📌 교내 '인공지능' 수업을 통해 공부한 내용을 정리한 것입니다.
➕ https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
Transformers
pratical tips for Natural Language Processing
ratsgo.github.io
Summary
✨ Transformer
기계 번역(machine translation) 등 시퀀스-투-시퀀스(sequence-to-sequence) 과제를 수행하기 위한 모델
◾ Attention is all you need : Encoder + Decoder block
◾ encoder 부분에서 병렬적으로 문장의 모든 단어를 동시에 처리한다.
◾ 속도가 빠르고 모든 맥락을 전부 attention 하므로 기계번역 성능도 좋아짐
✨ BERT
◾ Pre-training of Deep Bidirectional Transforemrs
◾ encoder 부분만 차용
◾ Pre-training
- maked language model 👉 self supervised learning
- next sentence prediction 👉 supervised learning
✨ GPT
◾ Generative Pre-training Transforemrs
◾ decoder 부분만 차용 → BERT와 달리 순차적 구조를 가진다.
◾ Next word prediction 으로 사전훈련된 모델로 fine-tuning 과정은 BERT와 유사하다 .
👀 같은 파라미터 개수 대비 BERT 성능이 더 좋음
👀 초거대 AI 를 만드는데 있어서는 GPT 가 더 유리한 구조
Recap
✨ seq2seq
- 특정 속성을 지닌 시퀀스를 다른 속성의 시퀀스로 변환하는 작업
- 길이가 달라도 해당 과제를 수행하는 데 문제가 없어야한다.
- 모델의 구조는 대게 인코더-디코더 파트로 구성된다.

