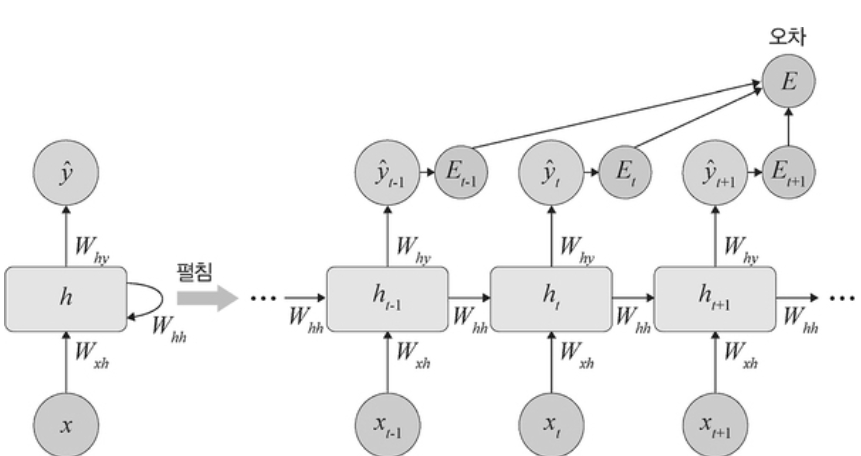
↪ 심층 신경망에서 일반적인 feedforward 전방향 학습과 달리 각 단계 t 마다 오차를 측정한다.
④ 역전파
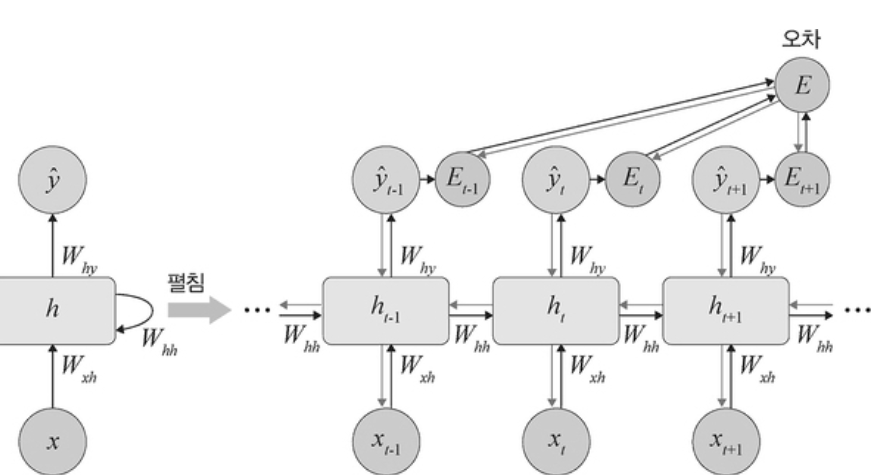
↪ RNN 에서는 BPTT (backpropagation through time) 를 이용하여 모든 단계마다 처음부터 끝까지 역전파한다.
↪ 각 단계마다 오차를 측정하고 이전 단계로 전달되는 것을 의미하는데, ③ 과정에서 구한 오차를 이용해 가중치와 bias 를 업데이트 한다.
↪ 기울기 소멸문제 : 오차가 멀리 전파될때 계산량이 많아지고 전파되는 양이 점차 적어지는 문제점
🔹 RNN 셀 구현 : IMDB 영화리뷰 긍부정 예제
① 데이터 준비
(1) 라이브러리 가져오기
pip install torchtext==0.10.1 # 런타임 다시시작
import torch
import torchtext
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import time
▸ torchtext : NLP 분야에서 사용하는 데이터로더로, 파일 가져오기, 토큰화, 단어 집합 생성, 인코딩, 단어벡터 생성 등의 작업을 지원한다.
