👀 임베딩
• 임베딩 : 사람의 언어를 컴퓨터가 이해할 수 있는 언어 (숫자) 형태인 벡터로 변환한 결과
• 임베딩의 역할
↪ 단어 및 문장 간 관련성 계산
↪ 의미적 혹은 문법적 정보의 함축 (ex. 왕-여왕, 교사-학생)
① 희소표현 기반 임베딩 : 원핫인코딩
• Sparse representation : 대부분의 값이 0으로 채워져 있는 경우로 대표적인 방법이 원핫인코딩
• 원핫인코딩 : 단어 N 개를 각각 N 차원의 벡터로 표현하는 방식

from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
onehot_encoder = preprocessing.OneHotEncoder()
a = label_encoder.fit_transform(data['colunn'])
• 원핫인코딩의 단점
↪ 수학적인 의미에서 원핫벡터는 하나의 요소만 1을 가지고 나머지는 0을 가지는 희소벡터를 가지고 있기 때문에 두 단어에 대한 벡터 내적을 구하면 0을 가지므로 직교하게 된다. 즉 단어끼리 관계성 (유의어, 반의어) 없이 서로 독립적인 관계가 된다.
↪ 하나의 단어를 표현하는데 말뭉치에 있는 단어 개수만큼 차원이 존재하므로 차원의 저주 문제가 발생한다.
👉 대안책 : 신경망에 기반하여 단어를 벡터로 바꾸는 Word2Vec, GloVe, FastText 방법론이 주목을 받고있음
② 횟수기반 임베딩 : CountVector, TF-IDF
• 단어가 출현한 빈도를 고려해 임베딩 하는 방법
(1) Count vector
• 문서집합에서 단어를 토큰으로 생성하고 각 단어의 출현 빈도수를 이용해 인코딩해 벡터를 만드는 방법
• 토크나이징과 벡터화가 동시에 가능
문서를 토큰 리스트로 변환 → 각 문서에서 토큰의 출현 빈도를 카운트 → 각 문서를 인코딩하고 벡터로 변환
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is last chance.',
'and if you do not have this chance.',
'you will never get any chance.',
'will you do get this one?',
'please, get this chance',
]
vect = CountVectorizer()
vect.fit(corpus)
vect.vocabulary_ # 단어사전
# countvector 적용 결과를 배열로 변환하기
vect.transform(['you will never get any chance']).toarray()
(2) TF-IDF
• 정보검색론에서 가중치를 구할 때 사용되는 알고리즘
• Term Frequency 단어빈도 : 문서 내에서 특정 단어가 출현한 빈도
• Inverse Document Frequency 역문서 빈도 : 한 단어가 전체 문서에서 얼마나 공통적으로 많이 등장하는지 나타내는 값 (특정 단어가 나타난 문서 개수) 인 DF 의 역수 값

↪ 키워드 검색을 기반으로 하는 검색엔진, 중요 키워드 분석, 검색 엔진에서 검색 결과의 순위를 결정하는 상황에서 사용된다.
from sklearn.feature_extraction.text import TfidfVectorizer
doc = ['I like machine learning', 'I love deep learning', 'I run everyday']
tfidf_vectorizer = TfidfVectorizer(min_df = 1)
# min_df : 최소 빈도값을 설정해주는 파라미터로, DF 의 최소값을 설정 (특정 단어가 나타내는 문서의 수)하여
## 해당 값보다 작은 DF 를 가진 단어들은 단어사전에서 제외한다.
tfidf_matrix = tfidf_vectorizer.fit_transform(doc)
TF-IDF 값은 특정 문서 내에서 단어의 출현빈도가 높거나 전체 문서에서 특정 단어가 포함된 문서가 적을수록 값이 높다. 따라서 이 값을 활용해 문서에 나타나는 흔한 단어 (a, the) 들을 걸러내거나 특정 단어에 대한 중요도를 찾을 수 있다.