✨ Attention
◾ Encoder → context vector → Decoder 👉 information bottleneck problem 👉 해결책 : Attention
◾ 전체 문맥을 모두 고려해 그 중에서 특별히 연관성이 높은 단어들을 주의깊게 보는 방법 → assign higher weights
◾ decoder 쪽 RNN(LSTM) 에 어텐션을 추가한다.
◾ 타깃 언어를 디코딩할 때 소스 언어의 단어 시퀀스 가운데 디코딩에 도움이 되는 단어들 위주로 선택하여 번역 품질을 끌어올린다. 즉, attention 은 디코딩할 때 소스 시퀀스 가운데 중요한 요소를 추린다.
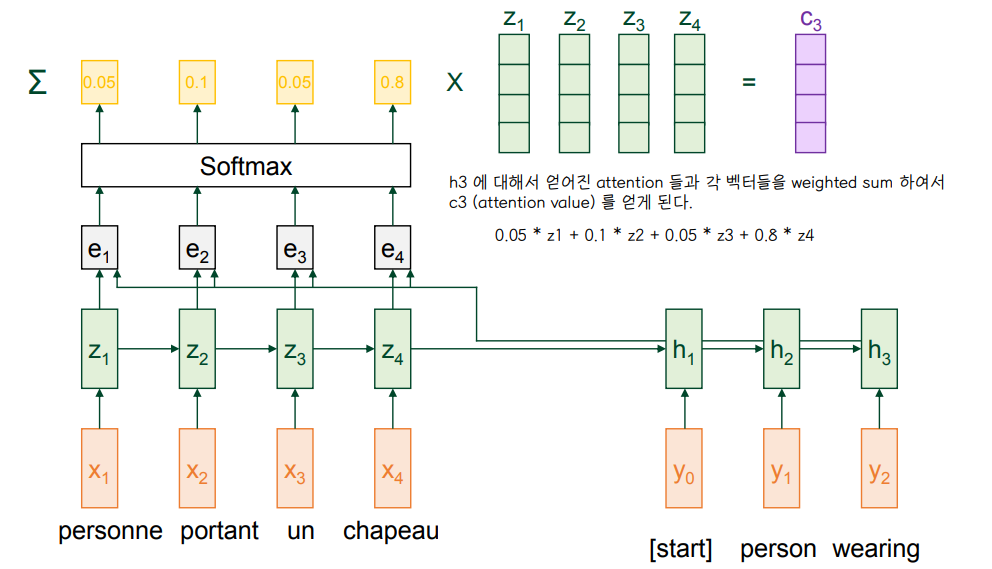
1. Attention Score
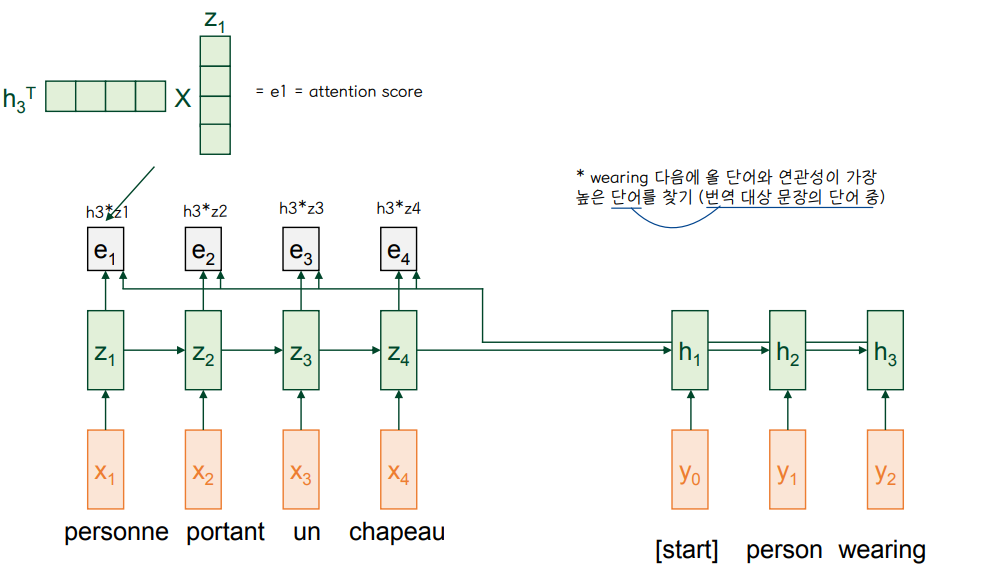
2. Attention Distribution
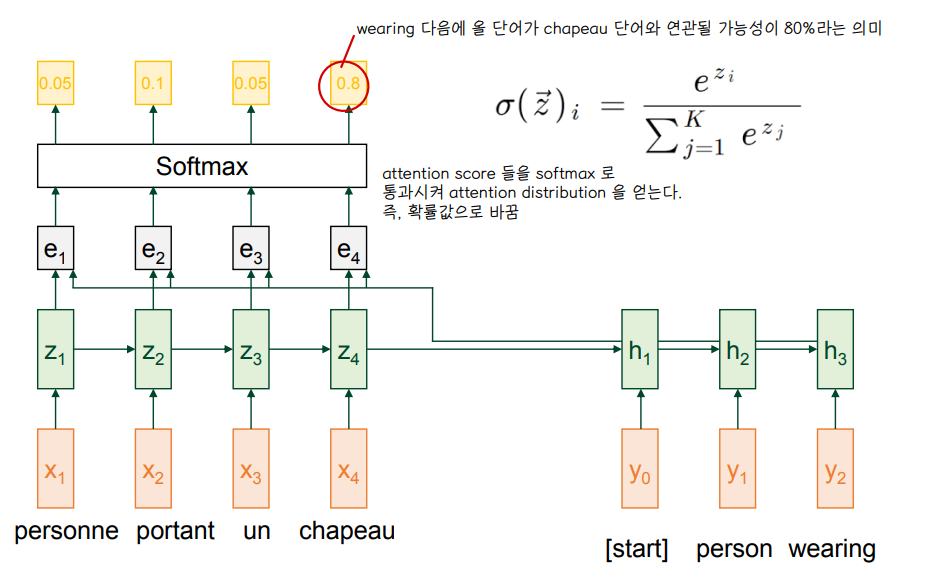
3. Attention Value
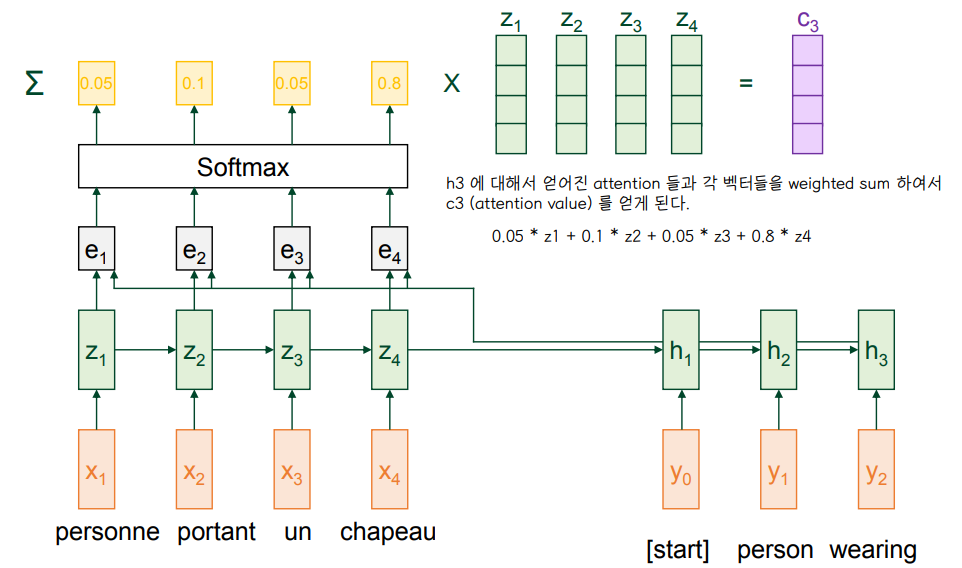
- h3 에 대응되는 wearing 이라는 단어의 attention value C3 를 얻는다.
- 각 단어에 대해 C1,C2,C3 등 attention value 를 얻는 과정을 반복
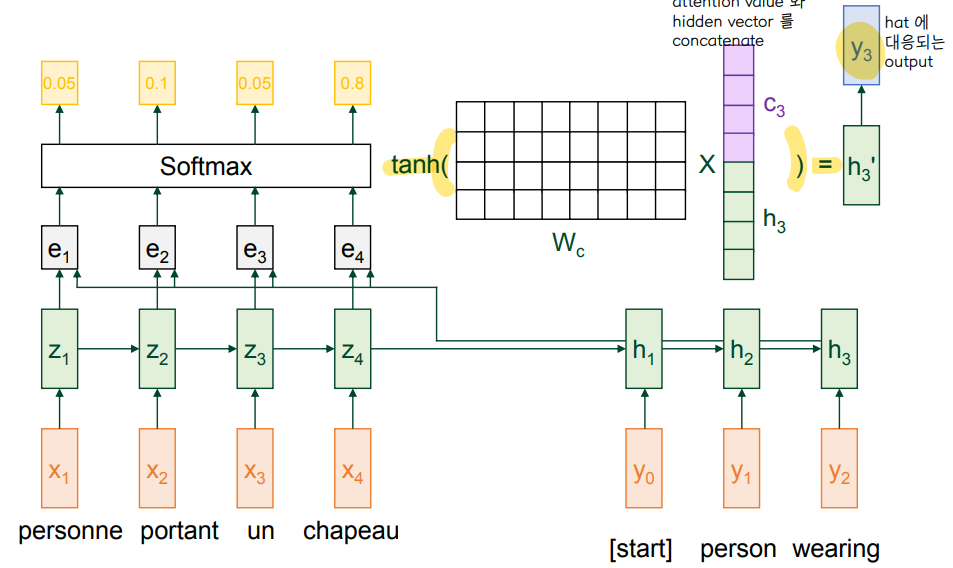
4. Calculate Output
1️⃣ Transformer
👀 현재 자연어 처리 관련 인공지능을 구현하는 데 있어 대부분 쓰이고 있는 구조
👀 BERT, GPT 같이 자연어처리를 위한 거대 NN 들이 transformer 모델을 기반으로 하고 있다.
① Attention is general technique
🔘 범용적으로 사용 가능한 모델구조
- 기계번역에서 Attention 이 큰 성능 개선을 보여주었다.
- 그러나 CNN 을 포함한 많은 모델 구조에 대해서도 Attention 을 사용할 수 있다.
🔘 일반적인 정의
- Value vector, Query vector 를 통해 weighted sum 값을 얻는다.
- weighted sum Value 를 통해 Query 에 dependent 한 attention 을 찾는다. (compute a weighted sum of values dependent on the query)
- Query 가 value 에 attend 한다고 말할 수 있다.
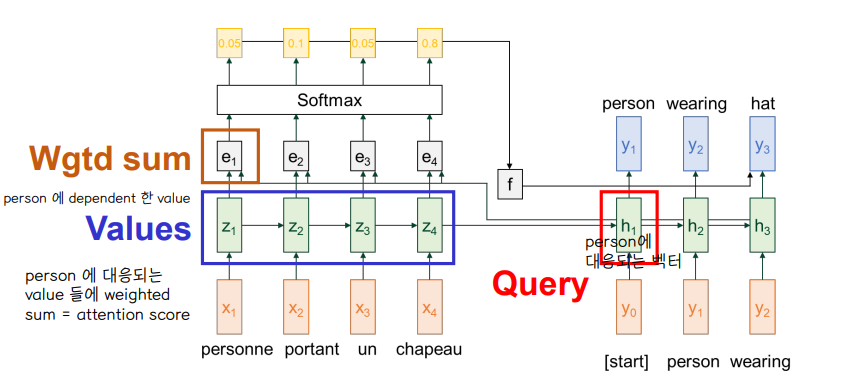
🔘 기계번역
- Query : 번역하고자 하는 단어 (h3)
- Value : 각 단어에 대응되는 attention 값들 (z1,z2,z3,z4)
- attention 값들을 weighted sum 하여 attention score 를 얻음
🔘 weighted sum : value 에 포함된 정보를 선택적으로 요약
- The weighted sum is a selective summary of the information contained in the values where the query determines which values to focus on
- ⭐ query 가 어떤 value 에 집중해야 할지를 정하게 된다.
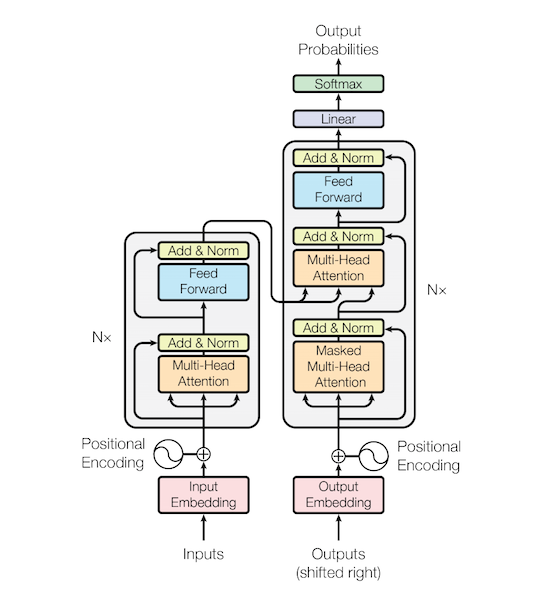
② Transformer : Attention is All You Need
👀 기존의 기계번역 : RNN(LSTM) + Attention 구조
⭐ RNN 부분을 제거하고 attention 만 가지고 기계번역을 수행할 수 있을까에 대한 연구 → Transformers