▸ 용어정리
✔ 토큰화 : 텍스트를 문장이나 단어로 분리하는 것
✔ 단어집합 vocabulary : 중복을 제거한 텍스트의 총 단어의 집합
✔ 인코딩 : 사람의 언어인 문자를 컴퓨터의 언어인 숫자로 바꾸는 작업
✔ 단어벡터 : 단어의 의미를 나타내는 숫자 벡터
(2) 데이터 전처리
from torchtext.legacy.data import Field
start = time.time()
TEXT = torchtext.legacy.data.Field(lower = True, fix_length = 200, batch_first=False)
LABEL = torchtext.legacy.data.Field(sequential = False)
▸ torchtext.legacy.data.Field
✔ lower = True : 대문자를 모두 소문자로 변경
✔ fix_length = 200 : 고정된 길이의 데이터를 얻을 수 있다. 여기처럼 200으로 고정한다면 데이터의 길이를 200으로 맞추는 것이고, 만약 200보다 짧은 길이라면 패딩 작업을 통해 이에 맞추어 준다.
✔ batch_first = True : 신경망에 입력되는 텐서의 첫번째 차원의 값이 배치크기가 될 수 있도록 한다. 원래 모델의 네트워크로 입력되는 데이터는 (seq_len, batch_size, hidden_size) 형태인데, 이 옵션을 True 로 설정하게 되면 (batch_size, seq_len, hidden_size) 형태로 변경된다.
⁕ 파이토치는 각 계층별 데이터 형태를 맞추는 것에서 시작하여 끝날정도로 매우 중요하기 때문에 입력층, 은닉층 데이터들에 대해 각 숫자가 의미하는 것을 이해해야 한다.
✔ sequential = False : 데이터에 순서가 있는지 나타내는 것으로 기본값은 True 이다. 예제의 레이블은 긍부정 값만 가지므로 False 로 설정한다.
(3) 데이터셋 준비
from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
▸ splits : 전체 데이터셋을 TEXT 와 LABEL 로 분할하여, TEXT 는 훈련용도로 LABEL 은 테스트 용도로 사용한다.
▸ 훈련 데이터는 text 와 label 을 가지는 사전형식으로 구성되어 있다. { 'text' : ['A','B', ..] , 'label' : 'pos' }
② 데이터 전처리
(1) 텍스트 전처리
# 데이터 전처리
import string
for example in train_data.examples : # 데이터셋 내용 확인하기 : examples
text = [x.lower() for x in vars(example)['text']] # 소문자로 변경
text = [x.replace("<br","") for x in text] # "<br" 을 "" 공백으로 변경
text = [''.join(c for c in s if c not in string.punctuation) for s in text] # 구두점 제거
text = [s for s in text if s] # 공백제거
vars(example)['text'] = text
▸ 불필요한 문자 제거, 공백처리 등이 포함된다.
(2) 훈련과 검증 데이터셋 분리
import random
train_data , valid_data = train_data.split(random_state = random.seed(0), split_ratio = 0.8)
▸ random_state : 데이터 분할 시 데이터가 임의로 섞인 상태에서 분할된다. seed 값을 사용하면 동일한 코드를 여러번 수행해도 동일한 값의 데이터를 반환한다.
(3) 단어집합 만들기 : build.vocab()
#단어집합 만들기
TEXT.build_vocab(train_data, max_size = 10000, min_freq = 10, vectors=None)
LABEL.build_vocab(train_data)
▸ 단어집합 : IMDB 데이터셋에 포함된 단어들을 이용해 하나의 딕셔너리와 같은 집합을 만드는 것으로 단어들의 중복은 제거된 상태에서 진행된다.
▸ max_size : 단어 집합의 크기로 단어 집합에 포함되는 어휘 수
▸ min_freq : 특정 단어의 최소 등장 횟수로, 훈련 데이터셋에서 특정 단어가 최소 10번 등장한 것만 단어집합에 포함하겠다는 의미이다.
▸ vectors : 임베딩 벡터를 지정할 수 있다. Word2Vec, Glove 등이 있으며 파이토치에서도 nn.embedding() 을 통해 랜덤한 숫자값으로 변환하여 가중치를 학습하는 방법을 제공한다.
