💡 주제 : ConvNets for NLP
📌 핵심
- Task : sentence classification
- CNN, 2014 논문, 2017 논문
1️⃣ CNN
1. RNN 의 문제

✔ Prefix context 를 모두 포함
◽ the, of .. 와 같은 prefix context 없이 phrase 를 잡아내지 못한다.
◽ 이전 토큰들에 대해 연산을 모두 진행한 후 다음 토큰에 대해 연산을 진행한다.
✔ Last hidden state 에 의미가 축약됨
◽ softmax 가 마지막 step 에서만 계산되므로 마지막 단어에 영향을 많이 받는다 👉 단점을 보완하기 위해 LSTM, GRU, Attention 같은 모델들이 등장
2. CNN for text
✔ main Idea
What if we compute vectors for every possible word subsequence of a certain length?
👀 문장 내 가능한 모든 단어 subsequence 의 representation (벡터) 을 계산하면 어떨까 (모든 가능한 어절에 대해 벡터를 계산해보자)
👉 예시문장에 대해 window size 가 3인 tri-gram 으로 도출 가능한 word subsequence 들
👉 Text CNN 의 필터는 텍스트의 지역적인 정보 (단어의 등장순서/문맥정보) 를 보존한다.
✔ 단점
◽ 언어학적 Idea 가 아니다 👉 해당 구문이 문법적으로 옳은지 판단할 수 없다.
◽ CNN 은 비전 분야에 많이 적용됨
✔ CNN
◽ 이미지에 filter 를 가하여 feature 를 추출해냄
2️⃣ 1d Convolution for Text
1. 1d Conv
✔ filter 의 이동방향이 위아래로만 이동 👉 1d
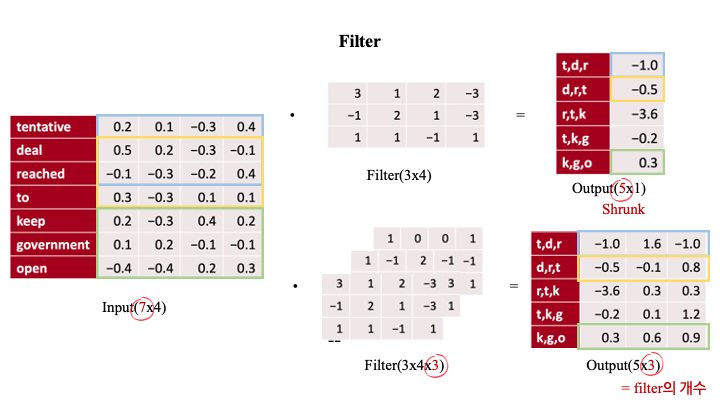
◽ input : 문장 내 각 단어를 나타내는 dense word vector
◽ fiter size = (word window size) x (word embedding vector size)
◽ input 과 filter 를 내적
◽ 결과 벡터가 shrunk → padding 적용
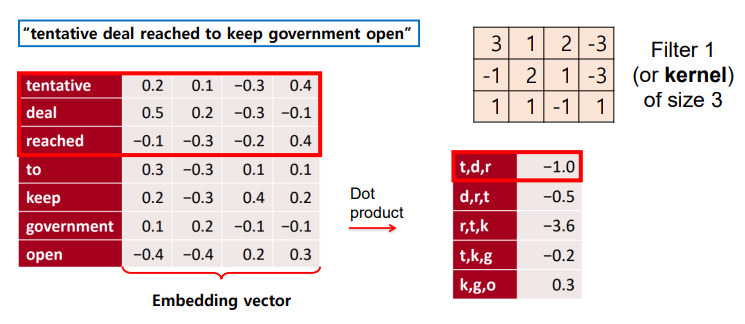
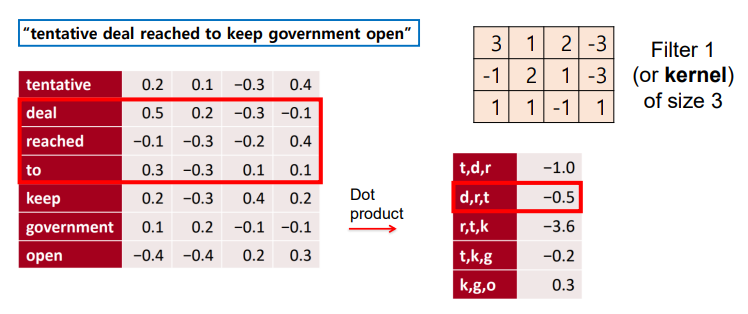
◽ embedding vector 와 filter 의 dot product 를 통해 문장 벡터를 도출한다.