1) Model Architecture
🔘 Get rid of the sequential parts : RNN 과 같이 순차적으로 처리하는 부분을 모두 제거하여 연산속도를 높인다.
- Transformer 는 순차적인 형태의 개념을 병렬적으로 동시에 처리한다
- 순차적인 입력에 따라 순차적으로 연산을 진행했던 RNN 구조보다 연산속도가 훨씬 빨라질 수 있게 된다
🔘 Encoder - Decoder with only attention and fully-connected layers 👉 no recurrence or convolutions
- 순차적 연산을 필요로 하는 recurrence layer 나 혹은 Conv layer 가 필요 없다.
- multi-head attention + feed forward (=fully connected) 만 가지고 연산을 수행
🔘 (Encoder - Decoder) x N stacks
- Encoder-decoder 구조가 N 개 만큼 쌓인 형태
- Encoder 는 input 에 대해 순차연산을 수행하지 않지만, decoder 는 순차연산 (문장의 왼쪽에서부터 오른쪽으로 decoding) 을 수행한다.
🔘 Encoder 3가지 구성요소
- Self-attention (multi head attention)
- positional encoding
- layer normalization
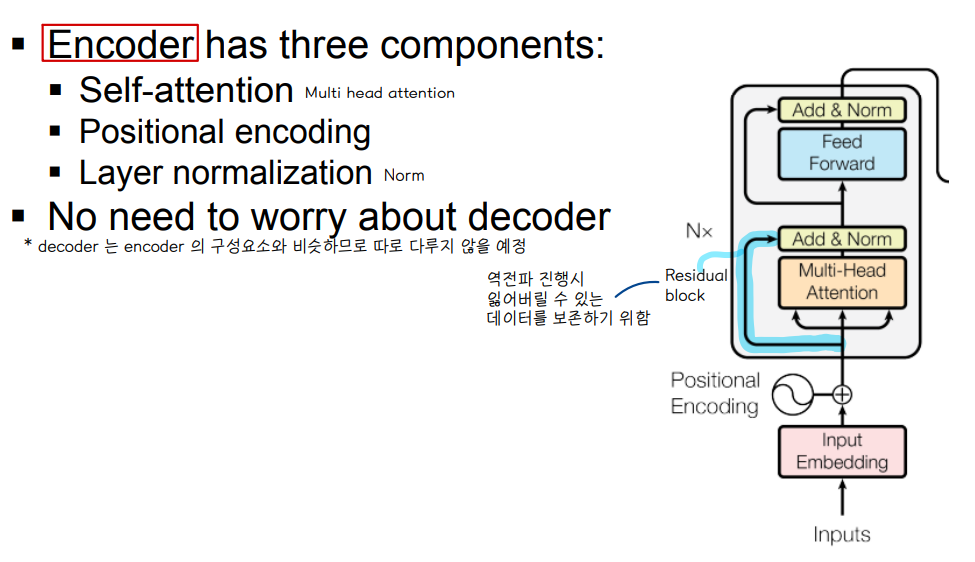
- add & Norm : 들어오는 input 과 multi-head attention output 을 add 해주고 normalization 연산을 해줌
- feed forward = fully connected
🔘 트랜스포머의 학습(train)은 인코더와 디코더 입력이 주어졌을 때 모델 최종 출력에서 정답에 해당하는 단어의 확률 값을 높이는 방식으로 수행된다.
2) Self Attention
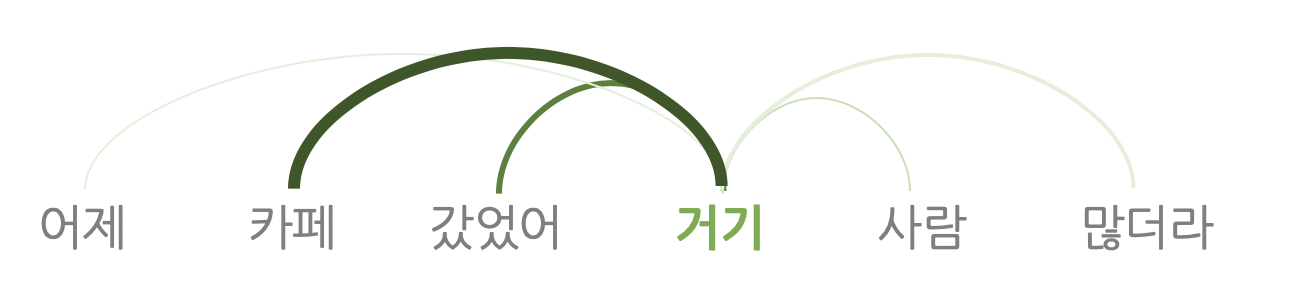
👉 ex. 인코더 블록 내부에서는 '거기' 라는 단어를 인코딩할 때, '카페', '갔었어' 라는 단어의 의미를 강조해 반영한다.
🔘 decoder, RNN 없이 자기 자신에 대해 attention 을 수행한다.
- 개별 단어와 전체 입력 시퀀스를 대상으로 어텐션을 수행해 문맥 전체를 고려한다. 아울러 모든 단어쌍의 경우의 수를 고려하므로 시퀀스 길이가 길어져도 정보를 잊을 염려가 없다.
- 어텐션은 타깃 언어를 1개 생성할 때 1회 수행하는 구조이지만, 셀프 어텐션은 인코더, 디코더, 블록의 개수만큼 반복수행한다.
🔘 input : sequence of vectors
🔘 output: sequence of vectors, each one a weighted sum of the input sequence
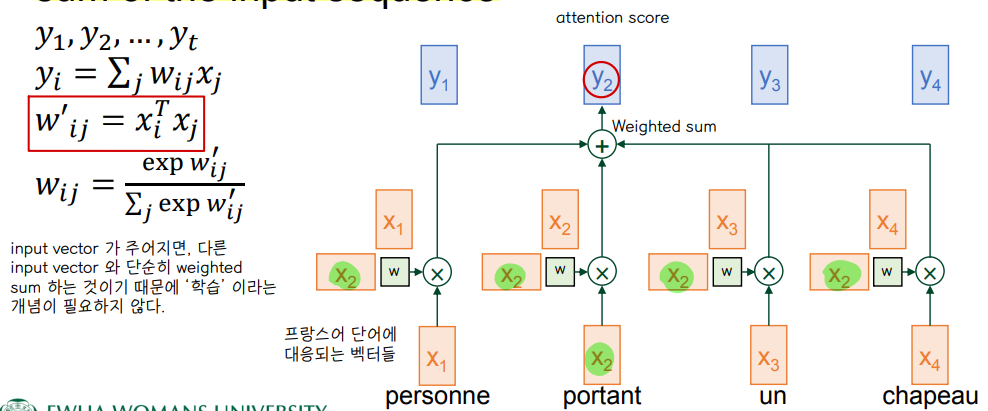
- x1 과 x2 의 내적 곱 👉 단어 간 유사도 계산
➕ https://towardsdatascience.com/self-attention-5b95ea164f61