print('TEXT 단어사전의 토큰 개수(중복없음):', len(TEXT.vocab))
# 10002
print('LABEL 단어사전의 토큰 개수(중복없음):', len(LABEL.vocab))
# 3 : 원래 긍정과 부정 2개가 출력되어야 하는데 한번 확인해볼 필요가 있음
(4) 단어 집합 확인
# 테스트 데이터셋의 단어집합 확인
print(LABEL.vocab.stoi)
defaultdict(<bound method Vocab._default_unk_index of <torchtext.legacy.vocab.Vocab object at 0x7f134796de10>>, {'<unk>': 0, 'pos': 1, 'neg': 2})
→ <unk> : 사전에 없는 단어를 의미
(5) 데이터셋 메모리로 가져오기
# 데이터셋 메모리로 가져오기
BATCH_SIZE = 64
device = torch.device('cuda:0' if torch.cude.is_available() else 'cpu')
embedding_dim = 100 # 각 단어를 100차원으로 조정(임베딩 계층을 통과한 후 각 벡터의 크기)
hidden_size = 300
train_iterator, valid_iterator, test_iterator = torchtext.legacy.data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device
)
▸ hidden size : 은닉층의 유닛(뉴런) 개수를 정한다. 일반적으로 비선형 문제를 좀 더 학습할 수 있도록, 은닉층의 유닛 개수를 늘리기보단, 계층 자체의 개수를 늘리는 것이 성능에 더 좋다. 최적의 은닉층 개수와 유닛 개수를 찾는 것은 매우 어려운 일이기 때문에 과적합이 발생하지 않도록, 실제 필요한 개수보다 더 많은 층과 유닛을 구성해 개수를 조정해 나가는 방식을 사용한다.
▸BucketIterator : dataloader 와 비슷하게 배치 크기 단위로 값을 차례로 꺼내어 메모리로 가져오고 싶을 때 사용한다. 비슷한 길이의 데이터를 한 배치에 할당하여 패딩을 최소화 시켜준다.
③ 워드 임베딩 및 RNN 셀정의
✔ 앞서 단어집합 생성 과정에서 vectors=none 으로 설정하였으므로 임베딩이 진행되지 않았기 때문에, nn.Embedding() 을 이용해 임베딩 처리를 시켜준다.
class RNNCell_Encoder(nn.Module) :
def __init__(self, input_dim, hidden_size) :
super(RNNCell_Encoder, self).__init__()
self.rnn = nn.RNNCell(input_dim, hidden_size) # RNN 셀 구현
def forward(self, inputs) : # inputs 는 입력 시퀀스로 (시퀀스 길이, 배치, 임베딩) 형태를 가짐
bz = inputs.shape[1] # 배치를 가져온다.
ht = torch.zeros((bz, hidden_size)).to(device) # 배치와 은닉층 뉴런의 크기를 0으로 초기화
for word in inputs :
ht = self.rnn(word, ht) # 재귀적으로 발생하는 상태 값 처리
return ht
▸ nn.RNNCell
- input_dim : 훈련 데이터셋의 feature 개수로 (batch, input_size) 형태를 갖는다. (배치, 입력 데이터 칼럼개수)
- hidden_size : 은닉층의 뉴런 개수로 (batch, hidden_size) 형태를 갖는다.
▸ ht = self.rnn(word, ht)
- ht : 현재상태
- word : 현재의 입력벡터로 Xi 를 의미, (batch, input_size) 의 형태를 갖는다.
- ht : 이전상태를 의미하며 (batch, hidden_size) 형태를 갖는다.
class Net(nn.Module) :
def __init__(self) :
super(Net, self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi), embedding_dim) # 임베딩 처리
self.rnn = RNNCell_Encoder(embedding_dim, hidden_size)
self.fc1 = nn.Linear(hidden_size, 256)
self.fc2 = nn.Linear(256,3)
def forward(self,x) :
x = self.em(x)
x = self.rnn(x)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
▸ nn.Embedding : 임베딩 처리를 위한 구문으로 임베딩을 할 단어 수 (단어집합크기) 와 임베딩할 벡터의 차원을 지정해준다.
④ 옵티마이저와 손실함수 정의
model = Net()
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
▸ nn.CrossEntropyLoss : 다중분류에 사용되는 손실함수
⑤ 모델 학습
▸ 모델 학습을 위한 함수를 정의
# 모델 학습
def training(epoch, model, trainloader, validloader) :
correct = 0
total = 0
running_loss = 0
model.train()
for b in trainloader :
x,y = b.text, b.label # text 와 label 을 꺼내온다.
