👀 계량경제학 개인 공부용 포스트 글입니다.
16. 도구변수 추정
① 자료에 의한 모수의 식별
• y = β0 + β1•x1 + β2•x2 + u 이고, x1과 x2가 외생적이면, β0, β1,β2 는 E(u) = 0 , E(x1•u) = 0 , E(x2•u) = 0 에 대응하는 방정식에 의해, 결정될 모수가 3개 & 방정식 3개 이므로 세 모수들은 관측변수들의 분포 (평균, 분산, 공분산) 에 의해 식별된다 (identified). 즉, β0, β1,β2 는 유일하다.
• x2 가 내생적이면 문제가 된다. E(x2•u) ≠ 0 이므로 β0, β1,β2 를 만족시키는 경우가 무한히 많아진다. 세 모수들을 정확히 식별하려면 별도의 방정식이 최소한 하나 더 필요하다. 이 추가 방정식들을 추가적 도구변수들이 제공하게 된다. 가령 z2 라는 추가적 외생변수가 있다고 하면, E(z2•u) = 0 의 식이 추가되어 모수가 맞게 식별된다.
• 그러나 만약 내생적 설명변수가 1개일 때, 추가적 도구변수가 2개 이상이 되면, 모수들이 과잉식별 될 수 있다. 즉, 모수들의 식별에 필요한 만큼보다 더 많은 제약이 존재하게 된다.
• 모수들이 모두 식별되려면 내생적 설명변수 개수 이상의 관련된 추가적인 도구변수가 필요하다.
② 2단계 최소제곱법
• y = β0 + β1•x1 + β2•x2 + u
↪ x1 은 외생적, x2는 내생적이라 하자
↪ 추가적 도구변수 : z2
1. 내생적 설명변수인 x2 를 모든 외생변수, 즉 x1, z2 에 대해 회귀하여 fitted value (x2^)를 구한다. 이 단계에서 z2의 유의성을 점검하는 것이 좋다. 만일 z2의 유의성 (t검정이나 F검정으로 확인) 이 떨어지면 2SLS 를 할 수 있으나 추정량의 성질은 매우 나쁠 수 있다.
2. y를 x1과 x2^ 에 대해 OLS 로 회귀한다. 이 추정값들이 2SLS 추정값이다. 이 회귀에서 통상적으로 보고되는 표준오차, t통계량, p 값은 타당하지 않다.
◯ R 예제
data(Ivdata, package = 'loedata')
coeftest(lm(y~x1+x2, data = Ivdata))
• x2 설명변수가 내생적이라고 하였기 때문에 이 추정값들은 참값과 체계적으로 다르다.
• 도구변수 z2a 를 사용해 2SLS 추정을 해보자. x2 를 회귀할 때 모형에 포함된 외생변수 x1을 누락시키면 안된다.
▸ First-stage
stage1 <- lm(x2~x1+z2a, data = Ivdata)
coeftest(stage1)
• z2a 의 t 값은 5.4고, pvalue 가 거의 0에 가까워 z2a 와 x2 는 강한 상관관계를 보인다고 볼 수 있다. 보통 t 절댓값이 3 이상이면 강하게 연관된 도구변수로 간주한다.
▸ Second-stage
Ivdata$x2hat <- fitted(stage1)
stage2 <- lm(y~x1+x2hat, data = Ivdata)
coeftest(stage2)
• 2SLS 추정계수는 OLS 추정값들과 상당한 차이가 있다. OLS 추정값들은 x2가 내생적이기 때문에 믿기 어렵고, 여기서 2SLS 추정값 자체는 consistent 하지만, 보고된 표준오차, t값, p값은 모두 타당하지 않다. 둘째 단계 회귀 시 설명변수로 x2hat 을 사용하였기 때문이다. 이를 교정하는 방법은 추후에 배울 예정!
• 만약 내생적인 설명변수가 2개 이상인 경우라면, 가령 y = β0 + β1•x1 + β2•x2 + β3•x3 + u 에서 x2와 x3가 내생적이라 하자. 이때 추가적 도구변수를 z2, z3 라 하면, 첫째단계 회귀에서는 x2와 x3를 각각 모든 외생변수 x1,z2,z3 에 OLS 회귀하여 fitted value x2hat, x3hat 을 구한다. 둘째 단계 회귀에서는 x2,x3 를 x2hat, x3hat 으로 치환해 y를 x1, x2hat, x3hat 에 대해 OLS 회귀한다.