③ 예측기반 임베딩
• 신경망 구조를 이용해 특정 문맥에서 어떤 단어가 나올지 "예측" 하면서 단어를 벡터로 만드는 방식
(1) Word2Vec
• 텍스트의 각 단어마다 하나씩 일련의 벡터를 출력한다.
• word2vec 의 출력 벡터가 2차원 그래프에 표시될 때 의미론적으로 유사한 단어의 벡터는 서로 가깝게 표현된다. 즉, 특정 단어의 동의어를 찾을 수 있다.
import gensim
from gensim.models import Word2Vec
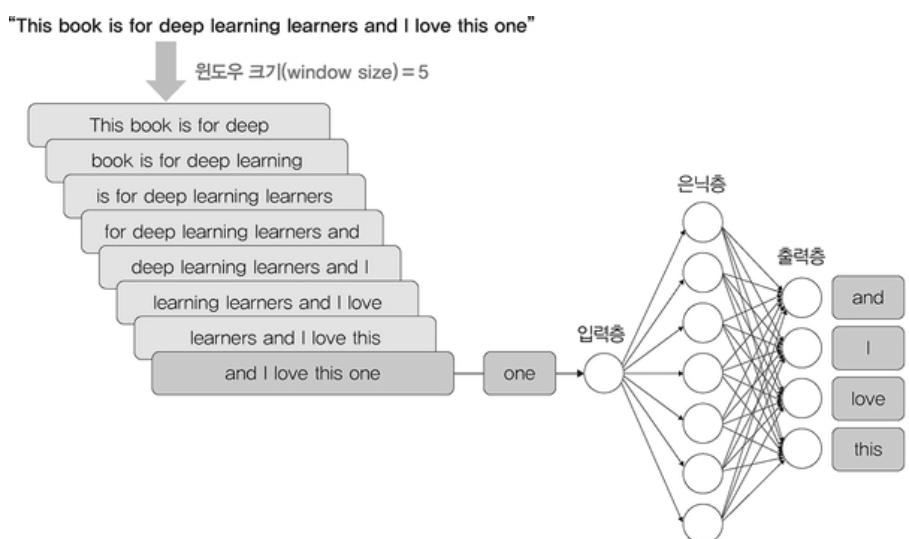
→ 은닉층에는 각 단어에 대한 가중치가 포함되어 있다.
🔹 CBOW
• 주변단어로부터 중심 단어를 예측하는 방법
• 가중치 행렬은 모든 단어에서 공통으로 사용
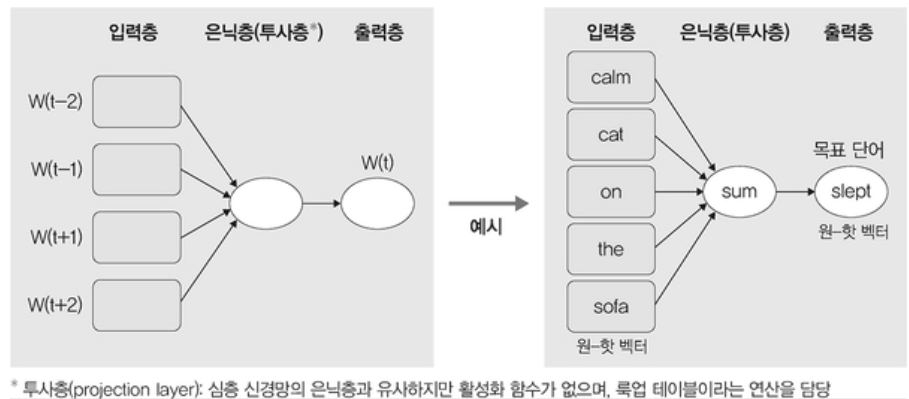
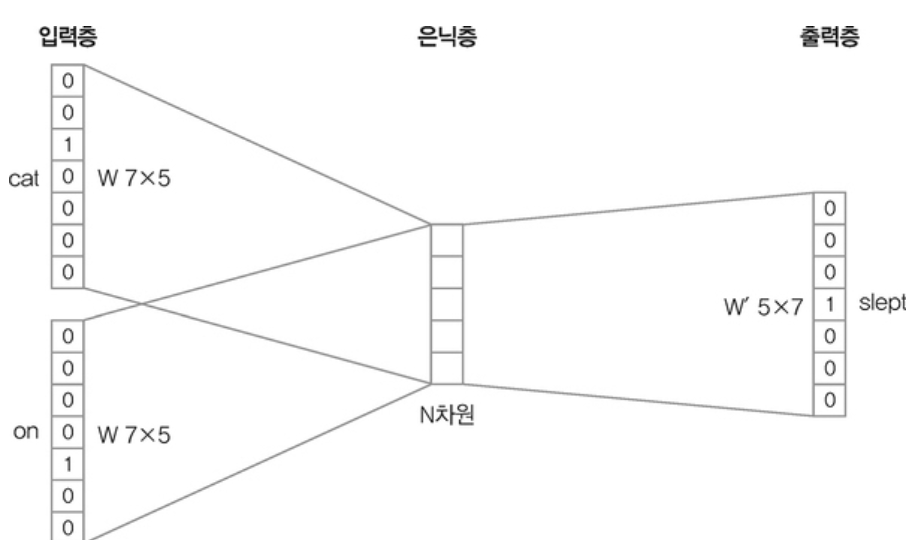
↪ 크기가 N 인 은닉층 : N 은 입력 텍스트를 임베딩한 벡터 크기
↪ V : 단어집합의 크기
↪ 은닉층에 임베딩된 벡터 차원을 단어의 벡터로 사용하는 것!
gensim.models.Word2Vec(data, min_count=1, size = 100, window = 5, sg = 0)