◽ 사전 훈련된 임베딩을 통해 도출한 embedding vector 에 대해 1d Conv 연산 수행 👉텍스트는 하나의 토큰에 대하여 임베딩된 값들의 정보를 모두 포함하여 윈도우 슬라이딩을 해야하므로 한 방향으로 진행한다.
💨 (7x4) → (3x4 filter) → (5x1)
: 7개 각 단어는 4차원으로 임베딩 된 벡터이고 크기가 3인 커널을 사용하여 내적값을 계산하면 5x1 문장 벡터가 도출된다.
2. padding
✔ 문장 길이 보존
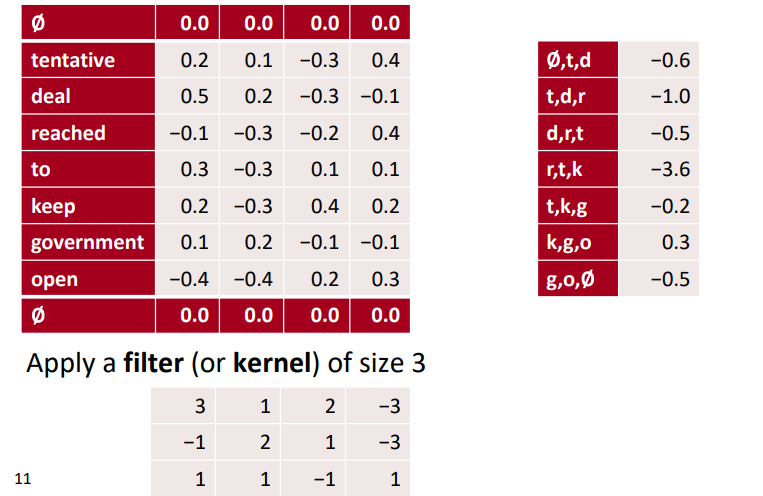
◽ sliding filter 연산을 하게되면 원래의 sequence 길이보다 작은 길이의 결과가 산출된다. 기존 sequence 길이를 보존하기 위해 padding 을 하여 filtering 을 한다.
3. multiple channel 1d Conv
✔ 문장 정보량 보존
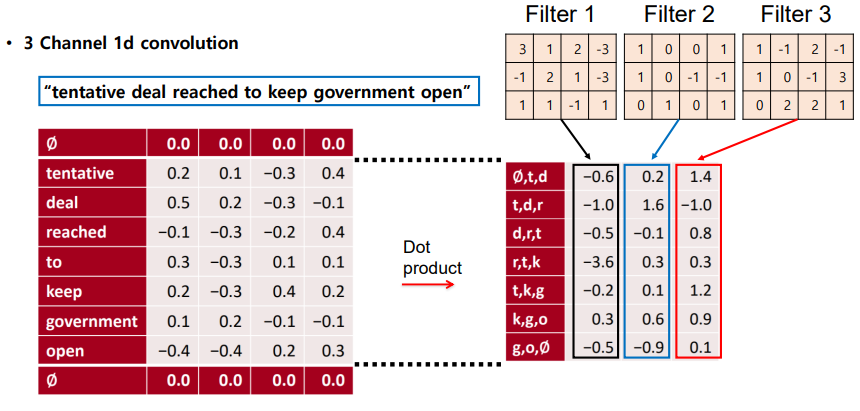
◽ 여러 개의 필터를 적용하여, 원 문장에 대해 정보를 더 많이 추출한다. (outuput 차원 증가)
◽ 또한 필터의 크기를 조정하여 n-gram 의 다양한 feature 를 만들 수 있다 (word window size) 👉 다양하고 많은 filter 를 사용하여 output 차원을 늘리고, feature 를 많이 사용할수록 기존 문장에 대한 정보량이 커진다.
