📌 교내 '인공지능' 수업을 통해 공부한 내용을 정리한 것입니다.
Intro
✨ sequential data, temporal data 와 같이 데이터가 시간상에 순서가 있는 경우 RNN 은 좋은 성능을 발휘한다.
◾ language : 시간 상에서 단어들이 배열된다 (speech, text)
◾ video : 이미지가 시간 상에서 sequential 하게 존재한다.
✨ spatial data → 이미지 data 를 처리하는데 CNN 모델이 좋은 성능을 발휘한다. 2D, 3D conv 자체가 주변의 공간상에 있는 픽셀들의 정보를 가져오는 것이기 때문이다.
✨ 단일한 RNN, LSTM 모델모단 Attention 을 사용한 RNN, LSTM 모델이 사용되고 있다.
1️⃣ RNN
① Neural Networks That process Sequence
(1) Conceptual view

◼ One-to-One : 기본적인 NN 의 구조로 CNN 이 이러한 형태를 띄고 있다. 이와 같은 형태는 sequential 한 데이터를 처리할 수 있는 방법이 전혀 없다.
◼ sequence 를 처리할 수 잇는 NN 을 설계하고 input 과 output 을 어떻게 붙여주느냐에 따라 특정 application 을 수행할 수 있도록 한다.
◼ Example
- image captioning : 운전하고 있는 사람의 모습이 담긴 이미지로부터 'A person drives a car' 이라는 문장을 도출한다. One-to-many
- action prediction : 자율주행 시 이전 운전 기록을 바탕으로 핸들의 방향을 예측한다. Many-to-one
- video captioning : frame 단위로 비디오를 읽은 다음 맥락을 보고 비디오 내용을 문서화한다. Many-to-Many
(2) Example
◼ One-to-Many : image captioning

◼ Many-to-Many : video captioning

◼ OpenAI : GPT-3
- GPT-3 는 sequential NN 중 하나로, 챗봇에 많이 활용된다. 스스로 프로그래밍 해주는 인공지능 설계에도 사용된다.
- 현재까지 설계된 신경망 중 크기가 가장 크다. 3000억 개의 데이터 셋으로 학습을 하였으며 1750개의 매개변수를 가지고 있다.
- GPT-3 는 2021년 초까지 발표된 언어모델 중 가낭 성능이 뛰어난 모델이다.
- 한국어 패치가 잘 되어있고, 이미 충분한 학습을 수행한 모델이기 때문에 추가적인 과정 없이 input 을 넣기만 하면 되는 경우가 많다.

👀 인공지능(AI) 자연어 처리(NLP)에서 가장 화제가 되고 있는 플랫폼으로는 구글의 양방향 언어모델 버트(Bert), OpenAI의 단방향 언어모델 GPT-2, 기계신경망 번역(Transformer) 모델 등을 꼽을 수 있다.
👀 코랩 사용법, 한국어 적용 예제 : https://gimkuku0708.tistory.com/12 , https://github.com/gimkuku/GPT3-colab/blob/main/%EC%8B%9C%EC%A1%B0%EC%B0%BD%EC%9E%91.ipynb
👀 GPT3 활용 사례 : https://uipath.tistory.com/44
② RNN
(1) Idea
- RNN 은 sequential data 를 처리하는 가장 기본적인 신경망이다.
- RNN 은 현재는 많이 사용되지 않으나, 조상격에 해당하는 모델이기 때문에 배워두어야 한다 ⭐
- internal state (memory) = hidden state 를 가지고 있어서 다양한 길이의 input sequence 를 처리할 수 있는 신경망이다.

(2) Unrolled Recurrent NN
- 보통 RNN 은 시간상으로 풀어서 recurrent 구조를 표현한다.

(3) Simple RNN
- 간단한 RNN 은 vanilla RNN 이라고도 부른다.
◾ RNN 구조의 수학공식
- 매 time step 마다 hidden state 값을 update 해준다.

◾ Many-to-Many 구조의 simple RNN
- 각 time step 별로 같은 weight matrix 를 사용한다.
- time step 별로 도출된 loss 를 모두 합하여 하나의 loss 로 결과를 도출한다.

(4) Example : Character-level language model
- Training : 원핫벡터 형태로 각 글자가 input 으로 들어오며 훈련이 이루어진다. 훈련으로 얻어진 weight matrix 들을 inference 과정에 그대로 활용한다.
- Inference : 훈련된 모델을 가져와 입력에 대한 답을 추론하는 과정으로, input 에 'h' 글자만 넣어주면, 차례로 e,l,l,o 를 결과값으로 도출한다. 이때 소프트맥스 함수를 사용하여 각 step 별 output 글자를 도출해낸다.