• 모수들이 딱 맞게 식별되는 경우는 2SLS 추정량이 좀 더 간단한 형태로 표현될 수 있으며, 이러한 경우의 추정량을 도구변수 추정량 (IV estimator) 라 한다. 일반적인 2SLS 추정량은 GIV estimator 라 한다.
③ 2SLS 추정량의 분산
• y = β0 + β1•x1 + β2•x2 + u
↪ x1 은 외생적, x2는 내생적이라 하자
↪ 추가적 도구변수 : z2
• 2SLS 에서 둘째 단계 회귀의 설명변수가 x1, x2hat 이기 때문에 둘째 단계 회귀에서 보고되는 표준오차를 사용하면 안 된다. 둘째 단계 회귀 잔차가 y - β0hat - β1hat•x1 - β2hat •x2hat 이라는데 있다. 하지만 이 잔차는 uhat = y - β0hat - β1hat•x1 - β2hat •x2 가 되어야 한다. 잔차항을 uhat 으로 바꾸면 표준오차를 제대로 구할 수 있다.
• uhat 으로 사용하는 방법을 R에서 자동으로 제공해주는 패키지가 있다. AER, sem 등이 있다. 여기선 AER 패키지를 사용하는 방법을 소개한다.
install.packages("AER")
library(AER)
tsls <- ivreg(y~x1+x2 | x1 + z2a, data = Ivdata)
coeftest(tsls)
• ivreg 방정식을 지정할 때, | 오른쪽에 도구변수 (모든 외생변수) 들을 적는다.
• 오차항에 이분산이 있는 경우에는, 패키지를 사용해 OLS의 경우와 비슷하게 이분산에 견고한 추론을 할 수 있다.
library(sandwich)
coeftest(tsls, vcov = vcovHC, type = "HC0")
④ 2SLS 와 관련된 검정들
• 3가지 중요한 검정
1. 추가적 도구변수들이 내생적 설명변수와 연관되어 있는지 검정하는 것
⇨ 연관되어 있지 않다면 2SLS 추정량이 매우 나쁨 (편향이 크고 분산이 큼)
2. 내생적이라고 보았던 설명변수가 실제 외생적인지 내생적인지 검정하는 것
⇨ 설명변수가 외생적이라면, 2SLS 보다 OLS 를 사용하는 것이 좋다.
3. 도구변수들이 정말로 외생적인지 검정하는 것
⇨ 모든 도구변수들이 외생적이지 않다면, 2SLS 추정량은 일관적이지 않게 된다.
• y = β0 + β1•x1 + β2•x2 + u
↪ x1 은 외생적, x2는 내생적이라 하자
↪ 추가적 도구변수 : z2 (하나의 변수일 수 있고, 복수의 변수일 수 있다)
⑴ 추가적 도구변수들의 관련성 검정 : 첫째 단계 F 검정
• 검정 : x1 을 통제하였을 때, z2 의 변화가 x2에 충분한 변화를 가져오는지 여부
• x1을 통제한 후, x2와 z2 가 강한 상관관게를 가질 때 z2 는 강한 도구변수라고 하고, 둘의 상관관계가 약할 때 z2 는 약한 도구변수라고 한다. 만약 z2가 약한 도구변수라면 2SLS 추정량의 분산이 매우 커진다. 또한 편향이 존재할 수도 있다. 따라서 x1 을 통제한 상태에서 x2 와 z2가 연관되었는지 검정하는 것은 중요하다.
• 첫째 단계 회귀식 x2 = π0 + π1•x1 + π2•z2 + v2 를 OLS 추정하여 H0 : π2=0 을 검정하면 된다. π2 의 방향성은 중요하지 않기 때문에 대립가설은 H1 : π2 ≠ 0 이 된다. 도구변수가 단일 변수이면 t 검정과 F 검정 중 하무거나 이용해도 좋고, 복수의 변수를 포함하면 F 검정을 하면 된다 ⇨ first-stage F test
• 귀무가설이 기각되어야만 외생적 설명변수가 통제된 상태에서 추가적인 도구변수들과 내생적 설명변수가 서로 연관되어있음을 의미한다. t 통계량은 5 이상, F 통계량은 10 이상이면 도구변수들의 관련성이 충분히 큰 것으로 간주한다.
