👀 계량경제학 개인 공부용 포스트 글입니다.
※ 참고 블로그1
※ 참고 블로그2
※ 참고 블로그3
0. Brief review
• 무작위에 준하는 방법 (Quasi-experiment)
• RD 는 처치가 특정 제약조건이나 자격 하에 정해지는 경우에 사용된다.
• RD 에서 중요한 가정은 처치가 오로지 배정 변수에 의해 결정된다는 것이다.
↪ Running variable 배정변수 : 처치를 결정하는 변수
↪ Treatment variable 처치변수 : 처치 여부 변수
↪ Bandwidth : 배정변수 전후로 얼마까지 인과효과 추정에 활용할 것인지의 너비

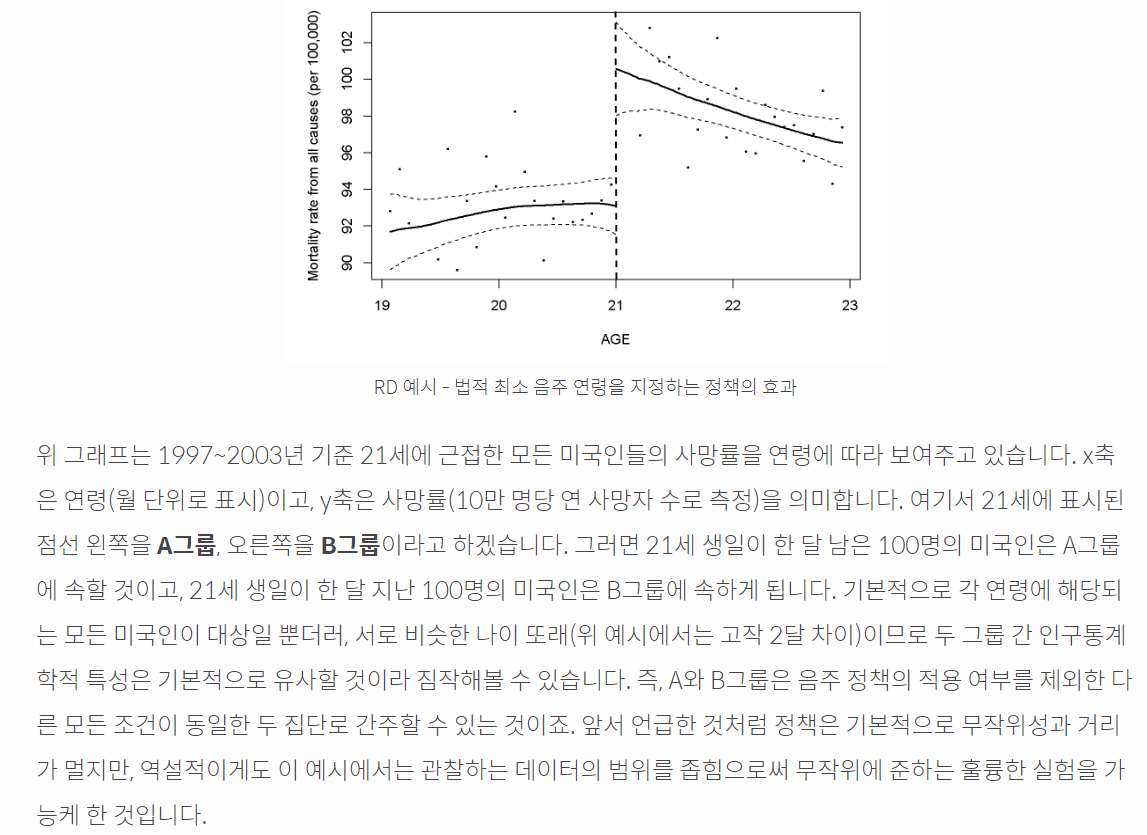
• ex. 음주가 사망에 영향을 미치는 인과관계를 확인하기 위해, 캐나다에서 시행한 법적 최소 음주 연령 제도에 초점을 맞춰 분석한 사례 : 음주 허용 연령이 최소 21세로 규제하여, 처치여부가 연령을 기준으로 정해졌다. 이러한 경우 연령이라는 특정한 제약에 의해 처치가 정해지므로 두 그룹의 사망여부를 단순 비교하는 경우 연령에 의한 영향이 포함되어 명확한 인과효과 추정이 어렵다.

• 배정 변수에 따라 처치 여부가 어떻게 정해지는지에 따라 2가지 종류로 나뉜다.

↪ Sharp RD : 배정 변수의 임계값 전후로 처치 여부가 명확히 정해지는 경우 (점선)
↪ Fuzzy RD : 배정 변수의 임계값 전후로 처치 여부가 정해질 확률이 변하는 경우 (실선)
• 대조군이 있는 DiD 와 달리, RD 는 대조군으로 여겨지는 그룹이 없으며, 배정변수 (Running variable) 이라는 개념을 통해 자연적으로 실험과 같은 환경을 구성한다.
• 배정변수에는 Parametric, Non-parametric 방식의 접근이 존재한다.