👉 입력 문장 내의 단어들끼리 유사도를 구해, it 혹은 The 와 가장 연관있는 단어를 살펴본다.
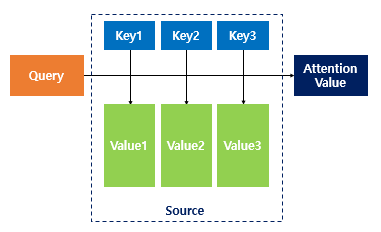
3) Query, Key, Value
🔘 Input vector 는 3가지 방식으로 쓰인다.
- Query : 어떤 벡터에 대한 attention 을 계산할 것인가
- Key : attention weight 를 계산하기 위해서 비교되고자 하는 값
- value : weighted sum 값을 만들기 위해 필요한 input vector
- 만약 입력 문장이 6개의 단어로 구성되어 있다면, 셀프 어텐션 계산 대상은 쿼리벡터 6개, 키 벡터 6개, 밸류 벡터 6개로 모두 18개가 된다.
- 셀프 어텐션은 query, key, value 3개 요소 사이의 문맥적 관계성을 추출한다.

🔘 attention 의 train 은 3가지 가중치 행렬에 대한 train 으로 이루어진다.
- query, key, value 에 대응되는 weight matrix 👉 task 를 가장 잘 수행하는 방향으로 학습 과정에서 업데이트된다.
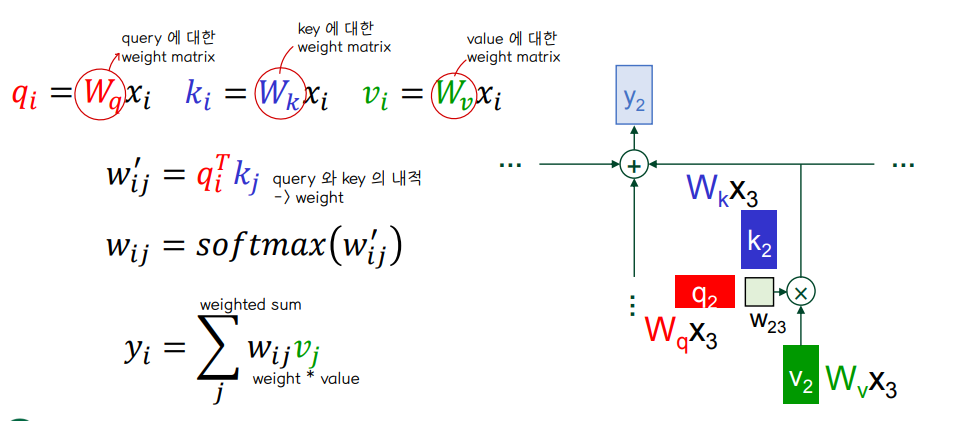
🔘 연산 과정 - 하나의 단어 임베딩 벡터 ex
(1) Q, K, V 벡터 얻기
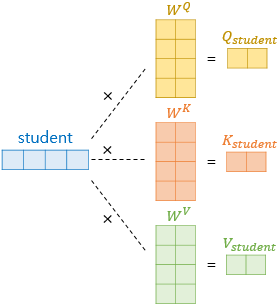
(2) q•k'
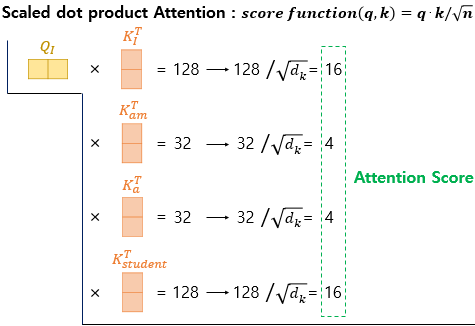
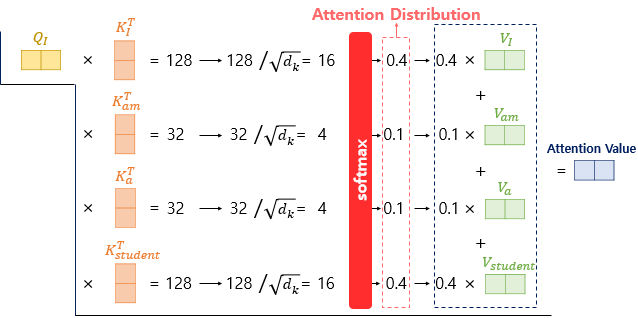
(3) softmax(w') = w , w•v
🔘 연산 과정 - 행렬 연산으로 일괄 처리
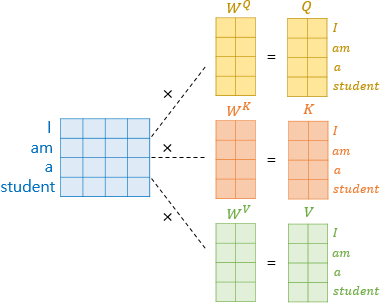
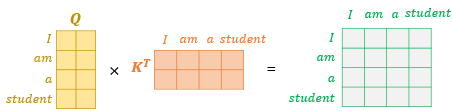
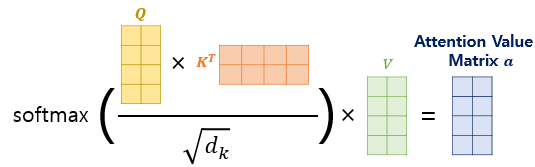
➕ https://ratsgo.github.io/nlpbook/docs/language_model/tr_self_attention/ : 연산 과정 꼭 살펴보기!
Self Attention
pratical tips for Natural Language Processing
ratsgo.github.io
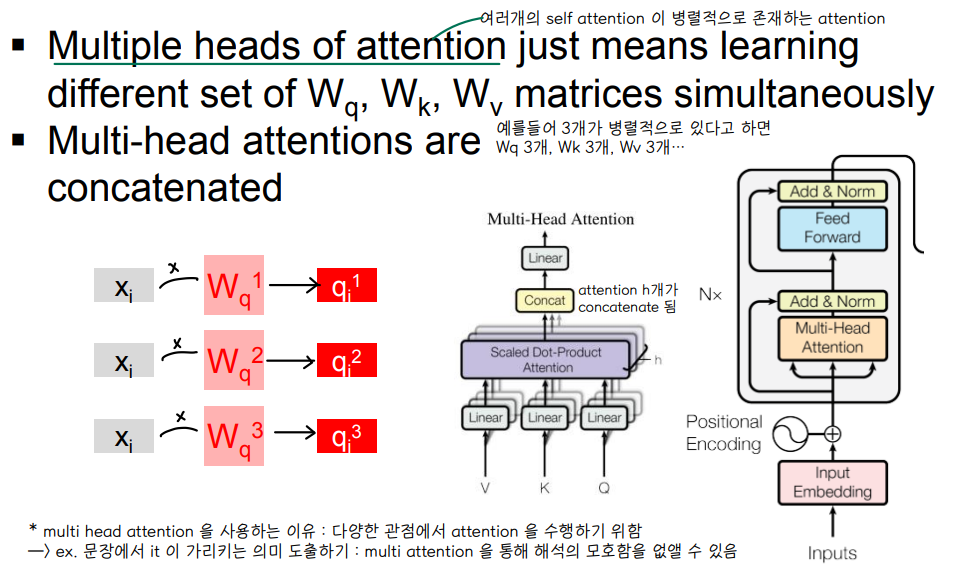
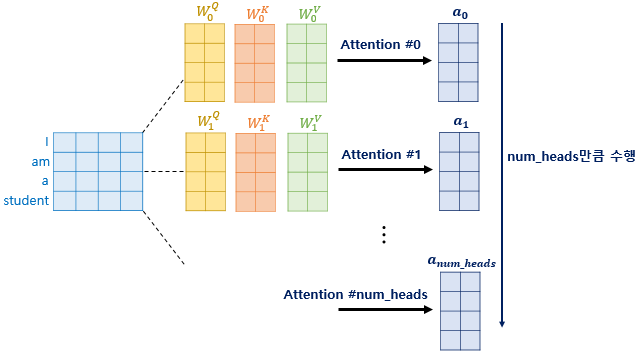
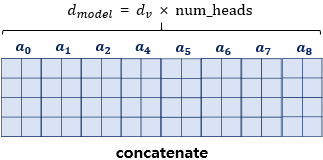
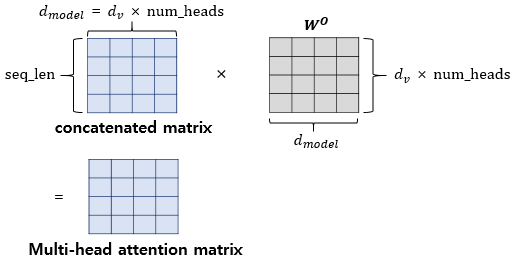
4) Multi-Head Attention
🔘 여러개의 self attention 이 병렬적으로 존재하는 attention
- self attention 을 여러번 수행 : 여러 헤드가 독자적으로 셀프 어텐션을 계산한다.
- 가령 3개가 병렬적으로 있다고 하면 Wq,Wk,Wv 가 각각 3개 존재하는 연산
- 모든 head 의 출력 결과를 concat 하여 다음 단계로 넘긴다.
- 다양한 관점에서 attention 을 수행하기 위해 multi-head attention 을 사용한다 👉 해석의 모호함을 없앨 수 있음