# data : 토큰화된 문서-단어 리스트
# min_count : 단어에 대한 최소 빈도수 제한 (빈도가 작은 단어는 학습X)
# size : 워드 벡터의 특징값. 임베딩된 벡터의 차원
# window : 컨텍스트 윈도우의 크기
# sg = 0 : CBOW, sg = 1 : skip-gram
🔹 Skip-gram
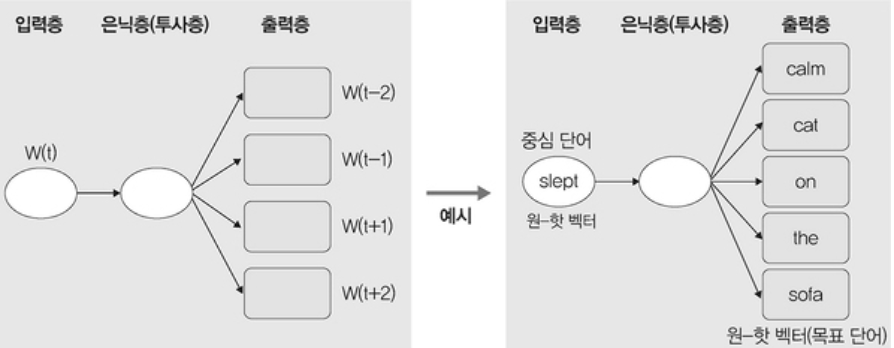
• 중심단어로부터 주변 단어를 예측하는 방법
• 입력 단어 주변의 k 개의 단어를 문맥으로 보고 예측 모형을 만든다.
gensim.models.Word2Vec(data, min_count=1, size=100, window=5, sg=1)
# 단어 유사도 계산
model2.wv.similarity('peter','wendy')
데이터 성격, 분석에 대한 접근 방법 및 도출하고자 하는 결론 등을 종합적으로 고려해 필요한 라이브러리를 사용한다.
(2) Fasttext
• 패스트텍스트
Word2vec 의 단점을 보완해 개발된 임베딩 알고리즘이다. Word2vec 은 분산표현을 이용해 분산분포가 유사한 단어들에 비슷한 벡터값을 할당하는 방법을 사용하므로 사전에 없는 단어에 대해서는 벡터 값을 얻을 수 없다는 단점과, 자주 사용되지 않는 단어에 대해서 학습이 불안정하다는 단점이 있다.
