728x90
📌 교내 '인공지능' 수업을 통해 공부한 내용을 정리한 것입니다.
1️⃣ Regularization
① Loss function
(1) Cross Entropy loss function
- 분류문제에서 많이 사용되는 비용함수
- ti 와 oi 의 거리를 측정하여 두 값이 다를수록 즉, 거리가 멀수록 loss 가 증가한다. 두 값의 차이가 1에 가까울수록 즉 error 가 존재할 때 loss 가 증가하고 차이가 0에 가까울수록 loss 가 낮아진다.

◾ ti : ground truth label
◾ oi : NN output
◾ C : number of class
👀 엔트로피가 높다 = NN 의 예측이 불확실하다.
👀 엔트로피가 낮다 = NN 의 예측이 확실하다.
(2) Entropy
- 확률변수의 불확실성
- 확률변수 X
- 확률변수에 대한 확률분포 : p(x)
- H(x) 식에 음수가 붙게된 이유 : p(x) 는 0과 1 사이의 값을 가지게 되므로 log 값이 음수가 나오기 때문에 다시 양수로 변환해주기 위함 + p(x) 의 불확실성이 높아질수록 엔트로피 값이 커져야 함

👀 엔트로피가 낮다 = 삼각형이나 원을 뽑을 확률이 명확하다 = 주어진 모양을 뽑을 확률이 확실하다.
- Container2 의 경우 원과 삼각형 중에 무엇을 뽑게될지 불확실하므로 엔트로피가 높다.
(3) loss function 의 종류
1. binary cross-entropy loss for binary classification

2. Categorical cross-entropy loss for multi-class classification

② Regularization
- 오버피팅을 방지하기 위해 추가적인 정보를 넣어주는 것
- 가장 흔한 패턴 : 훈련 과정에 임의성 randomness 을 부여하는 것 👉 랜덤한 노이즈를 포함하여 학습이 이루어지므로 미래의 일반화된 데이터에 대해 잘 대응한다.

③ Overfitting
- 일반화가 이루어지지 않고 특수한 상황에 대해서만 맞춰서 훈련이 된 상황
- high variance 👉 validation error much higher than training error

2️⃣ 오버피팅을 막는 방법
① Use Validation set
검증데이터는 학습률, 에포크수, 은닉층 개수 등의 모델의 파라미터를 최적화하는데 사용한다.
- Validation set is used to optimize the model parameters while the test set is used to provide an unbiased estimate of the final model
- 테스트 데이터셋은 검증데이터 셋을 통해 결정된 최종 모델의 성능을 평가하는데 사용한다.
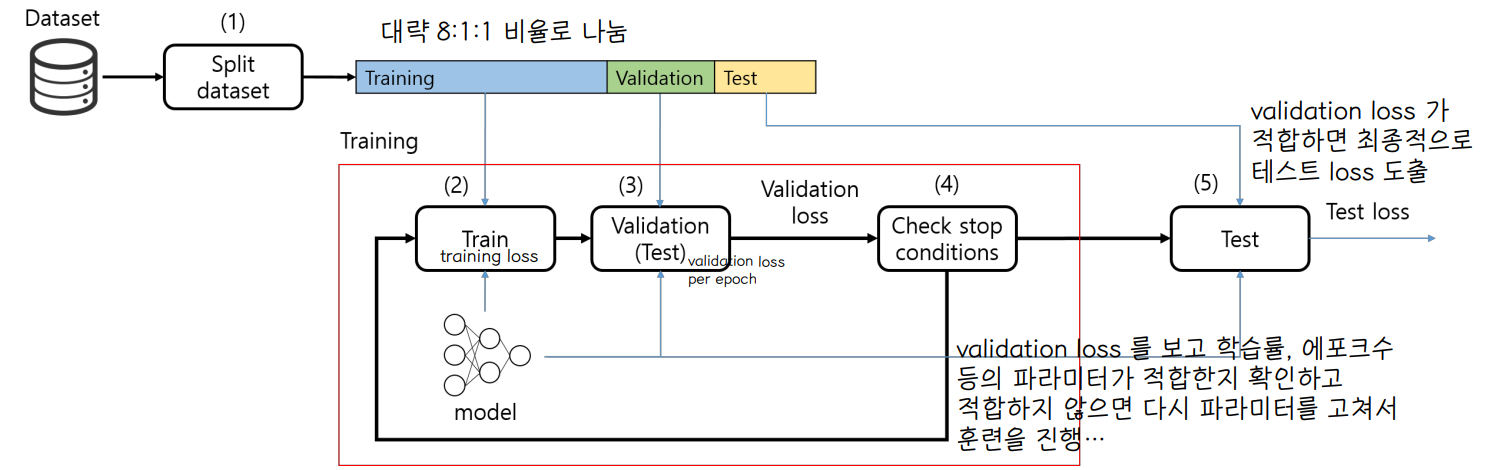
- validation 과정 또한 학습에 영향을 미친다. 파라미터를 변경할 때 validation loss 를 보고 변경하는데,이렇게 지속적으로 파라미터를 바꾸는 것 자체가 validation dataset 에 optimize 된 파라미터로 바꾼다는 의미! 👉 이걸 최종 output 으로 내면 일반화가 어려움 (validation 에 bias 된 모델을 만들게 됨)
- 일반적인 모델을 만들려면 학습 과정에 전혀 참여하지 않은 test data set 이 필요하다 👉 어느 상황에도 bias 되지 않은 모델의 성능을 도출할 수 있게 된다.