5) Layer Normalization
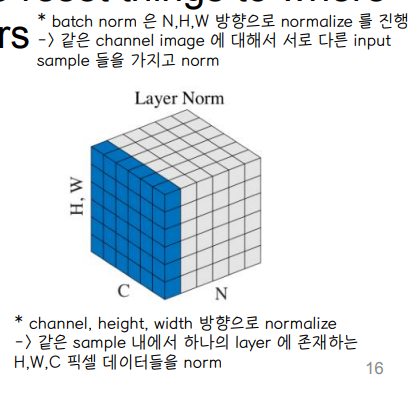
🔘 layer 는 각 차원에서 input vector 가 uniform 한 평균과 분산을 가지고 있을 때 최적의 결론을 도출해낸다.
- 미니 배치의 인스턴스(xx)별로 평균을 빼주고 표준편차로 나눠줘 정규화(normalization)을 수행하는 기법
- 레이어 정규화를 수행하면 학습이 안정되고 그 속도가 빨라지는 등의 효과가 있다.
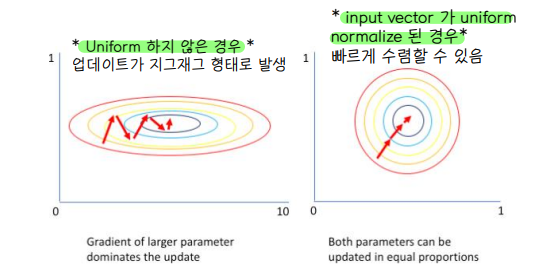
🔘 input 이 attention, FC 로 구서된 network 를 지날 때마다 평균과 표준편차가 엉망이 된다 👉 layer normalization 을 해주면 다시 mean 와 deviation 을 재정렬 시켜줄 수 있다.
6) Positional Embedding
🔘 순서 정보가 고려된 임베딩 벡터
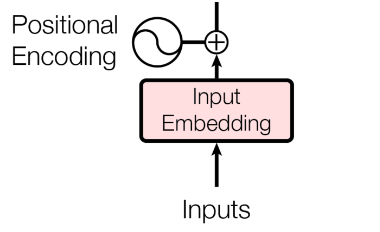
- Transformer 연산과정에서 sequence 순서가 결과에 영향을 미치지 않았지만, 언어에서는 단어의 순서가 중요하므로 각 input vector 에 대해 position 정보를 입력해야 한다.
- 인코더 입력은 소스 시퀀스의 입력 임베딩(input embedding)에 위치 정보(positional encoding)을 더해서 만든다.
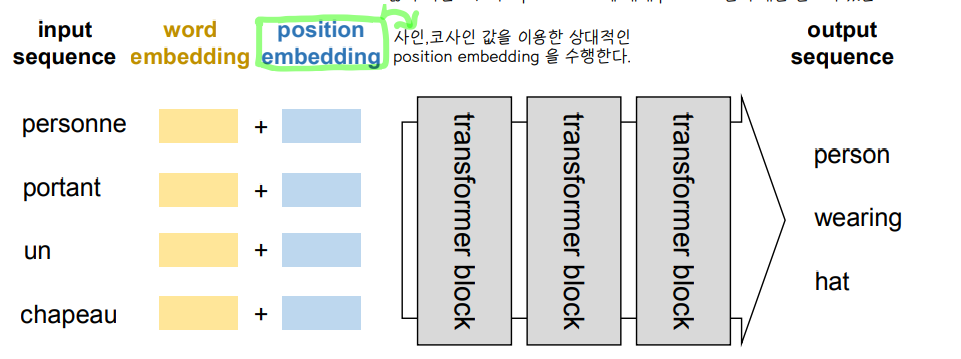
7) Mask
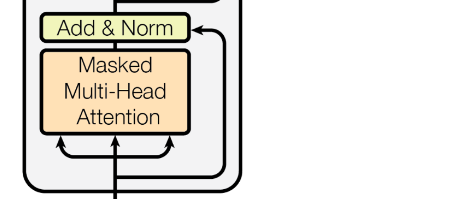
🔘 Decoder → Masked multi-head attention
- Transformer 의 self-attention 기법은 input sequence 를 한번에 다 보는 방식으로 이루어지기 때문에, sequence 의 다음 단어 예측을 위해서는 미래의 값은 attention 하면 안되기 때문에 weight 에 mask 를 씌운다.
- mask 를 씌워서 현재 attention 은 현재와 과거 값만 볼 수 있도록 한다
- Mask = 정답을 포함한 미래 정보를 셀프 언텐션 연산에서 제외 (확률이 0이 되게 함)
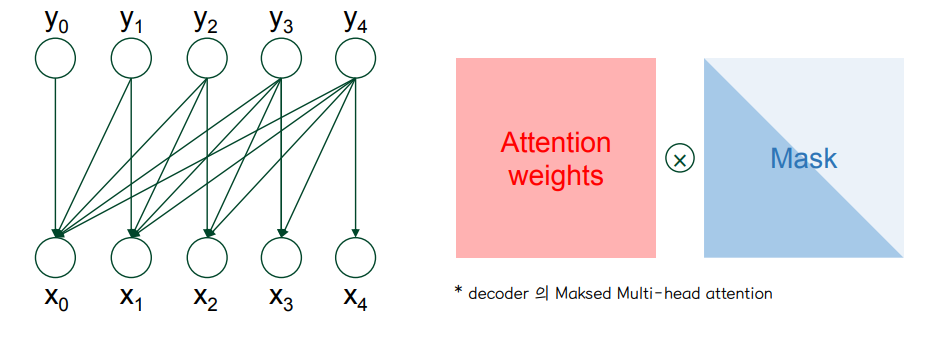
🔘 Decoder 의 attention 구조
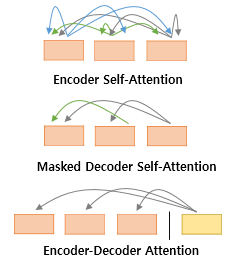
- 셀프 어텐션은 Encoder 에서 발생하는 것으로 Query, Key, Value 가 동일한 경우 (벡터의 출처가 인코더로 같다는 의미, 값이 동일한 것이 아님) 를 말한다. (1번 그림)
- Decoder 는 2번 그림의 maekd-self attention, 3번 그림의 encoder-decoder attention 이 이루어진다.
1. Encoder 셀프 어텐션: Query = Key = Value
2. Decoder masked 셀프 어텐션: Query = Key = Value
3. 디코더의 Encoder-Decoder 어텐션: Query: 디코더 벡터 <-> Key = Value: 인코더 벡터
8) Remarks
🔘 Transformer 의 성공 요인