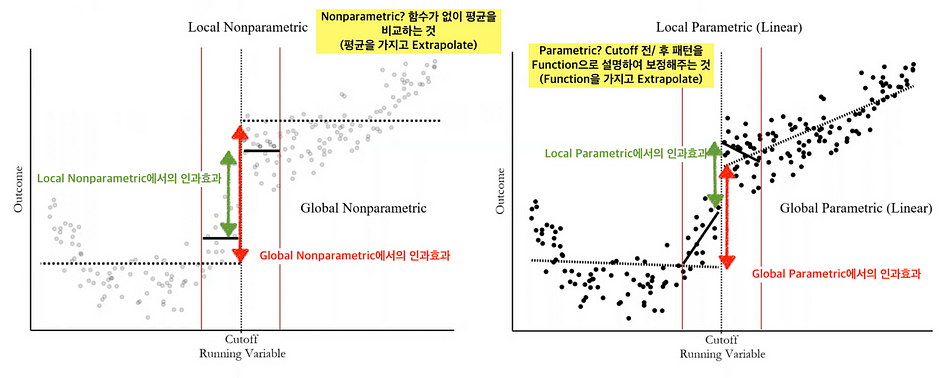
1. Motivation
• 상대적으로 완화된 가정을 도입한다.
• RD desin 으로부터 도출된 인과추론은, DiD 나 도구변수와 같은 natural experiment 전략들에 비해 잠재적으로 더 신뢰성이 있을 수 있다. 또한 randomization 이 필요하지 않다.
2. RD
① Basics
◯ Basic
• 관측치가 treated 되는 것은 cutoff rule (or threshold) 에 기반하여 정해진다.
• cutoff c 는 discontinuity 를 만든다.
• 관측가능한 변수 Xi 가 c보다 크거나 같을 때, 관측치가 treated 된다면, Xi 는 running variable (= forcing variable = score) 라고 부른다.
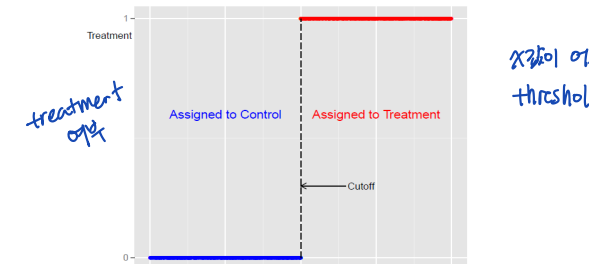
• 이러한 treatment 가 y에 어떠한 영향을 미칠지에 대해 조사한다.
◯ sharp RD
• treatment 상태가 deterministic 하고 discontinuous 한 running variable 의 함수를 가질 때
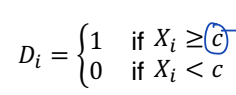
• Xi 의 값을 알고 있다면, Di 의 값도 확실이 알게 된다.
• goal : ATE 를 추정하는 것 : E[Y1i - Y0i | Xi]
• 그러나 문제점은, 모든 unit 에 대해 오직 Y1i 혹은 Y0i 만 관측된다는 것이다. (둘 다 동시에 관측 불가능)
② Visualization
• Sharp RD design 의 가장 중요한 특징은 Y1i 와 Y0i 를 동시에 관측할 수 없다는 것이다 (lack of common support)
• 대부분의 Xi 에 대해 E[Y1i - Y0i | Xi] 를 추정할 수 없다. 따라서 RD 는 인과효과를 측정하기 위해 cutoff point 에 대한 extrapolation 에 의존한다.
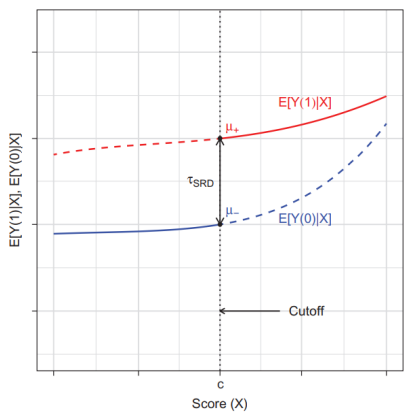
• Xi = c 인 경우를 생각해보자. 이때 Y1i 와 Y0i 를 거의 동시에 관측할 수 있다.