4. pooling
특징을 요약하는 역할
✔ Max pooling
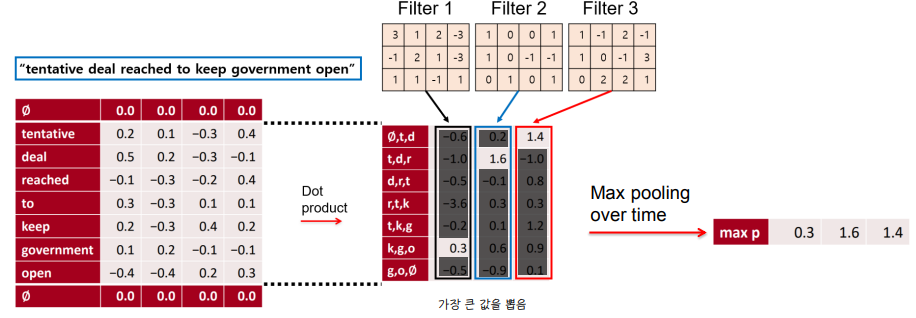

💨 NLP 에서는 max pooling 을 선호한다. 정보가 모든 토큰에 골고루 있는 것이 아니라 sparse 하게 있는 경우가 많기 때문!
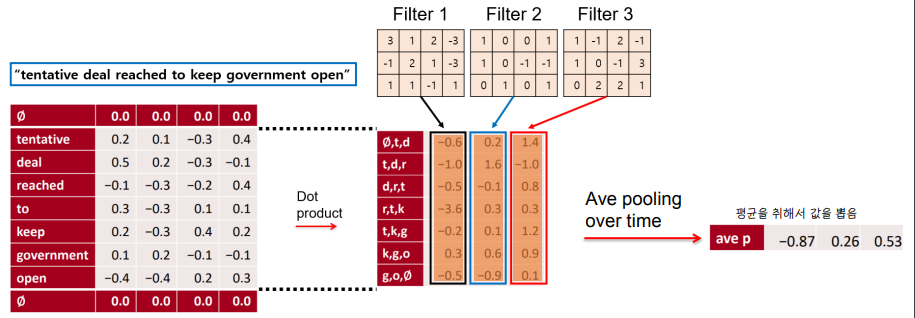
✔ average pooling
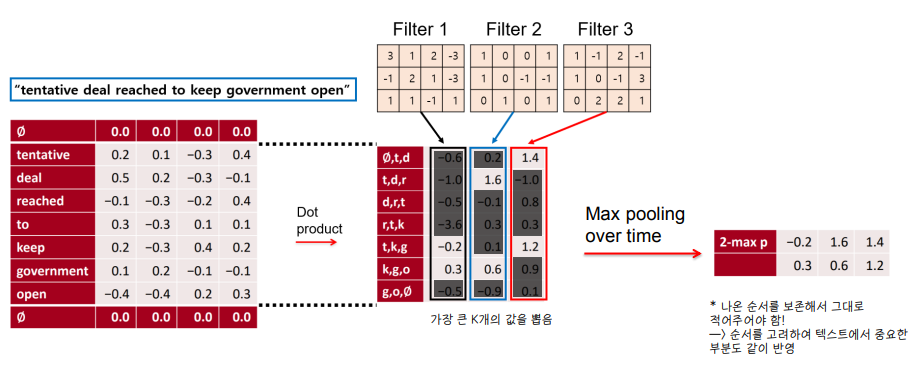
✔ K-max pooling , k=2 인 경우
5. PLUS
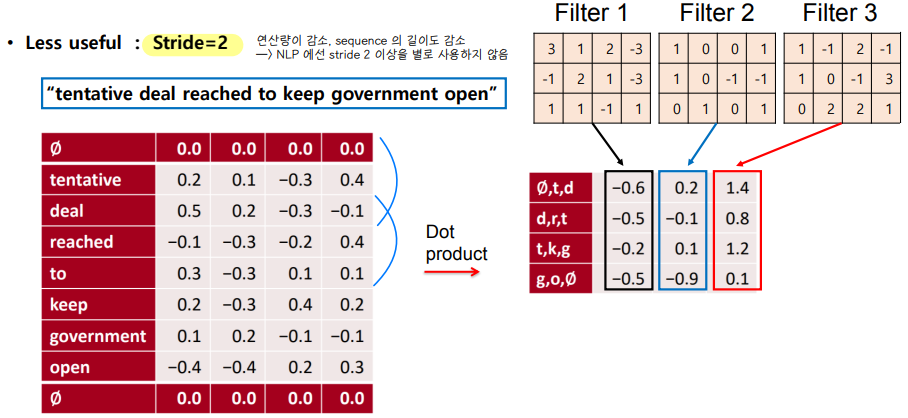
✔ stride
◽ 건너뛰는 칸의 크기
◽ NLP 에서는 sequence 길이의 감소로 stride 2 이상을 많이 사용하진 않는다.