- 매우 긴 문장에 대해서도 encoding 을 한번에 수행하므로 순차적으로 했을 때 발생하는 information loss 를 없앨 수 있다
- Transformer 를 훈련할 때 label 이 없는 데이터셋을 가지고 self supervised learning 으로 수행하는데, 그렇기 때문에 language model 을 만드는데 적합한 구조가 되었다.
🔘 Training

- Pre-training on large unlabeled datasets : self-supervised learning
- Training for downstream-tasks on labeled data : supervised learning → fine-tuning
👀 Self-supervised learning
- Unsupervsied learning 중에 한 분야에 속하는 연구주제로, 데이터셋은 레이블이 존재하지 않는 데이터만을 사용한다. 그러나 일반적인 비지도학습과는 달리, 자기 스스로 학습 데이터에 대한 분류를 수행한다.
- network 를 pretraining 시킨 뒤 downstream task 로 transfer learning 을 하는 접근방법이 핵심 개념이다.
- pre-trained : 대량의 Untagged data 를 이용해 전반적인 특징 (generalizable representations) 을 학습하는 단계
- BERT : masking 과 next sentence prediction 을 통해 모델 학습을 진행한다. 주어진 문장을 그대로 활용하기 때문에 label (tagging) 이 필요 없다.
- Downstream task : 소량의 Tagged (labeled) data 를 활용해 사용 목적에 맞게 Fine tuning 을 한다.
- BERT example : 질의응답 (Q&A) 수행이나 문장 속 감정 분류 등 목적에 맞게 layer 를 1~2개 정도 더 추가하여 Tagged data 와 함께 학습을 진행한다.
2️⃣ Transformer models

① BERT
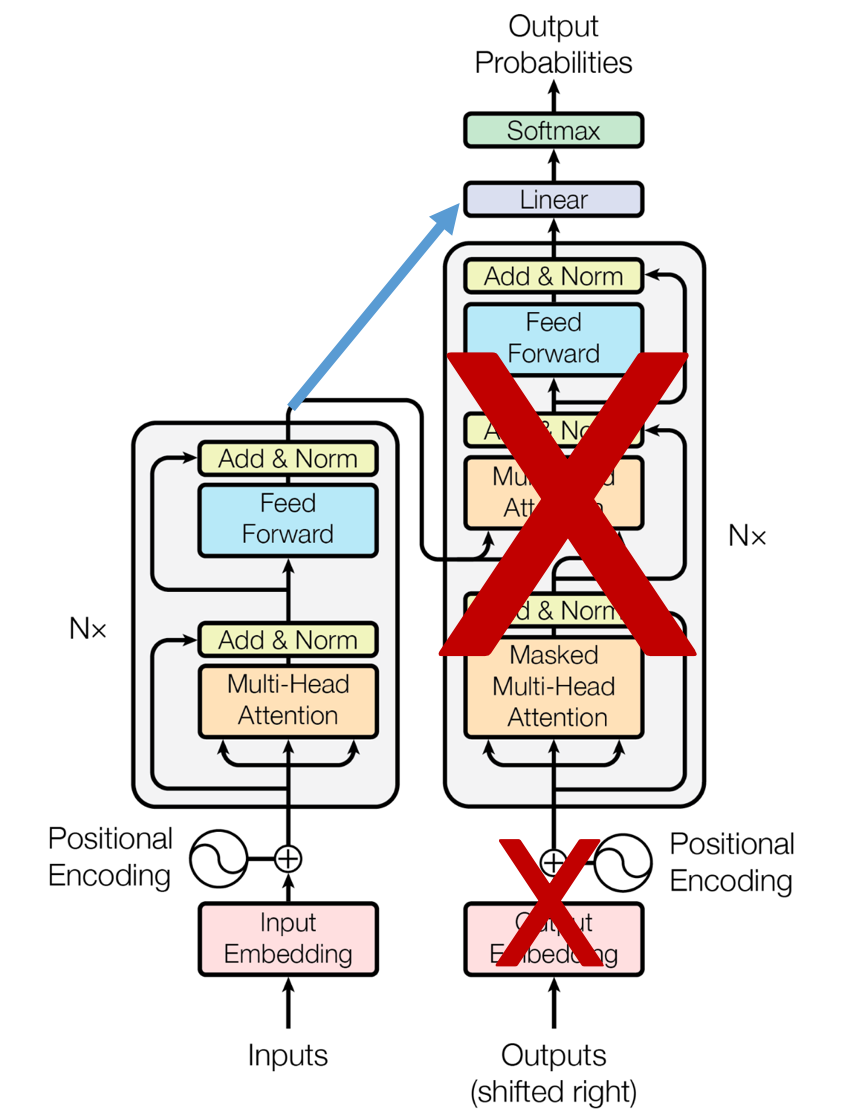
👀 Transformer 모델의 확장
- 여러층을 가진 양방향 transformer encoder 👉 빈칸 (mask) 앞뒤 문맥을 살필 수 있다.
- 기존 transformer 모델 구조에서 디코더를 제외하고, 인코더만을 사용
- 'bidirectional masking' 과 'next sentence prediction' 을 pre-training task 로 추가했다.
- Pre-training dataset 으로 self-supervised learning 을 수행한다.
- 문장의 의미를 추출하는데 강점을 가지고 있다.