• Xi = c 인 unit 과 Xi = c - ε 인 unit 을 생각해보자. ε 이 매우 작다면, E[Y1i | Xi] 와 E[Y0i | Xi] 는 매우 비슷한 값을 가지고 있을 것이다. 그러나 실제 데이터에서 살펴보면 gap (=jump) 이 존재한다. 우리는 이러한 gap 을 treatment 라 볼 수 있다. (Xi = c 라면 Di = 1, Xi = c - ε 라면 Di = 0 이라 볼 수 있다) 즉, 우리는 두 그룹의 unit 을 사용해 ATE 를 근사할 수 있다. E[Y1i | Xi = c] - E[Y0i | Xi = c - ε]
③ Identification
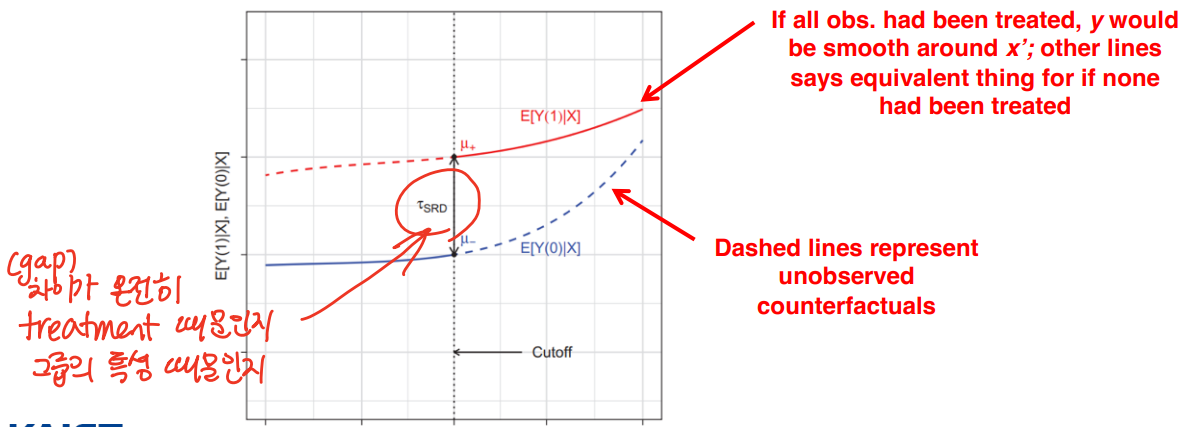
• Continuity assumption : 기초적인 가정으로, E[Y1i | Xi = x] 와 E[Y0i | Xi = x] 는 c에서 연속함수임을 보인다는 가정이다. 해당 가정을 통해, cutoff 이상 이하의 관측치들을 cutoff 에서의 처치효과로 측정할 수 있도록 한다. Running variable 이 conditional 되어있을 때, Potential outcome 이 threshold c 에서 continuous 하다는 가정이다. 즉, intervention 이 없다면 cutoff 에서 jump 가 없다는 것을 의미한다.
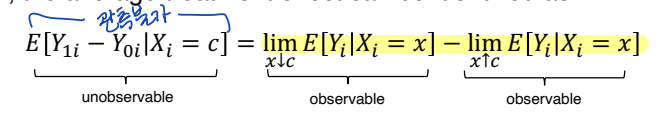
④ Sharp vs Fuzzy
• RD deign 의 2가지 유형
⑴ Sharp RD : cutoff c에서 처리가 0에서 1로 변경될 확률
↪ ex. eligibility of most welfare programs (복지 프로그램 참여 자격)
⑵ Fuzzy RD : treatment 확률이 cutoff c 근처에서 점진적으로 증가한다.
↪ Xi ≥ c 일 때 treatment 확률이 증가한다.
◯ Fuzzy RD
• treatment 를 assignment 하는 것이 stochastic (확률적) 이다. treatment 의 확률이 c에서만 discontinuity 하다.
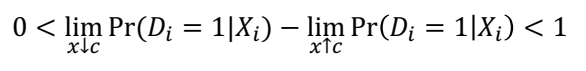
• treatment 확률이 c에서 jump 한다.
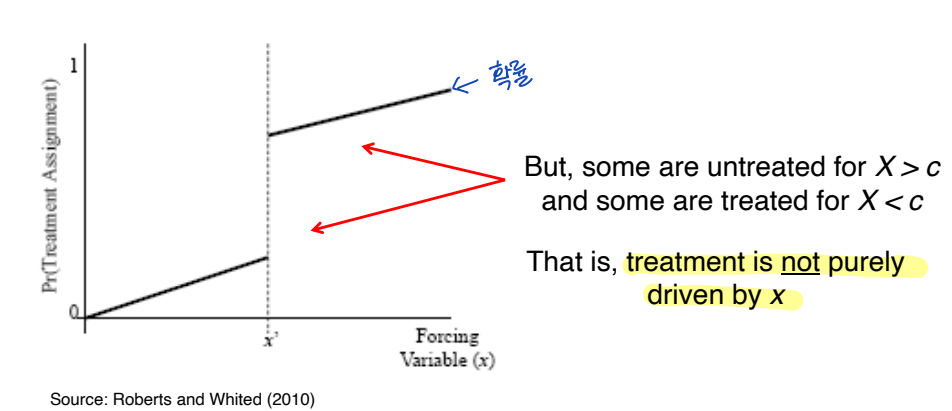
• Sharp RDD 에서는, 기본적으로 c의 주변에서 Y의 평균을 바로 비교할 수 있다.
• Fuzzy RDD 에서는 임계값 주변의 평균 변화가 인과적 영향을 과소평가한다.
◯ How Not to do Sharp RDD
• yi = β0 + β1•Di + ui 회귀 방정식은 D를 추정할 수 있을까
↪ Di 는 xi (running variable, 위의 수식에선 ui 부분) 와 상관되기 때문에, 더불어 xi 가 yi 에 영향을 미친다면 변수 누락의 상황이 생긴 것이다.

• 누락된 변수에 대해 설명하기 위해 수식을 변화시켜야 한다. xi 를 통제해야 하는 변수로 간주한다면 yi = β0 + β1•Di + β2•xi + ui 라고 추정할 수 있을 것이다. 그러나 이는 여러 문제가 있다. 먼저, xi 의 영향이 선형적이라고 가정하게 되버리며, threshold 에 가까울 때만 발생하는 random assignment 를 실제로 사용하지 않게 된다.