◽ stride 2 → 2칸씩 뛰어건너 합성곱 연산
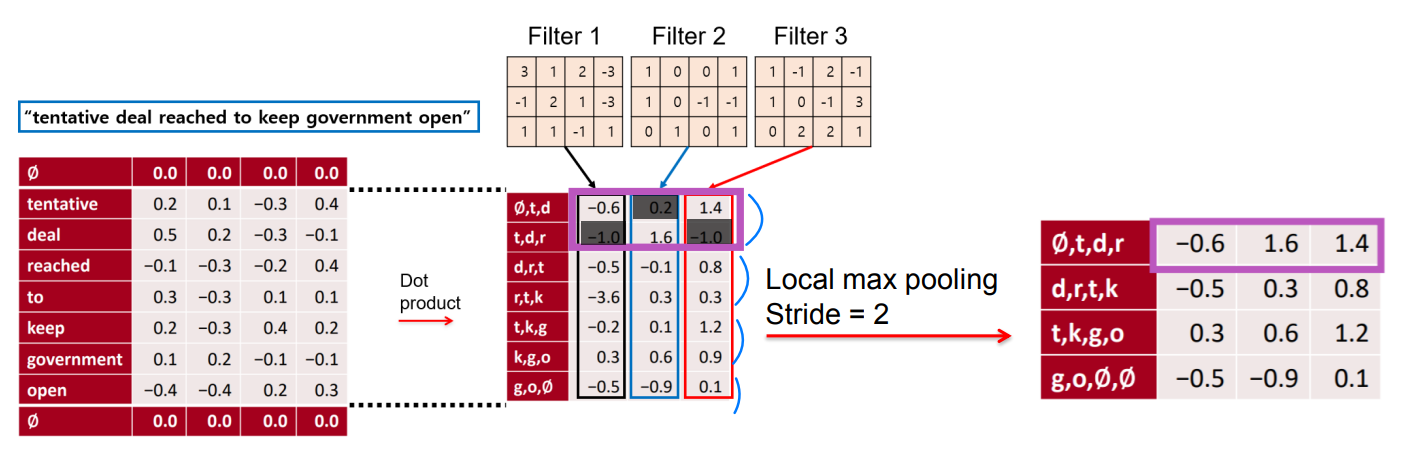
✔ local max pooling
◽ local max pooling
✔ dilation
◽ Dilated Conv
: 넓은 범위를 적은 파라미터를 통해 합성곱 연산을 진행한다. 적은 파라미터로 더 넓은 범위를 볼 수 있게 함
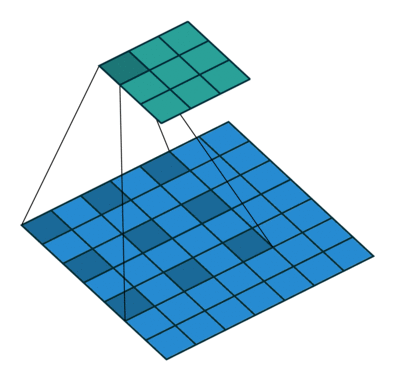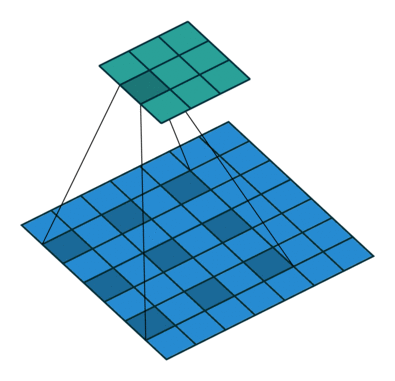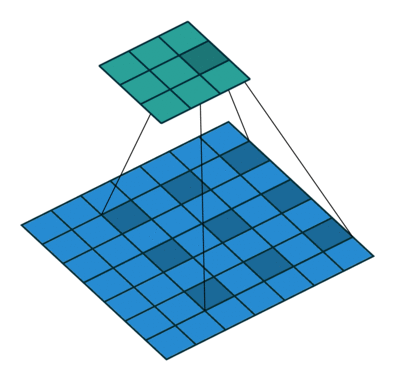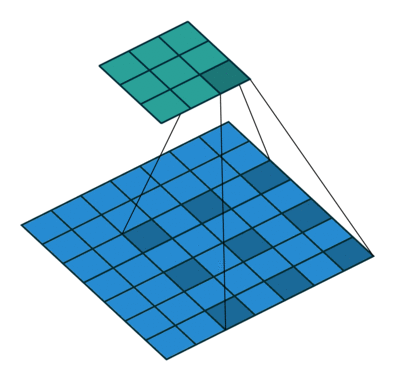
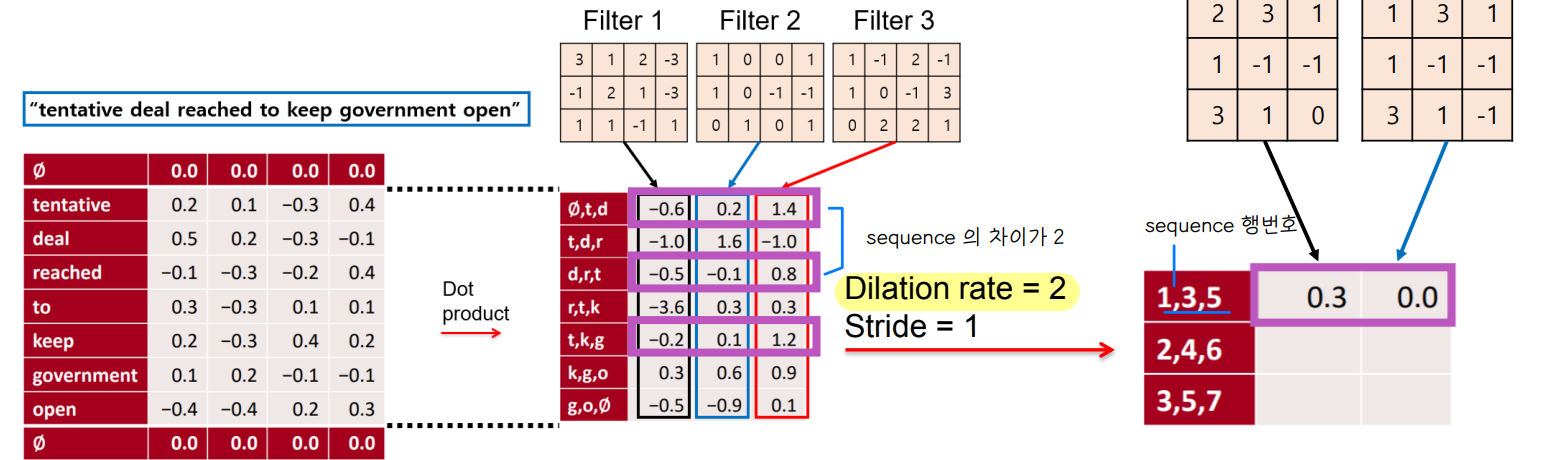
◽ Dilation rate : filter 사이의 간격을 뜻한다.
✨ 문장의 의미 더 많이 이해하도록 훈련하는 방법
1. Filter 의 크기 증가시키기