1) Input
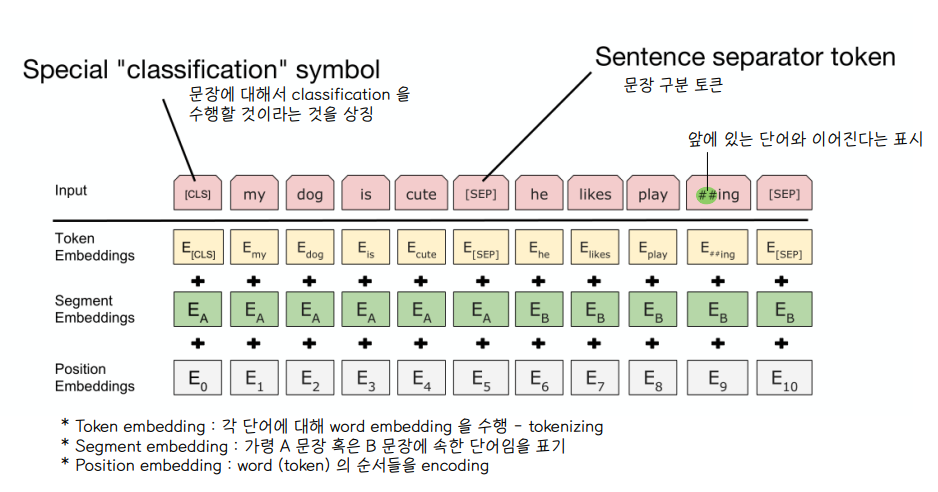
🔘 Token embedding
- 각 단어에 대해 word embedding 을 수행한다. (tokenizing)
🔘 Segment embedding
- 가령 A 문장 혹은 B 문장에 속한 단어임을 표기
🔘 Position embedding
- 단어의 순서에 대한 정보를 encoding
◼ classification symbol : [CLS] 문장에 대해 분류를 수행할 것이라는 것을 상징하는 토큰
◼ Sentence separator token : [SEP] 문장 구분 토큰
◼ play 토큰과 ##ing 토큰 : ing 가 가지고 있는 '~중이다' 라는 의미를 반영하기 위하여 play 와 구분하여 토큰화 하였고, ## 은 앞에 있는 play 라는 단어와 이어진다는 표기로 표시한 것이다.
👀 기존 Transformer 는 Next word prediction 방식으로 순차적인 decoder 를 사용하여 self-supervised training 을 진행하였지만, BERT 에서는 2가지의 차별화된 방법을 통해 Pre-train 을 진행한다.
2) Pretraining task (1) - mask language model
⭐ 문장 중간에 빈칸을 만들고 해당 빈칸에 어떤 단어가 적절할지 맞추는 과정에서 Pre-train 한다.

🔘 Replace with [MASK] : 빈칸채우기 문제를 맞추는 격으로 훈련이 이루어진다.
🔘 Replace with random word : 무작위 단어로 바꾸어줌 (regularizaiton)
🔘 leave as : 단어를 그대로 유지

3) Pretraining task (2) - Next sentence prediction
⭐ 문장을 구분하는 분류 문제를 수행하여 Pre-train 을 진행한다.

🔘 문장에 대해 이진분류를 수행
- 50%가 Is Next 이고, 50% 가 NotNext class 에 해당한다
- EX) 문장1 다음에 문장2가 올 것이냐 안올것이냐를 분류하는 문제
4) Architecture
🔘 3억 4천만개의 파라미터로 구성되어 있다.
🔘 24개의 transformer block 과, 각 block 마다 16개의 (attention multi) head 가 존재한다.
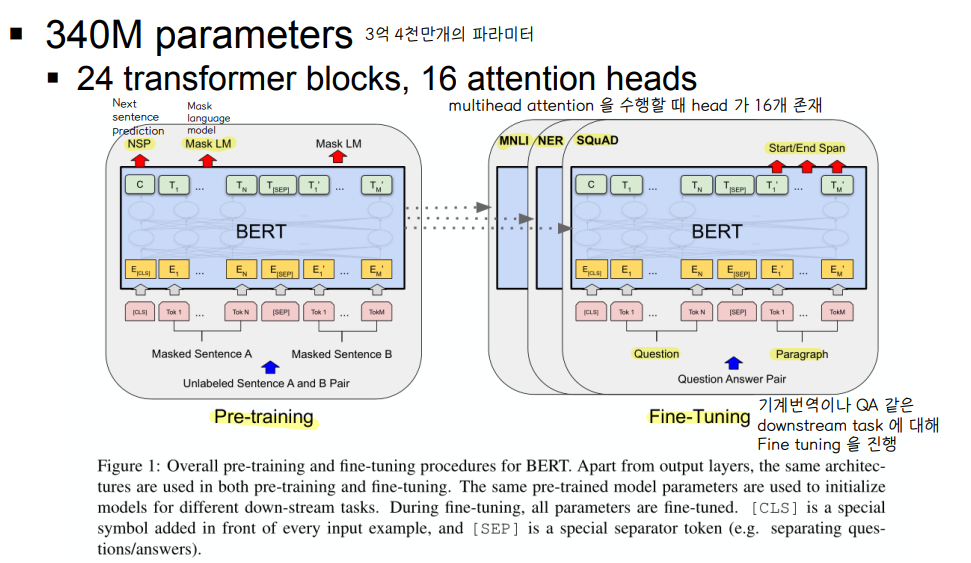
5) Fine tuning
🔘 Frozen : pre-training 이후에 BERT 의 weight 를 변화하지 않게 한다.
🔘 labeled dataset 으로 downstream task 를 수행한다 : 하나 또는 그 이상의 layer 를 추가하여 supervised learning 을 수행한다