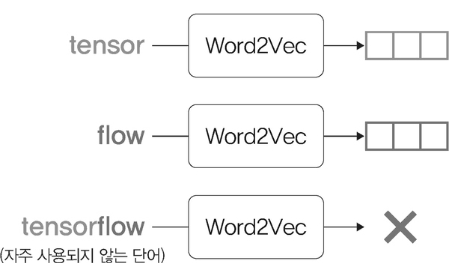
FastText 는 노이즈에 강하며 새로운 단어에 대해서는 "형태적 유사성" 을 고려한 벡터 값을 얻어 많이 사용되는 알고리즘 중 하나다.

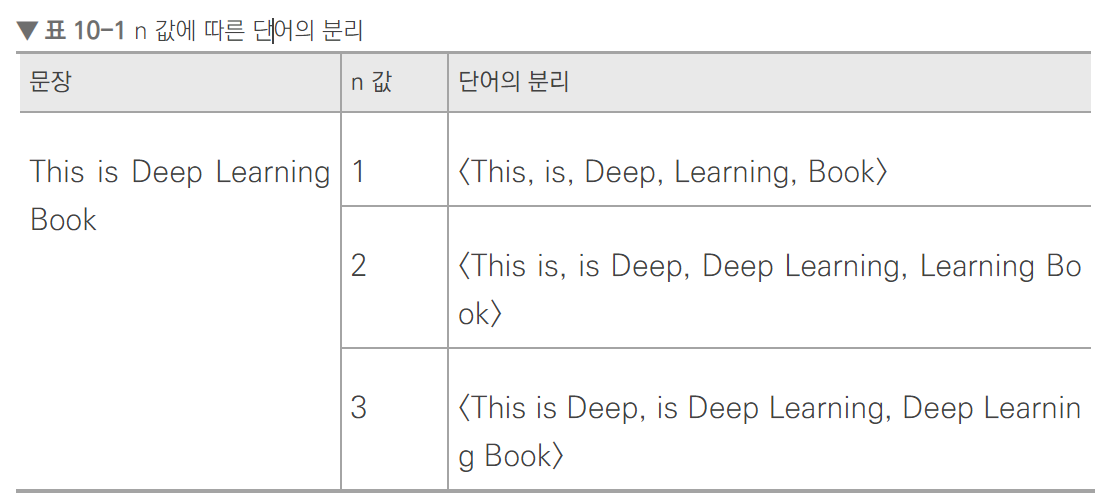
FastText 는 사전에 없는 단어에 대해 벡터 값을 부여하기 위해, 주어진 문서의 각 단어를 n-gram 으로 표현하는 방식을 채택한다. 인공 신경망을 이용해 학습이 완료된 후 데이터셋의 모든 단어를 각 n-gram 에 대해 임베딩한다. 따라서 사전에 없는 단어가 등장하면, n-gram 으로 분리된 subword 와 유사도를 계산해 의미를 유추할 수 있다.
from gensim.test.utils import common_texts
from gensim.models import FastText
model = FastText(data, size = 4, window = 3, min_count = 1)
# data : word lists
# window : 고려할 앞뒤 폭 (앞뒤 세 단어)
# min_count : 단어에 대한 최소 빈도수 제한
# 단어 간 유사도 계산
model.wv.similarity('peter', 'wendy')
• 사전훈련된 패스트텍스트 모델 사용 예제
위키피디아 데이터를 사전 학습한 한국어 모델을 내려받아 사용한다.