2. Dilated Conv 로 한 번에 보는 범위 늘리기
3. CNN depth 증가
3️⃣ CNN for sentence Classification
✨ Goal : Sentence classification

1. Toolkits
✔ Gated Units
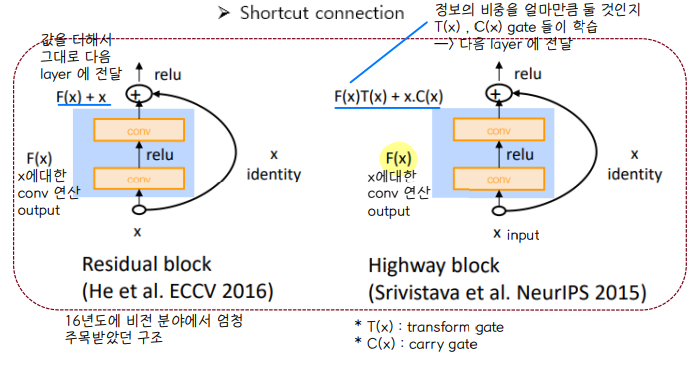
◽ LSTM, GRU 에도 적용된 아이디어
✔ 1x1 Conv

◽ kernel size = 1
◽ 적은 파라미터로 channel 을 축소하므로 훨씬 효율적
✔ Batch Normalization
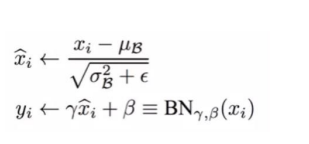
◽ Batch 단위로 정규화 (평균0, 분산1) : 특정 batch 에서의 convolution output 을 mean=0, unit variance 로 rescale
◽ 파라미터 초기화에 덜 민감해지며, 학습률에 대한 Tuning 이 쉬워지고, 모델의 성능 결과의 향상을 가져온다.