② GPT
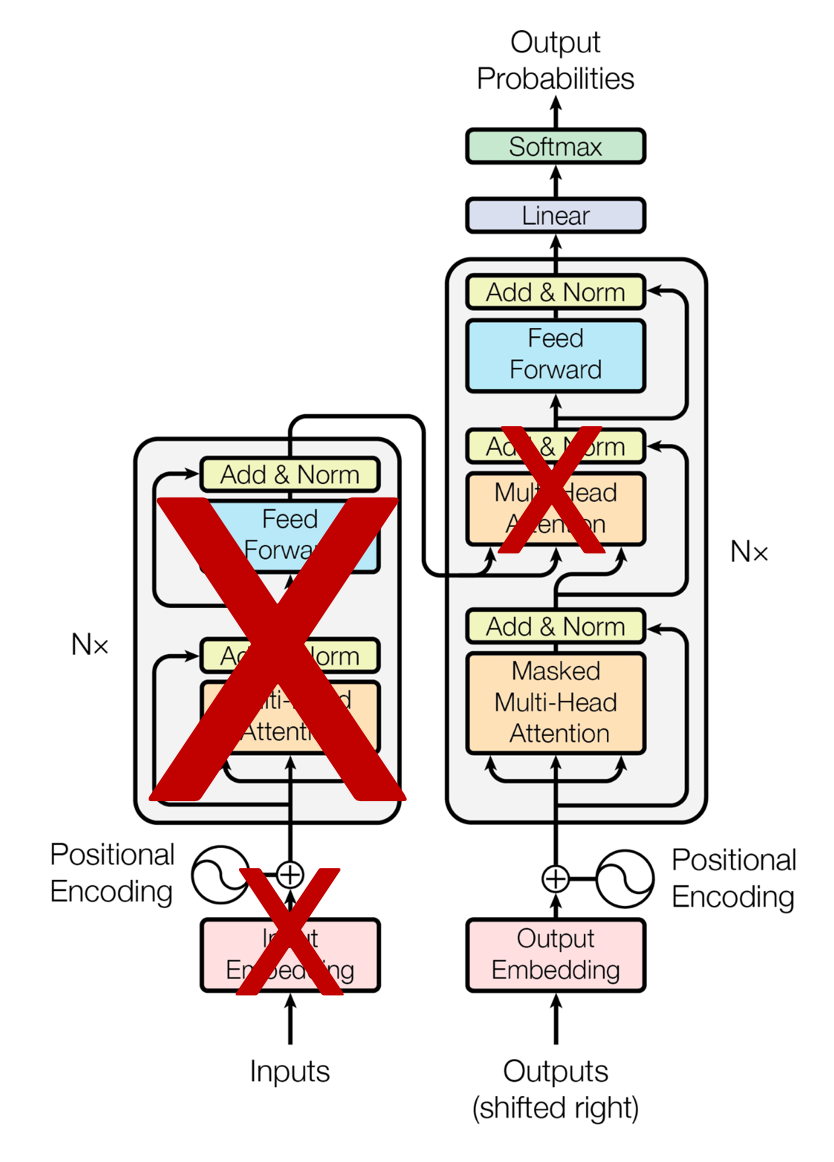
- 이전 단어들이 주어졌을 때 다음 단어가 무엇인지 맞추는 과정에서 Pre-train 하는 language model 이다.
- 문장 시작부터 순차적으로 계산한다는 점에서 일방향이다.
- 문장 생성에 강점을 지닌다.
1) Generative Pre-Trained Transformer
🔘 Developed by OpenAI
🔘 Unidirectional : trained to predict next word in a sentence
- GPT 는 BERT 와 달리 unidirectional 방향으로 traing 을 진행한다.
- 또한 일반적인 Transformer decoder 구조와 같이 next word prediction 을 하도록 훈련한다.
- 그러나 GPT 는 Transformer 에서 decoder 만 사용한다.
🔘 GPT generation

2) Key-concepts
🔘 labeled data 는 언어모델을 훈련하는데 부족하므로 self-supervised learning 방식을 선택한다.
🔘 2-step training process
1. Generative pre-training on unlabeled data : self-supervised learning
- Maksed Multi-Head Attention : 정답 단어 이후의 모든 단어를 mask (unidirectional)
2. Discriminative fine-tuning on labeled data : supervised learning
⭐ Transformer model 의 decoder 부분만 차용

3) Architecture
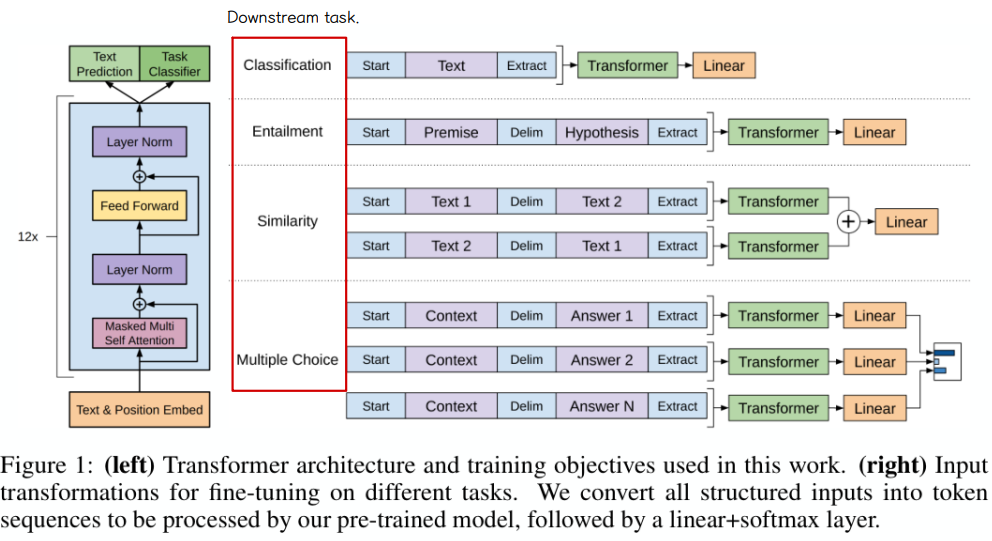
◼ pre-training 을 통해 얻은 weight 로 downstream task 에 대해 fine-tuning 을 수행한다.
'1️⃣ AI•DS > 📒 딥러닝' 카테고리의 다른 글
| [인공지능] 추천시스템 (0) | 2022.06.13 |
|---|---|
| [인공지능] GAN (0) | 2022.06.13 |
| [인공지능] NLP (0) | 2022.06.10 |
| [인공지능] RNN (0) | 2022.06.07 |
| [인공지능] Regularization (0) | 2022.04.26 |




댓글