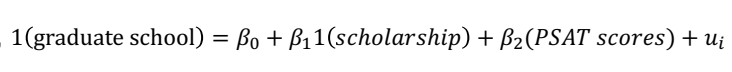
• 가령 위의 수식에서, ability 는 누락변수로 간주된다. ideal 한 실험환경으로, 같은 PSAT score 를 가진 학생들을 랜덤하게 scholarship 여부에 배정하기를 원한다. RDD 는 이러한 ideal 한 실험환경에 근사한 추정 방법이 될 수 있다.
⑤ Bias vs Noise
• 이상적으로, c 바로 아래와 바로 위의 평균적인 xi 를 비교해보고 싶다.
• 전체 데이터를 사용하는 것 (xi의 전체 범위)과 c 바로 아래/위를 사용하는 것 사이의 trade off 는 무엇일까
↪ c 바로 아래/위 데이터 사용 : 관측치가 많지 않을 것이고 c 바로 아래와 위의 데이터를 사용하면 추정치가 매우 noisy 할 것이다.
↪ xi 전체 범위 사용 : noise 를 줄여줄 수 있지만, bias 의 위험이 높아진다. 임계값에서 멀리 떨어진 관측치는 다른 이유로 인해 달라질 수 있다.
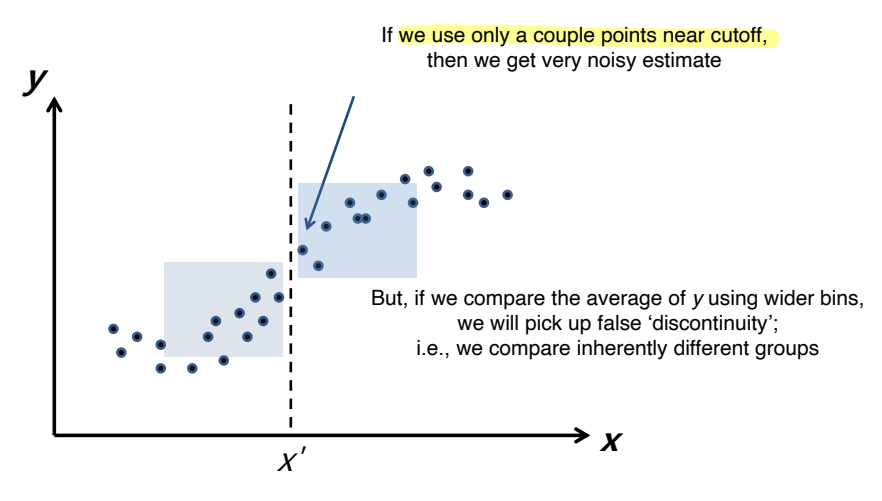
만약 cutoff 근처의 데이터만 사용하게 된다면, 추정치가 매우 noisy 할 수 있다. 그러나 만약 전체 범위에 대한 y의 평균을 비교한다면, 잘못된 'discontinuity' 를 고를 수 있다. 가령 본질적으로 다른 그룹을 비교하게 될 수 있다.
⑥ Estimation : Using all data vs window
• bias 와 noise 의 tradeoff 를 균형잡게 하기 위해 2가지 방법이 존재한다.
⑴ Using all data
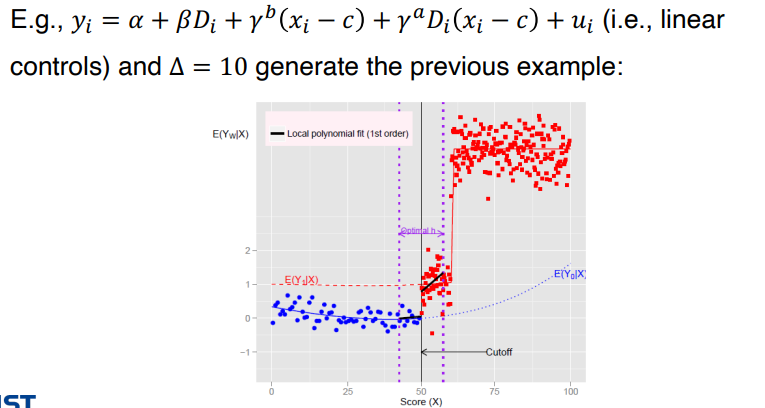
• 모든 데이터를 사용하나, 일반적이고 엄격한 방법을 통해 y에 대한 x의 영향을 통제한다 : Global polynomial fits
• 아래와 같이 c 이하에 해당하는 데이터에 대해 추정식 하나, c 이상의 데이터에 대한 추정식 하나로 2개의 회귀분석을 추정한다. f와 g 는 xi-c 에 대해 연속함수라고 두자.
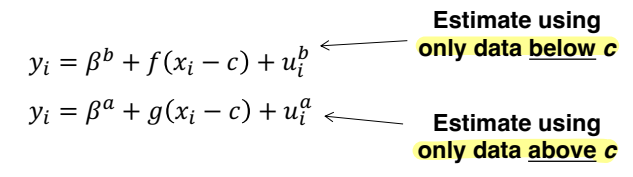
• treatment effect : βa - βb
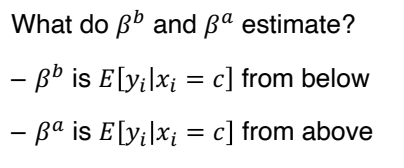
• f와 g가 포함되어야 하는 이유 : y 에 대한 x의 영향을 control 하기 위함
• 하나의 RD 수식으로 표현하면 아래와 같다.