2. Yoon Kim (2014) : Convolution Neural Networks for Sentence Classification
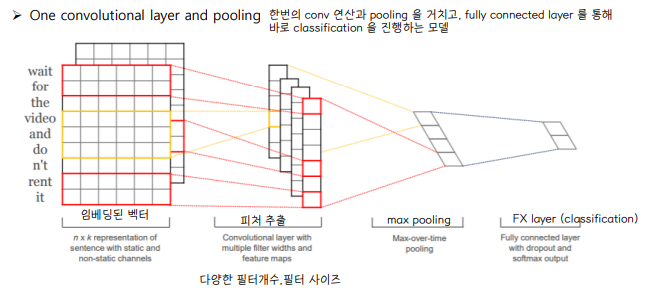
✔ One Conv layer and pooling
◽ 행렬 연산이 아닌, 단어 벡터들을 concat 하여 연산하는 방식을 취한다.
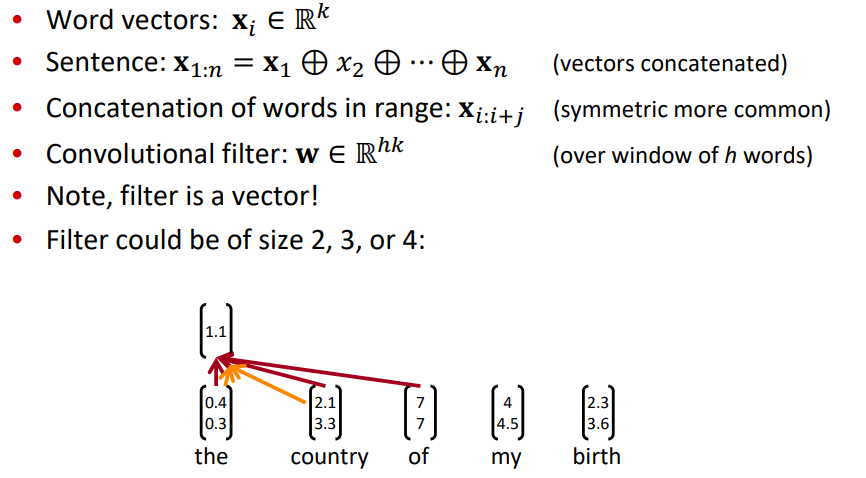
◽ Word vector : k-dimension 으로 임베딩된 사전 훈련된 단어벡터
◽ Sentence : word vectors concatenated
◽ Conv filter : W, over window of h words
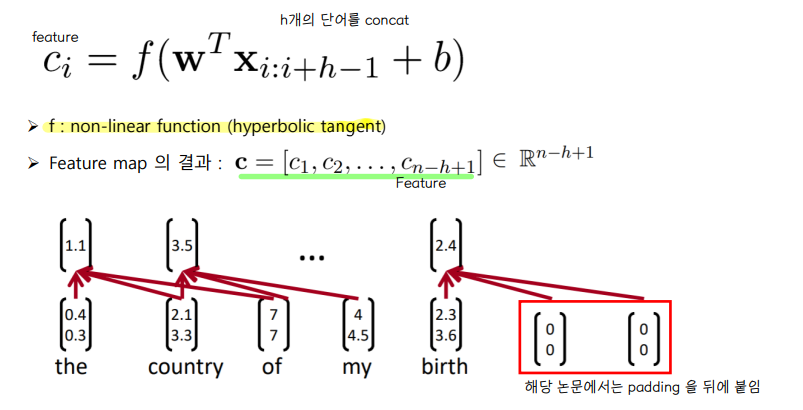
◽ n 개의 단어, h 크기의 window
◽ 한 채널에 대한 연산의 결과 : Ci

◽ feature map C 를 Max pooling 하여 각 채널마다 하나의 값을 얻는다. (특징추출) max pooling 을 하면 filter weight 와 window size, 문장 길이의 변화에 강해진다. (가장 중요한 activation 을 찾아냄)
◽ filter size = 2,3,4 인 filter 를 feature map 으로 각 100개씩 사용하였다.