x,y = x.to(device) , y.to(device) # 데이터가 CPU 를 사용할 수 있도록 장치 지정
y_pred = model(x)
loss = loss_fn(y_pred, y) # CrossEntropyLoss 손실함수 이용해 오차 계산
optimizer.zero_grad() # 변화도 (gradients) 초기화
loss.backward() # 역전파
optimizer.step() # 업데이트
with torch.no_grad() : # autograd를 끔으로써 메모리 사용량을 줄이고 연산 속도를 높임
y_pred = torch.argmax(y_pred, dim =1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset)
# 누적된 오차를 전체데이터셋으로 나누어 에포크 단계마다 오차를 구한다.
epoch_acc = correct/total
valid_correct = 0
valid_total = 0
valid_running_loss = 0
model.eval() # evaluation 과정에서 사용하지 않아야 하는 layer들을 알아서 off 시키도록 하는 함수
with torch.no_grad() : # evaluation 혹은 validation 에서는 no_grad 를 쓴다.
for b in validloader :
x,y = b.text, b.label
x,y = x.to(device) , y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred,y)
y_pred = torch.argmax(y_pred, dim =1)
valid_correct += (y_pred == y).sum().item()
valid_total += y.size(0)
valid_running_loss += loss.item()
epoch_valid_loss = valid_running_loss / len(validloader.dataset)
epoch_valid_acc = valid_correct / valid_total
print('epoch :', epoch,
'loss :', round(epoch_loss,3),
'accuracy : ', round(epoch_acc,3),
'valid_loss :', round(epoch_valid_loss,3),
'valid_accuracy :', round(epoch_valid_acc,3)
)
return epoch_loss, epoch_acc, epoch_valid_loss, epoch_valid_acc
▸ 모델 학습
# 모델 학습 진행
epochs = 5
train_loss = []
train_acc = []
valid_loss = []
valid_acc = []
for epoch in range(epochs) :
epoch_loss, epoch_acc, epoch_valid_loss, epoch_valid_acc = training(epoch,
model,
train_iterator,
valid_iterator)
train_loss.append(epoch_loss) # 훈련 데이터셋을 모델에 적용했을 때의 오차
train_acc.append(epoch_acc) # 훈련 데이터셋을 모델에 적용했을 때 정확도
valid_loss.append(epoch_valid_loss) # 검증 데이터셋을 모델에 적용했을 때 오차
valid_acc.append(epoch_valid_acc) # 검증 데이터셋을 모델에 적용했을 때 정확도
end = time.time()
#print(end-start)
↪ 에포크가 5라 정확도는 낮지만 학습과 검증 데이터셋에 대한 오차가 유사하므로 과적합은 발생하지 않음을 확인해볼 수 있다.
⑥ 모델 예측
▸ 테스트셋에 대한 모델 예측함수 정의
def evaluate(epoch, model, testloader) :
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad() :
for b in testloader :
x,y = b.text, b.label
x,y = x.to(device) , y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss/len(testloader.dataset)
epoch_test_acc = test_correct/test_total
print('epoch : ', epoch,
'test_loss : ', round(epoch_test_loss,3),
'test_accuracy :', round(epoch_test_acc,3))
return epoch_test_loss, epoch_test_acc
▸ 테스트셋에 대한 모델 예측 결과 확인
epochs = 5
test_loss = []
test_acc = []
for epoch in range(epochs) :
epoch_test_loss, epoch_test_acc = evaluate(epoch, model, test_iterator)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
end = time.time()
더 높은 정확도를 원한다면 에포크 횟수를 늘리면 된다.
🔹 RNN 계층 구현
⁕ RNN 셀 네트워크와 크게 다르진 않다. 미세한 차이 위주로 살펴보기!