• 도구변수가 단일한 경우
coeftest(stage1)
• 도구변수가 다수인 경우 (z2a, z2b)
stage1a <- lm(x2~x1+z2a+z2b, data = Ivdata)
coeftest(stage1a)
waldtest(stage1a, x2~x1)
⑵ 설명변수 외생성 검정
• 귀무가설 : x2 가 외생적 (x2와 u 의 공분산이 0)
• 도구변수들은 오차항과 무관하기 때문에, x2 중 도구변수들로써 설명된 부분 또한 오차항과 무관할 것이다. 만약 x2와 u 가 상관되어 있다면 이는 x2 중 도구변수들에 의해 설명되지 않는 부분이 u 와 상관되어 있기 때문이다.
• x2 = π0 + π1•x1 + π2•z2 + v2 라 할 때, x1과 z2 는 u 에 대해 외생적이므로, v2가 u 와 상관된 경우에 x2가 내생적이게 된다. v2와 u 가 상관되어 있는지 보기 위해 u = ρ•v2 + ε 라 두고 ρ=0 인지 점검해보면 된다. ρ=0 이면 v2가 u 와 무관하게 되고, x2와 u 가 무관하게 되어 x2 를 외생변수라 볼 수 있다. v2 를 관측할 수 있다면 해당 방정식을 OLS 회귀하여 H0 : ρ=0 를 검정하면 된다. 그러나 v2 를 관측할 수 없기 때문에 first-stage 의 잔차항으로 이를 치환한다. 즉, 원래의 회귀방정식 우변에 첫째 단계 잔차항 v2hat 를 추가하여 OLS 회귀한 후 이 계수가 0인지 검정함으로써 설명변수의 외생성을 판단해볼 수 있는 것이다.
stage1 <- lm(x2~x1+z2a, data = Ivdata)
Ivdata$v2hat <- resid(stage1)
coeftest(lm(y~x1+x2+v2hat, data = Ivdata))
⇨ v2hat 계수의 p 값이 0.02로 5% 수준에서 유의하고, 귀무가설은 5% 수준에서 기각되기 때문에 x2가 내생적이라고 결론내릴 수 있다.
• 잔차항 v2hat 에 대한 표준오차는 x2가 외생적이라는 귀무가설 하에서만 타당하다. 이 추정 결과로 신뢰구간을 정하거나 모수의 참값에 대한 추론을 하면 안된다.
⑶ 도구변수 외생성의 검정
• 보통 외생적 설명변수를 도구변수라고 함께 칭하는 경우가 많다.
• 검정 : x1과 z2 가 정말로 외생적인지 검정
• 그러나, 모수들을 추정할 때, E(u) = 0 , E(x1•u) = 0, E(z2•u) = 0 라는 조건을 모두 활용하였다. 즉, 도구변수의 외생성을 활용해 모수들을 추정한 것이다. 따라서 더 이상 이용가능한 정보가 남아있지 않아 검정을 진행하기가 어렵다.
• 검정할 수 있는 최선의 방법은, 도구변수 추정시 만일 필요한 것보다 더 많은 변수들이 도구변수로 활용된다면 (과다식별정도가 0보다 크다면), 사용된 도구변수들이 모두 외생적이라는 가설이 자료에 부합하는지 아니면 모순되는지 검정할 수 있다.
• 가령 x2가 내생적이고 추가 도구변수로 z2a 와 z2b 가 사용된다면, E(u) = 0 , E(x1•u) = 0 조건 외에 E(z2a•u) = 0 과 E(z2b•u) = 0 라는 추가적 조건들이 모수 추정에 활용되는데, 이 4가지 조건이 모두 충족되는지 검정한다. (과다식별검정) 귀무가설은 이 조건들이 모두 충족된다는 것이며, 귀무가설이 기각된다는 것은 조건들이 서로 양립하지 않는다는 것이다. 이때 둘 중 어느 조건이 위배되었는지는 알 수 없다.
• 과다식별검정의 기본 아이디어는 도구변수들과 2SLS 잔차항이 관련된 것인지 점검하는 것으로, 외생변수들에 대해 (x1, z2a, z2b) 회귀하여 보고 도구변수들이 중대한 설명력을 갖는지 살펴보는 것이다 (LM 검정)
tsls <- ivreg(y~x1+x2 | x1+z2a+z2b, data = Ivdata)
Ivdata$uhat <- tsls$resid
aux <- lm(uhat ~ x1+z2a+z2b, data = Ivdata)
stat <- nrow(ivdata)*summary(aux)$r.sq
stat # 0.33
qchisq(0.95,1) #3.84
1-qchisq(stat,1) # 0.562
p 값이 0.56 으로 5%유의수준에서 귀무가설이 기각되지 않는다. (도구변수 조건들이 모두 충족됨)
⑤ 통제함수 방법
• y = β0 + β1•x1 + β2•x2 + ρ•v2 + ε 에서 v2 항은 x2 의 내생성을 야기하는 항이며, 이 항을 통제하여 내생성의 문제요인을 통제할 수 있다. 이러한 접근법을 control function approach 라고 한다.