(5) Multi-layer RNN
- 실제로는 multi-layer RNN 구조가 많이 활용된다.
- hidden state 를 여러 layer 로 늘린 구조

③ 기울기 소실 문제
Grandient Vanishing Problem
- Vanilla RNN 은 현재 전혀 사용되지 않는데, 그 이유는 기울기 소실 문제가 RNN 에서 심각하게 존재하기 때문이다.
- graidnet 가 흘러가며 점차 작은 값으로 수렴하기 때문에 앞단 layer 의 weight update 가 이루어지지 않는다.

- Vanilla RNN 은 문장의 길이가 길어질수록 학습이 잘 되지 않는다.
- 역전파 과정에서 Loss function 에 대한 weight matrix 미분값을 구하고자 할 때, time step 이 길수록 소수값들이 점차 곱해져서 weight gradient 값이 0에 수렴하게 된다.

2️⃣ LSTM
⭐ RNN 의 기울기 소실 문제를 개선한 모델
① Architecture
👀 hidden state 에서 LSTM 구조가 쓰인다.


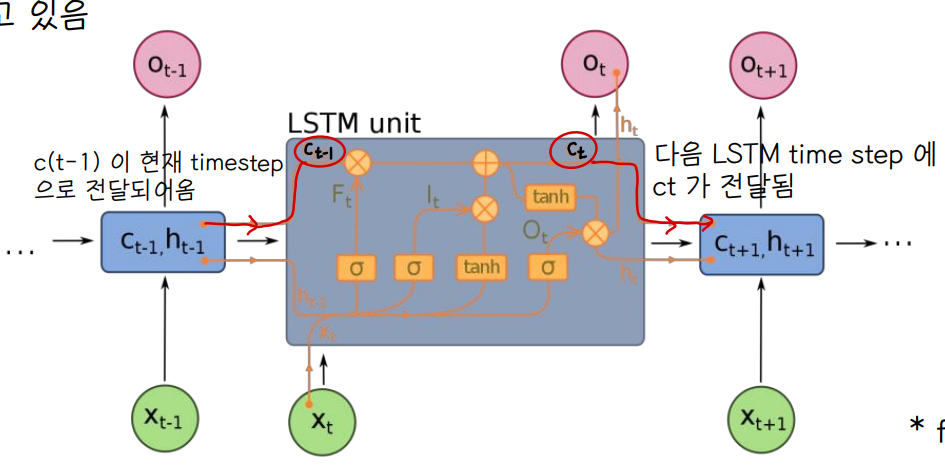
✔ 그림에서 output gate notation Ot 와 output notation Ot 헷갈리지 않기
(1) Forget gate
- 0과 1사이의 값을 가진다.
- cell 에 저장된 기억을 잃어버릴지 말지 결정한다. whether to erase cell
- Ct 값을 구할 때, C(t-1) 이전 cell 에서 얼만큼 정보를 보존할지 결정
(2) Input gate
- 0과 1사이의 값을 가진다.
- cell 에 이전 step의 hidden state h(t-1) 값과 현재 input 값 xt을 얼만큼 반영할지 결정한다. whether to write to cell
(3) Output gate, Ot
- 0과 1사이의 값을 가진다.
- Ct , 현재 memory cell 이 현재 hidden state ht 생성에 반영되는 정도를 결정한다 👉 long term memory Ct 가 short term memory ht 에 얼마만큼 반영될지 결정한다.
(4) Cell
- 임의의 시간동안 어떤 값을 기억하는 역할 (메모리) 을 수행하는 부분이다.
- long term memory 를 저장하는 역할을 수행한다.
② LSTM Gradient Flow

- LSTM 의 Gradient 형태는 forget output 이 반복적으로 곱해지는 형태이다.
- 따라서 훈련을 통해 forget gate 가 거의 1의 값을 가진다면, 기울기 소실 문제를 해결할 수 있다.
◾ 훈련을 통해 forget gate 가 1의 값을 가지도록 한다는 것의 의미
- 이전 step 의 cell 의 값을 거의 그대로 반영한다.
- long term memory 를 거의 항상 가지고 있는다.
- 긴 문장에서도 앞에 있던 단어를 잃어버리지 않는다.
3️⃣ Attention
① 기계번역 (Seq2Seq)
(1) Encoder - Decoder

💨 Language Translation Example
- 번역이란 input sequence 를 통해 output sequence 를 생성하는 것으로 sequence to sequence model 이라 부른다.
💨 Encoder
- 번역하고자 하는 대상 문장을 input 으로 받아 단어로 쪼개서 time step 마다 input 으로 받는다.
- input word 에 대해 hidden state Zi 를 도출해내고, output 이 FC layer 를 거쳐서 context vector 로 압축된다.
- Context vector 는 decoder 의 매 input step 마다 함께 입력된다.
💨 Decoder
- context vector 를 참조하여 번역을 수행한 결과를 도출해낸다.
- 문장이 시작된다는 의미를 가진 start token 을 모델에 넣어주면, person 을 output 으로 내놓고, person 이 다시 다음 단계의 입력으로 들어가는 구조를 가진다.
(2) RNN-based Seq2Seq Problem
💨 Information Bottleneck
- Encoder → context vector → decoder 로 전달하는 과정 속에서, 만약 문장이 길어지면 그것을 하나의 context vector 로 축약하는 과정에서 정보의 손실이 크게 발생할 수 있다