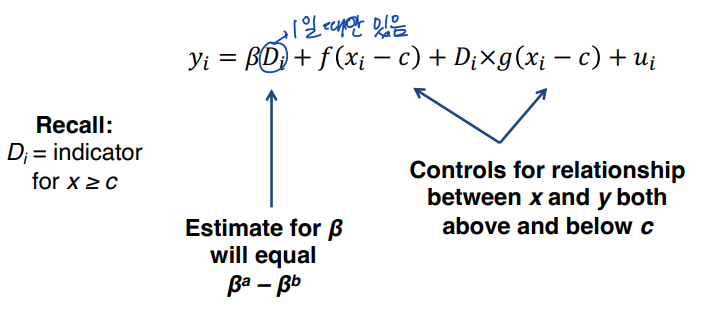
• 만약 Di x g(xi - c) 부분을 없앤다면, c 이상과 이하에서 xi와 yi의 함수 형태가 같다고 가정한다. 이는 강력한 가정이 될 수 있다. 해당 부분을 생략해도 큰 차이는 발생하지 않는다.
• f와 g 함수형태는 어떻게 결정해야 할까
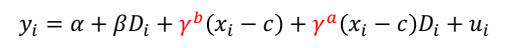
↪ 위와 같은 선형함수라고 가정해보자. 그러나 아래와 같이 non-linear 한 분포에 대해서는 잘못된 수식이 될 수 있다.
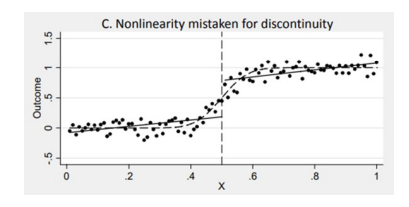
• f 와 g 에 대해 고차원의 polynomial 함수를 사용해 볼 수 있다 ⇨ Global polynomial approach
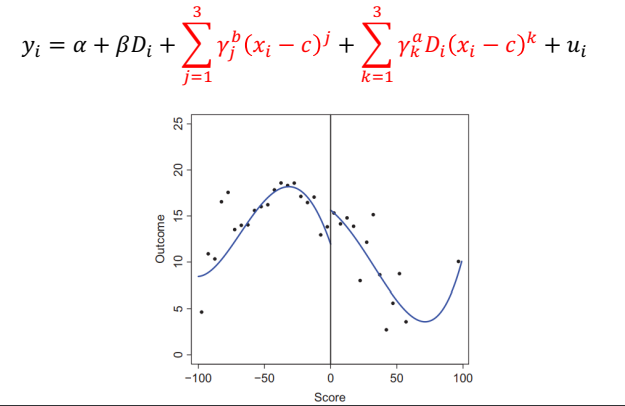
고차원의 형태는 선형함수보다 더 잘 동작할 수 있다.
• 그러나, 아래와 같이 처치효과가 assignment variable 에 대해 일관되지 않다면 어떻게 해야할까
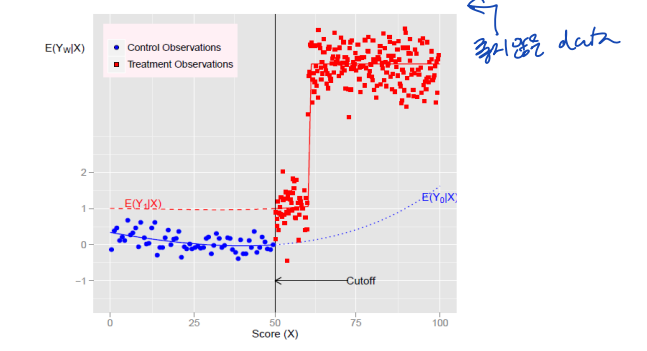
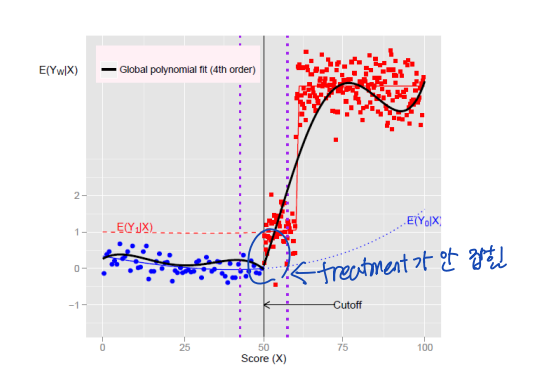
이러한 경우에 high-order polynomial 분포는 전체 처치효과를 흡수할 수 있다.
• Polynomial 의 차수는 어떻게 결정할까 → 궁극적으로, true polynomial 차수는 알려져있지 않다. 대신 robustness 를 보여주는 것이 좋다. 그래프 분석을 통해, 다른 polynomial 차수가 robust 한지 설명하면 된다. 혹은 아래와 같이 데이터 범위를 cutoff 주변에 더 작은 window 로 설정해볼 수 있다.