◽ input 으로 워드 임베딩으로 임베딩 된 벡터를 입력할 때, 기존의 pre-trained word vector 로 초기화 시켰고, fine-tuning 을 한 것 (static)과 안한 것 (non-static) 을 둘 다 사용한다.
◽ CNN 을 통과한 후 pooling 한 최종 벡터 z 를 소프트맥스를 통해 최종 분류를 수행한다.

3. Alexis Conneau (2017) : VD-CNN
NLP 모델도 CNN처럼 깊은 구조로 만들 수 있어!
✔ Deep models
◽ 텍스트 분류를 컴퓨터 비전 구조로 실험한 논문
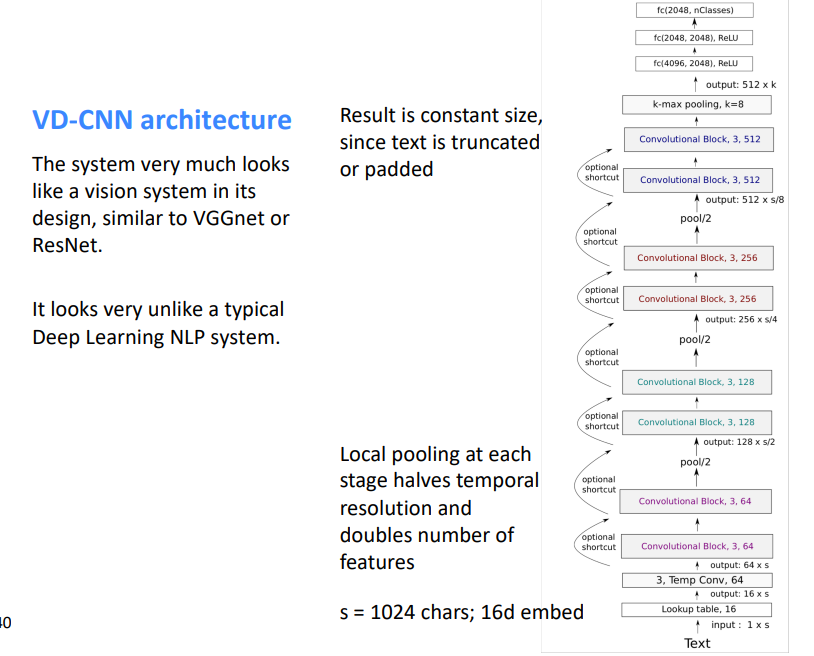
◽ Character 단위로 input 을 받음
◽ NLP 에서 RNN, Attention 등의 모델의 layer 가 deep 하지 않음 👉 VGG-Net 처럼 deep 하게 쌓아보자!
◽ Model from the character level 글자 단위로 임베딩을 진행한다.
◾ s = 1024 characters, 16 임베딩
◾ Text size 는 padding 이나 절단을 통해 텍스트 길이를 동일하게 한다.
◾ Local pooling 으로 문장길이 축소, channel 수를 2배로 하여 feature 는 두 배로 증가시킴

◽ Convolution block
◾ 2개의 Conv layer
◾ Batch Norm, ReLU 적용
◾ 필터 크기 = 3 , padding 적용하여 input 길이 고정
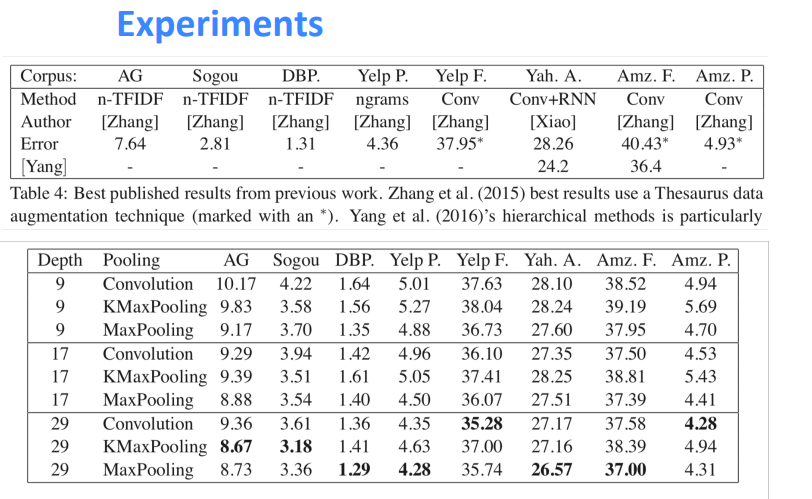
👉 다양한 데이터셋에 대해 층이 깊어질수록 성능이 개선된 점을 도출, 그러나 pooling 방법에 따라 성능은 데이터셋마다 차이가 존재함을 밝힘
✨ CNN for NLP
1. feature 를 포착하는 순서 : tokens → multi-word → expressions → phrases → sentence
2. 구현이 잘 되어있고 사용하기 편리하다.