② Attention
(1) Intuition

- Seq2Seq 에서 발생되는 정보의 손실 문제를 해결할 방법 ⭐ attention
- 번역을 할 때, 어디까지 현재 번역을 진행했고 다음 번역을 이루어낼 때, input 문장에서 중요하고 관련이 높은 단어들에 좀 더 주목하여 그 단어들에 대해서 가중치를 부여하겠다는 아이디어
- 단어간 관련성을 계산하여 attention 값을 도출 (하얀색일수록 관련성이 높은 단어쌍)
- 번역문들 사이에 어순이 일치하지 않아도 잘 번역되는 것은 attention 덕분
(2) Attention in Seq2Seq
💨 overview
👀 hat 을 번역 결과로 도출하는 단계에 해당하는 예제

- Attention 은 LSTM 에서 덧붙여 사용하는 도구라고 생각하면 된다.
- Attention score , attention distribution 을 차례로 도출하고 attention value 를 도출하여 번역 과정에 활용한다.
- attention 이 없는 구조에서는 전체 time step 에 대해 하나의 context vector 로 뭉틍그려 번역하였다면, attention 이 있는 구조에선 매 time step 마다 attention 을 기반으로 context vector 가 생성되어 입력되므로 정보의 손실이 발생하지 않고 더 좋은 성능으로 번역이 가능하다.
💨 Attention Score
- scalar 값으로 얻어짐 : e1,e2,e3,e4
- 현재 번역하고자 하는 time step 에서 decoder 의 hidden state ht 와 encoder 의 각 time step 에서의 hidden state 들 z1,z2,z3,z4 를 곱해 attention score 를 얻는다.
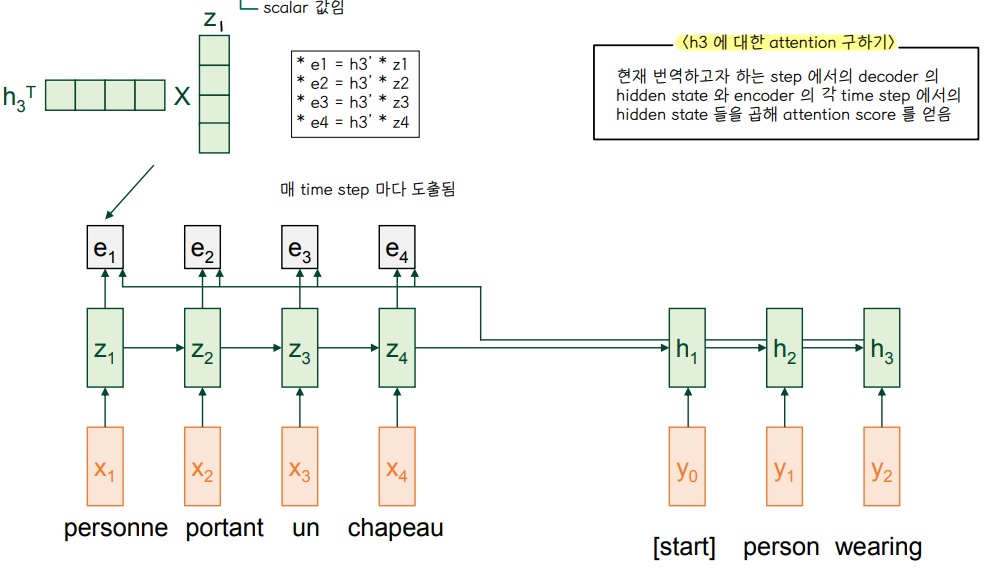
💨 Attention distribution
- attention score 들은 softmax 층을 거쳐 확률분포 값을 얻게 된다.

💨 Attention Value
- 도출된 attention distribution 값과 encoder 의 hidden state 들을 각각 곱하여 더한 결과 C3 를 얻는다.
- C3 는 h3 에 대응되는 attention value 값으로 context vector 라고 볼 수 있다.

💨 Output
- 앞서 구한 C3 와 h3 를 concatenate 한 벡터와 Weight matrix 값을 tanh 연산하여 얻은 값 h3' 를 소프트맥스 취하면 output 인 'HAT' 단어가 도출된다.

'1️⃣ AI•DS > 📒 딥러닝' 카테고리의 다른 글
| [인공지능] Transformer Models (0) | 2022.06.11 |
|---|---|
| [인공지능] NLP (0) | 2022.06.10 |
| [인공지능] Regularization (0) | 2022.04.26 |
| [인공지능] 다양한 CNN 모델 (0) | 2022.04.26 |
| [인공지능] Training CNN (0) | 2022.04.26 |




댓글