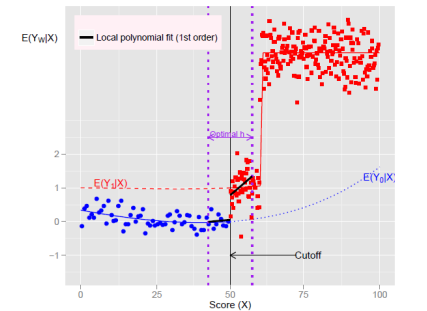
⑵ Window
• x의 영향에 대한 엄격한 통제를 사용하는 대신, threshold 주변의 small window 에 해당하는 데이터만 사용한다 : Local sample means (ex. non-parametric local polynomial)
• RDD estimate 이긴 하나, c 주변의 window 를 더 작게 설정하여 제한하는 분석이다.
• 더 작은 polynomial order 를 사용한다. 혹은 비모수적 local polynomial 을 사용한다 ⇨ non-parametric local polynomial approach
• global polynomial 접근방식은 1. Noisy estimate 2. sensitive to the choice of polynomial degree 3. poor confidence intervals 이기 때문에 좋지 않을 수 있다.
• Bandwidth : width of window
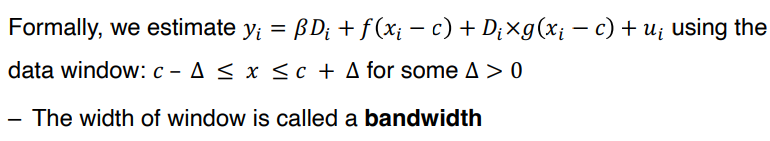
• f, g 로 어떤 함수를 고르는 것이 좋을까 : 정답은 없지만, 커널함수와 같은 non-parametric 함수로 선택할 수 있다.
• 적절한 window width 은 무엇일까 : 정답은 없지만, window width 와 polynomial order 선택에 있어 robustness 를 보이면 된다.
• smaller 한 window 는 noise 를 불러올 수 있지만, 샘플에서 x의 모든 값에 대한 상수 값의 처치효과를 가정하지 않아도 되며, 본질적으로 local average treatment effect 를 추정할 수 있고, bias 될 위험이 적다는 장점이 있다.

⑦ Falsification tests (graphical analysis)
• RD 는 DiD 와 비슷하게 시각적으로 강력한 디자인에 해당한다. RD 에선 그래프가 가장 강력한 falsification test 이다.
• discontinuity 가 존재하는지, 선택된 polynomial order 가 data 에 fit한지에 대해 시각적으로 조사한다. 그래프는 또한 데이터 변동에 대한 시각적 설명을 제공한다.
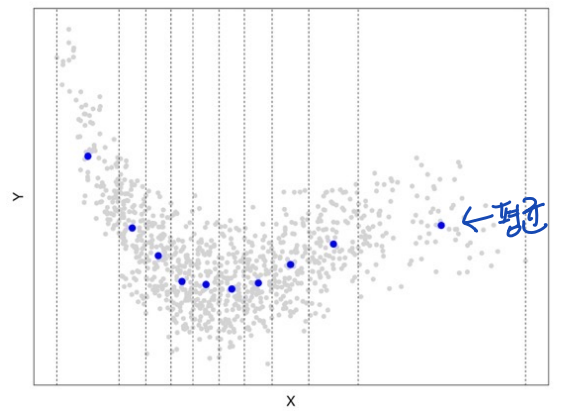
• Bin scatter plot (local sample means graph)
1. score 의 겹치지 않는 interval 혹은 bin 을 선택한다. (bin 의 개수와 길이)
2. 각 bin 에 대해 결과의 표본평균을 계산한다.
3. 표본 추출된 평균을 bin 의 중심점에 대해 그래프로 그린다.
◯ 실제 그리는 단계 자세한 설명

◯ 최적의 bin 의 개수는 무엇이며, bin 의 개수를 더 작게 할 때 발생하는 tradeoff 는 무엇일까
• precision 과 bias 사이에 tradeoff 가 존재하기 때문에 bin 의 개수를 선택하는 것은 매우 주관적일 수 있다. 더 많은 데이터 포인트들을 포함시킴으로써 wider 한 bin 을 설정한다면, E(y|x) 에 대해 더 정확한 추정치를 제공할 수 있게 한다. 그러나 만약 E[y|x] 가 constant 하지 않다면 (non-zero slope 을 가진다면) bias 가 발생할 수 있다.
• 이에 관해 Calonico, Cattaneo, and Titiunik 는 Integrated mean squared error (IMSE) method 를 제안한다. 해당 방법은 local mean 의 IMSE 에 대한 점근적 근사를 최소화 하는 bin 의 개수를 결정한다. 또 다른 방법으로는 Mimicking variance method 가 있다.
◯ Graph Supportive of RDD
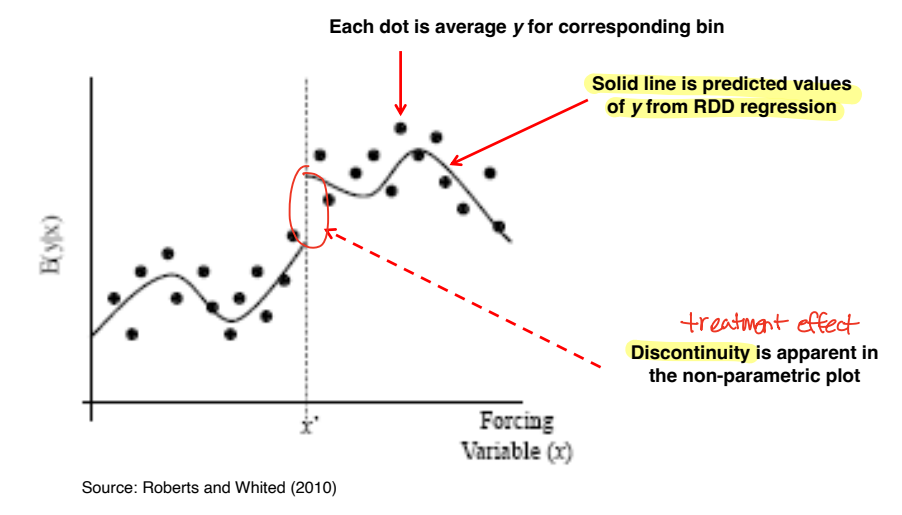
• 각 데이터 포인트들은 bin 에 대응하는 평균 y 값에 해당한다.