• y 를 x1,x2,v2hat 으로 회귀하면 β2 의 계수 추정값은 2SLS 추정값과 완전히 똑같다.
• 2SLS 에서 단순 수동 회귀시 표준오차를 조정하는 것처럼 통제함수 접근법에서도 표준오차들을 조정해주어야 한다. 사실상 통제함수 회귀는 설명변수 외생성을 검정할 때 실행한 회귀와 완전히 동일하다.
⑥ 내생적 설명변수의 제곱항과 상호작용항
◯ 제곱항
• y = β0 + β1•x1 + β2•x2 + β3•x2^2 + u : x1은 외생적, x2는 내생적, 추가적 도구변수로 z2 가 이용 가능
• 위의 회귀식에는 두 개의 내생적 설명변수 x2 와 x2^2 가 있다. 적어도 2개의 도구변수가 필요하다. 쉽게 생각해볼 수 있는 변수로는 z2 와 z2^2 이다. z2^2 가 u 와 무관하고 (z2, z2^2) 이 (x2,x2^2) 과 충분한 상관관계를 갖는다면 (z2,z2^2) 을 추가적 도구변수로 사용하는 2SLS 추정량은 일관적이다.
⇨ 이와 같은 방법은 E(x1•u) = 0 , E(z2•u) = 0 , E(z2^2•u) = 0 이라는 조건을 사용
coeftest(ivreg(y~x1+x2+I(x2^2)|x1+z2a+I(z2a^2), data = Ivdata))
• 다른 방법으로, x2가 내생적인 이유가 u = ρ•v2 + ε 이기 때문이라면 통제함수 접근법을 사용할 수 있다. 그러나, 이 통제함수 추정량은 2SLS 추정량과는 다르다.
⇨ 통제함수 방법은 E(u|x1,x2) = 0 이라는 조건을 사용한다. 조건부 평균으로 표현되는 조건이기 때문에, 공분산으로 표현되는 첫번째 방법보다 훨씬 더 강한 조건에 해당한다. 따라서 더 작은 추정량 분산을 가진다.
◯ 상호작용항
• y = y = β0 + β1•x1 + β2•x2 + β3•x1•x2 + u 모형을 가질 때, 만일 x2 = π0 + π1•x1 + π2•z2 + v2 이고 z2 가 외생적이라면 z2 와 x1•z2 를 두 도구변수로 사용할 수 있다.
coeftest(ivreg(y~x1*x2 | x1*(z2a+z2b), data = Ivdata))
• 혹은 v2hat 을 통제함수로 사용해 OLS 를 할 수도 있다. 이는 위의 추정 결과와 상이하게 나온다.
Ivdata$v2hat <- lm(x2~x1+z2a+z2b, data = Ivdata)$resid
coeftest(lm(y~x1*x2+v2hat, data = Ivdata))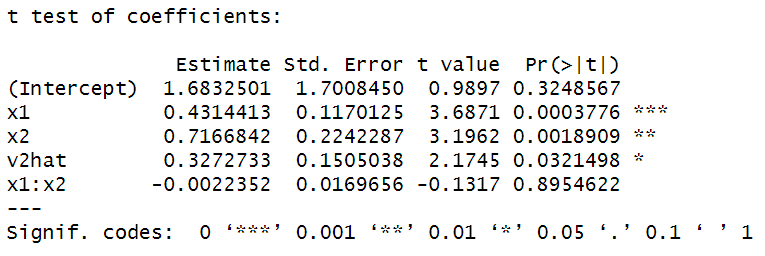
※ 예제 16.5 책 참고해서 공부하기
'1️⃣ AI•DS > ⚾ 계량경제•통계' 카테고리의 다른 글
| 계량경제학 스터디 Lecture 8. Regression Discontinuity (0) | 2023.05.25 |
|---|---|
| 계량경제학 강의_한치록_특수주제들 17장 (0) | 2023.05.25 |
| 계량경제학 강의_한치록_내생적인 설명변수 15장 (0) | 2023.05.24 |
| 계량경제학 강의_한치록_가정의 현실화 14장 (0) | 2023.05.23 |
| 계량경제학 강의_한치록_가정의 현실화 13장 (1) | 2023.05.22 |

댓글