② 모델의 복잡도 낮추기
- 주어진 데이터의 특징에 비해 너무 복잡한 모델을 사용하면 오버피팅이 발생한다.

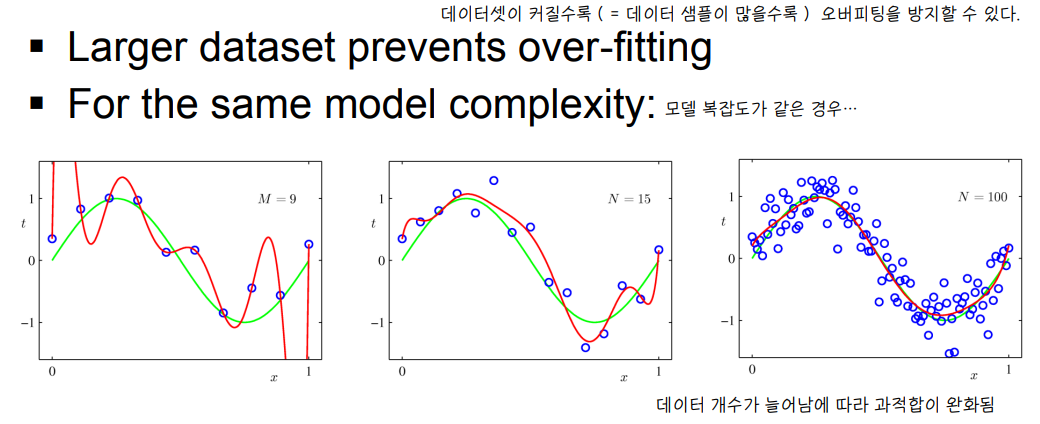
③ Larger Dataset Size
- 데이터가 많을수록 오버피팅을 막을 수 있다.
👀 Data Augmentation 데이터 증강
- 이미지 분류 문제에서 데이터가 많지 않을 때 사용할 수 있는 대표적인 방법

④ Weight decay
- 오버피팅이 일어날수록 가중치 값이 커지는 경향이 있음 (특정 상황에만 맞는 가중치를 많이 증가시킴)
- 가중치 값을 작게 유지할 수 있도록 loss function 에 L1 혹은 L2 정칙화 부분을 error function에 넣어줌
- λ lambda : weight decay 의 영향력을 조절하는 파라미터

⑤ Early stopping

⑥ Dropout
- connection 이 없이도 훈련될 수 있도록 유도 👉 일반화 = 노이즈를 삽입한 효과
- 훈련단계에서 뉴런 사이의 연결(시냅스)을 랜덤하게 끊음 (drop)
- 하이퍼파라미터 P : p 비율만큼 연결을 제거
- 예시. dropout 0.5: drop half of connections
- Test 단계에서는 전결합 네트워크를 사용한다.

⑦ Batch Normalization
이미지의 input feature 혹은 activation 들의 평균과 분산을 특정한 값으로 바꿔주는 과정
각 레이어마다 정규화 하는 레이어를 두어, 변형된 분포가 나오지 않도록 조절하게 하는 것이 배치 정규화
👀 mean 을 바꾼다 = 전체 픽셀값을 shift 하는 효과
👀 variance 를 바꾼다 = 픽셀값을 scaling 해주는 효과
👀 이미지를 이렇게 변환하면 regularization 효과를 가져다줘서 훈련이 더 잘된다.
👀 매 layer 마다 평균과 분산값이 존재 : 평균과 분산값 자체를 훈련함 👉 이미지가 어떤 방향으로 shift 되고 scaling 되어야 가장 적합한 normalization이 되는지 기계가 알아서 찾음


728x90
'1️⃣ AI•DS > 📒 딥러닝' 카테고리의 다른 글
| [인공지능] NLP (0) | 2022.06.10 |
|---|---|
| [인공지능] RNN (0) | 2022.06.07 |
| [인공지능] 다양한 CNN 모델 (0) | 2022.04.26 |
| [인공지능] Training CNN (0) | 2022.04.26 |
| [인공지능] CNN (0) | 2022.04.23 |




댓글