• 검정색 선은 RDD 회귀 식으로부터 예측된 y 값을 의미한다.
• 비모수 그림에서 Discontinuity 가 뚜렷하게 관찰된다.
◯ Graph Not Supportive of RDD
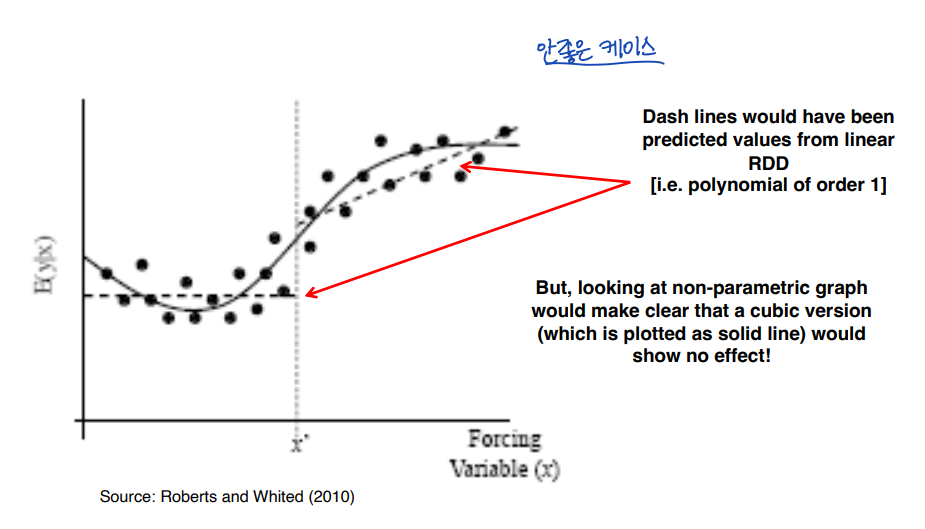
• 점선은 선형 RDD (차수가 1인 polynomial) 로부터 예측된 값이다.
• 비모수 그래프를 보면 (검정 실선) cubic version 이 효과를 표현하지 못하고 있음을 확인할 수 있다.
◯ Miscellaneous Issue (여러가지 종류의 문제)
• 비모수 그림은 c이외의 다른 점에서 y 의 jump 를 제공하면 안된다. c 부근에서의 jump 는 treatment 와 관련이 없는 다른 것으로 인해 발생될 수 있다. (Question the internal validity of RDD)
⑧ Fuzzy RDD
◯ Intuition for Fuzzy RDD
• Sharp RDD 에서 그랬던 것처럼 threshold 바로 위 아래 (above and below) 의 y의 평균을 비교하는 것은 Fuzzy RD 에선 적절하지 않을 수 있다. Fuzzy RDD 에선, threshold 이상의 관측치 모두가 treated 받은 것이 아니며, 이하의 관측치 모두가 untreated 받은 것이 아니라는 점을 기억해야 한다.
• Fuzzy RD 에서 x > c 는 단순히 treatment 의 확률을 증가시킬 뿐이다.
• 따라서 우리는 x ≥ c 를 treatment 에 대한 도구변수로 사용해야 한다.
◯ Fuzzy RDD notation
• Di = 1 : treated by event of interest, 0 : otherwise
• New threshold Indicator
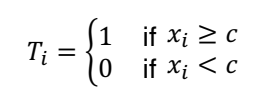
↪ ex. Di = 1 이 일류 대학에 합격한 경우라고 한다면, Ti =1 은 SAT 점수가 학교의 cutoff 점수 이상인 경우를 의미한다.
◯ Fuzzy RDD Estimation
• Ti 를 Di 에 대한 도구변수로 간주하고 2SLS model 을 추정한다.

• IV 의 조건
⇨ Ti 는 Di = 1 의 확률에 영향을 받는다 : Relevance condition
⇨ Di 와 통제변수가 conditional 되어있다면, Ti 는 y와 unrelated 된다 : Exclusion ondition
◯ Fuzzy RDD Estimation : Note on g()
• Shar RDD 와 달리, cutoff 이상 범위와 이하 범위에 미분 함수를 허용하는 것은 쉽지 않다.
• Di x g(xi - c) 가 있는 경우와 없는 경우를 생각해보자
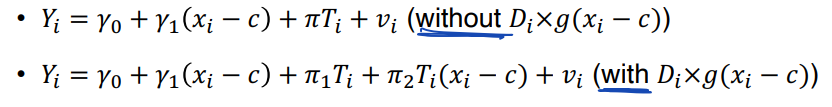
• 상호작용 항이 있는 두번째 수식에서는 treatment effect 가 x에 따라 달라짐을 가정한다 (not constant)
• x에 따라 treatment effect 가 달라지는 것 (varying)으로 인해 어떠한 문제가 발생할까
↪ treatment 와 관련없는 다른 것에 의해 c에서의 jump 가 발생할 수 있다.