① 데이터 로드 및 전처리 (RNN 셀 과정과 같으므로 생략)
② 모델 네트워크 정의
▸ 변수값 지정
vocab_size = len(TEXT.vocab) # 영화 리뷰에 대한 텍스트 길이
n_classes = 2 # 긍정 부정
▸ RNN layer 네트워크
class BasicRNN(nn.Module) :
def __init__(self, n_layers, hidden_dim, n_vocab, embed_dim, n_classes, dropout_p=0.2) :
super(BasicRNN,self).__init__()
self.n_layers = n_layers # RNN 계층에 대한 개수
self.embed = nn.Embedding(n_vocab, embed_dim) # 워드 임베딩 적용
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout_p) # 드롭아웃 적용
self.rnn = nn.RNN(embed_dim, self.hidden_dim, num_layers = self.n_layers, batch_first = True)
self.out = nn.Linear(self.hidden_dim, n_classes)
def forward(self,x) :
x = self.embed(x) # 문자를 숫자/벡터로 변환
h_0 = self._init_state(batch_size = x.size(0)) # 최초 은닉상태의 값을 0으로 초기화
x,_ = self.rnn(x, h_0) # RNN 계층
h_t = x[:,-1,:] # 모든 네트워크를 거쳐 가장 마지막에 나온 단어의 임베딩값 (마지막 은닉상태의 값)
self.dropout(h_t)
logit = torch.sigmoid(self.out(h_t))
return logit
def _init_state(self, batch_size =1) :
weight = next(self.parameters()).data # 모델 파라미터 값을 가져와 weight 에 저장
return weight.new(self.n_layers, batch_size, self.hidden_dim).zero_()
# 크기가 (계층의 개수, 배치크기, 은닉층의 뉴런개수) 인 은닉상태의 텐서를 생성해 0으로 초기화한 후 반환
↪ nn.RNN
- embed_dim : 훈련 데이터셋의 특성(칼럼) 개수
- hidden_dim : 은닉 계층의 뉴런 개수
- num_layers : RNN 계층의 개수
③ 손실함수와 옵티마이저 설정
model = BasicRNN(n_layers = 1, hidden_dim = 256, n_vocab = vocab_size, embed_dim = 128, n_classes = n_classes, dropout_p = 0.5)
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
④ 모델 훈련 및 평가
def train(model, optimizer, train_iter):
model.train()
for b, batch in enumerate(train_iter):
x, y = batch.text.to(device), batch.label.to(device)
y.data.sub_(1)
# 레이블이 긍정(2), 부정(1) 로 되어있기 때문에 각각 1과 0으로 값을 바꿔주기 위함
optimizer.zero_grad()
logit = model(x)
loss = F.cross_entropy(logit, y)
loss.backward()
optimizer.step()
if b % 50 == 0:
print("Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(e,
b * len(x),
len(train_iter.dataset),
100. * b / len(train_iter),
loss.item()))
def evaluate(model, val_iter):
model.eval()
corrects, total, total_loss = 0, 0, 0
for batch in val_iter:
x, y = batch.text.to(device), batch.label.to(device)
y.data.sub_(1)
logit = model(x)
loss = F.cross_entropy(logit, y, reduction = "sum")
total += y.size(0)
total_loss += loss.item()
corrects += (logit.max(1)[1].view(y.size()).data == y.data).sum()
avg_loss = total_loss / len(val_iter.dataset)
avg_accuracy = corrects / total
return avg_loss, avg_accuracy
BATCH_SIZE = 100
LR = 0.001
EPOCHS = 5
for e in range(1, EPOCHS + 1):
train(model, optimizer, train_iterator)
val_loss, val_accuracy = evaluate(model, valid_iterator)
print("[EPOCH: %d], Validation Loss: %5.2f | Validation Accuracy: %5.2f" % (e, val_loss, val_accuracy))
test_loss, test_acc = evaluate(model,test_iterator)
print("Test Loss: %5.2f | Test Accuracy: %5.2f" % (test_loss, test_acc))
정확도가 그닥 높지 않다. 에포크를 증가시켜보거나, 다른 모델로 변경해본다. 여러 유형의 모델을 적용한 후 가장 결과가 좋은 모델을 선택한다. 또한 하이퍼파라미터 (배치크기, 학습률 등) 를 튜닝해가는 과정이 필요하다.
'1️⃣ AI•DS > 📒 Deep learning' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] 자연어처리를 위한 임베딩 (0) | 2022.12.30 |
|---|---|
| [딥러닝 파이토치 교과서] 5장 합성곱 신경망 Ⅰ (0) | 2022.10.06 |
| [딥러닝 파이토치 교과서] 4장 딥러닝 시작 (1) | 2022.10.04 |
| [딥러닝 파이토치 교과서] 2장 실습 환경 설정과 파이토치 기초 (1) | 2022.09.23 |
| [딥러닝 파이토치 교과서] 1장 머신러닝과 딥러닝 (0) | 2022.09.22 |




댓글