from __future__ import print_function
from gensim.models import KeyedVectors # gensim 을 이용해 사전학습된 모델을 이용
model_kr = KeyedVectors.load_word2vec_format('wiki.ko.vec') # 사전학습된 모델 로딩
find_similar_to = '노력' # 노력과 유사한 단어와 유사도를 확인
for similar_word in model_kr.similar_by_word(find_similar_to) : # similar_by_word
print("Word: {0}, Similarity: {1:.2f}".format(
similar_word[0], similar_word[1]
))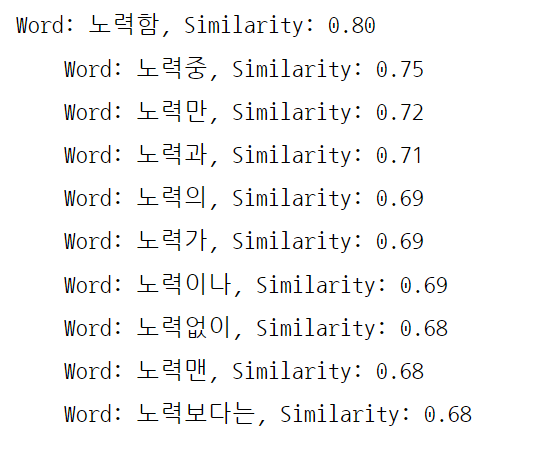
노력이라는 단어에 조사가 붙은 결과를 보여준다.
similarities = model_kr.most_similar(positive=['동물', '육식동물'], negative=['사람']) # most_similar
print(similarities)
# "동물", "육식동물" 에는 긍정적이지만, "사람" 에는 부정적인 단어를 살펴보기
# 사람과는 관계가 없으면서 동물과 관련된 단어들을 출력한다.
④ 횟수/예측 기반 임베딩
• Glove
횟수기반의 LSA 와 예측기반의 Word2vec 단점을 보완하기 위한 모델이다. 글로벌 동시발생 확률을 포함하는 단어 임베딩 방법으로, 단어에 대한 통계 정보와 skip-gram 을 합친 방식이라고 할 수 있다.
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
glove_file = datapath('..\chap10\data\glove.6B.100d.txt') # 수많은 단어에 대해 차원 100개를 가지는 임베딩 벡터를 제공
word2vec_glove_file = get_tmpfile("glove.6B.100d.word2vec.txt")
glove2word2vec(glove_file, word2vec_glove_file) # word2vec 형태로 글로브 데이터를 변환
model = KeyedVectors.load_word2vec_format(word2vec_glove_file) # word2vec.c 형식으로 데이터를 가져옴
# bill 단어 기준으로 가장 유사한 단어의 리스트를 출력
model.most_similar('bill')
# ‘cherry’와 관련성이 없는 단어의 리스트를 반환
model.most_similar(negative=['cherry'])
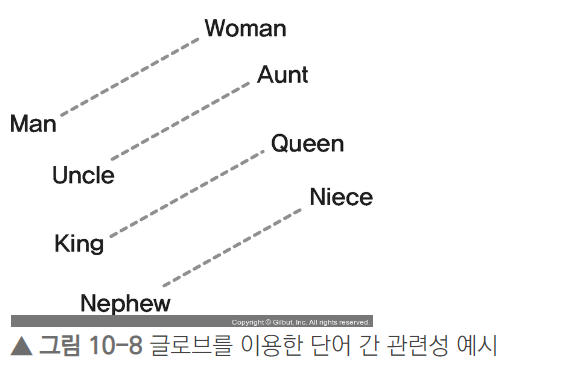
# ‘woman’, ‘king’과 유사성이 높으면서 ‘man’과 관련성이 없는 단어를 반환
model.most_similar(positive=['woman', 'king'], negative=['man'])
# ‘breakfast cereal dinner lunch’ 중 유사도가 낮은 단어를 반환
model.doesnt_match("breakfast cereal dinner lunch".split())
'1️⃣ AI•DS > 📒 딥러닝' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] 7장 시계열 I (1) | 2022.11.10 |
|---|---|
| [딥러닝 파이토치 교과서] 5장 합성곱 신경망 Ⅰ (0) | 2022.10.06 |
| [딥러닝 파이토치 교과서] 4장 딥러닝 시작 (1) | 2022.10.04 |
| [딥러닝 파이토치 교과서] 2장 실습 환경 설정과 파이토치 기초 (1) | 2022.09.23 |
| [딥러닝 파이토치 교과서] 1장 머신러닝과 딥러닝 (0) | 2022.09.22 |




댓글