• 다른 함수 형태에 대해 우려가 된다면, 어떻게 해결할 수 있을까 : Use a tighter window around event
↪ event 주변의 window 를 좁게 설정하면 f(x) 함수의 형태를 선택하는데 있어 덜 민감해질 것이다.
◯ Graphical Analysis of Fuzzy RDD
• x' 에서 y에 discontinuity 가 있음을 보여주어야 한다. 또한 적절한 Polynomial fit 을 해야 한다.
• Di 에 대한 plot 을 통해 first stage 를 시각적으로 확인한다. 이를 통해 threshold 에서 처치확률의 discontinuity 가 존재함을 확인해 볼 수 있다.
⑨ 나머지 내용
◯ Robustness test for Internal validity
• 그래프 분석 결과를 보여주고, 선택한 Polynomial 과 bandwidth 가 robust 한지 확인해야 한다.
⑴ No manipulation
• 임계값 c가, y에서의 기존에 존재한 discontinuity 혹은 c 주변의 비교가 불가능하여 선택되었다는 이유가 있다면, local continuity 가정을 위반했다고 볼 수 있다. reverse causality 와 비슷한 아이디어이다.
↪ ex. 개개인이 특정 임계값을 기준으로 본질적으로 다르다면, 규제 당국은 해당 지점에서 가장 효과가 큰 것으로 알려진 규제를 제정하기로 선택한다.
• Manipulation 이 문제가 되는 이유 : agent 가 임계값 주변에서 x를 조작하면, local continuity 가정을 위반할 수 있다. 그러나 조작능력이 항상 문제가 되는 것은 아닌데, 완벽하게 조작할 수 없다면 여전히 treatment 에서 무작위성이 존재할 수 있다. c 주변의 작은 bandwidth 구간에서는 x를 조작하려고 해도 일부가 임계값 주변으로 밀려나기 때문에 여전히 무작위성이 존재한다.
⑵ Balance of Covariates
• RDD 는 cutoff 근처의 양쪽 관측값이 비슷하다고 가정한다. 그래프 분석 또는 RDD 를 이용하여 영향을 미칠 수 있는 다른 관찰 가능한 요인이 임계값 c에서 jump 를 보이는지 확인한다. 그러나 이러한 방법도 RDD 의 validity 를 입증하기는 어렵다. 관측불가능한 요소가 discontinuity 를 불러올 수 있기 때문이다.
• y에 영향을 미치는 다른 변수를 control 로 추가할 수 있다. 만약 이 변수가 추정된 처치효과에 영향을 미친다면 bad control 이라 볼 수 있다.
⑶ Falsification Tests
• threshold c 가 특정 연도 혹은 특정 관측치에만 존재한다면, cutoff 이외의 다른 변수 할당 값에 대해 구조중단 실험을 진행해 볼 수 있다.
◯ Heterogeneous Effects
• treatment 가 x 값에 따라 차등적으로 영향을 미칠 수 있다고 생각한다면, RDD 로 local average treatment effect 를 식별하기 위해 추가적인 가정이 필요하다.
1. Treatment 의 영향은 c에 대해 locally continuous 하다.
2. treatment 가능성은 항상 threshold c 값보다 약간 크다. (weakly greater or smaller above c)
3. treatment 의 영향과 관측값이 treated 될지는 c 근처에서 x에 독립적이다. (no manipulation)
• HE Interpretation : 이질성의 핵심은, 오직 local average treatment effect 에 대해서만 추정할 수 있다는 점이다.

◯ External validity
• Identification 은 cutoff threshold 근처의 관측값에 의존한다. 임계값에서 멀리 떨어진 관측치의 경우 치료 효과가 다를 수 있다.
• Fuzzy RDD 에서 treatment 는 오직 compliers 만 사용해 추정된다.
◯ RDD vs DiD
• RDD 는 Identification strategy 를 시각적으로 설명할 수 있다는 점에서 DiD 와 유사하다.
• 그러나 RDD 에서는 treatment 의 배정이 Random 하지 않다는 것이 큰 차이점이다. assignment 는 x 값에 기반한다. treatment 가 x에만 의존할 떄, treatment 와 control 사이에 겹치는 부분이 없다.
• treatment 의 배정은 임의가 아니지만, 개별 관측치가 처치될지 아닐지는 임의성을 가정한다.


'1️⃣ AI•DS > ⚾ 계량경제•통계' 카테고리의 다른 글
| Hidden Markov Models in Marketing 노션 정리 (1) | 2024.12.14 |
|---|---|
| 대체로 해롭지 않은 계량경제학 정리 - Part2 핵심 - 3장 (0) | 2023.06.26 |
| 계량경제학 강의_한치록_특수주제들 17장 (0) | 2023.05.25 |
| 계량경제학 강의_한치록_내생적인 설명변수 16장 (1) | 2023.05.24 |
| 계량경제학 강의_한치록_내생적인 설명변수 15장 (0) | 2023.05.24 |



댓글