3. 첫번째 단어와 마지막 단어를 잘 포착하기 위해 많은 Conv layer 가 필요하다.
4. 전체를 보는 RN (relation network) 와 local 하게 포착하는 CNN 의 장점을 합쳐 나온것이 Self Attention 이다.
4️⃣ Quasi-Recurrent Nueral Network
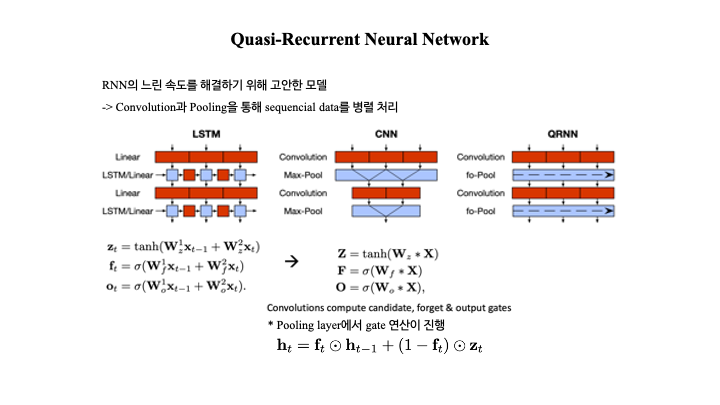

◾ CNN 과 RNN 을 결합한 모델로, 두 모델의 장점만을 가져와 Conv 와 Pooling 을 통해 sequencial data 를 병렬적으로 처리한다. 감정분류를 진행했을 때, LSTM 과 비슷한 성능을 보이지만 3배 빠른 속도를 보였다고 한다!
5️⃣ CNN for NLP 에 관한 다른 연구/실험
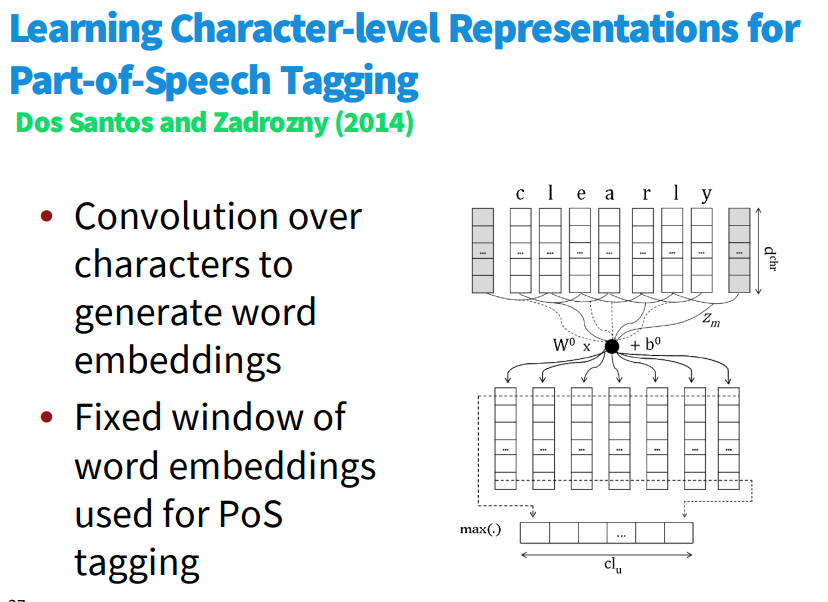
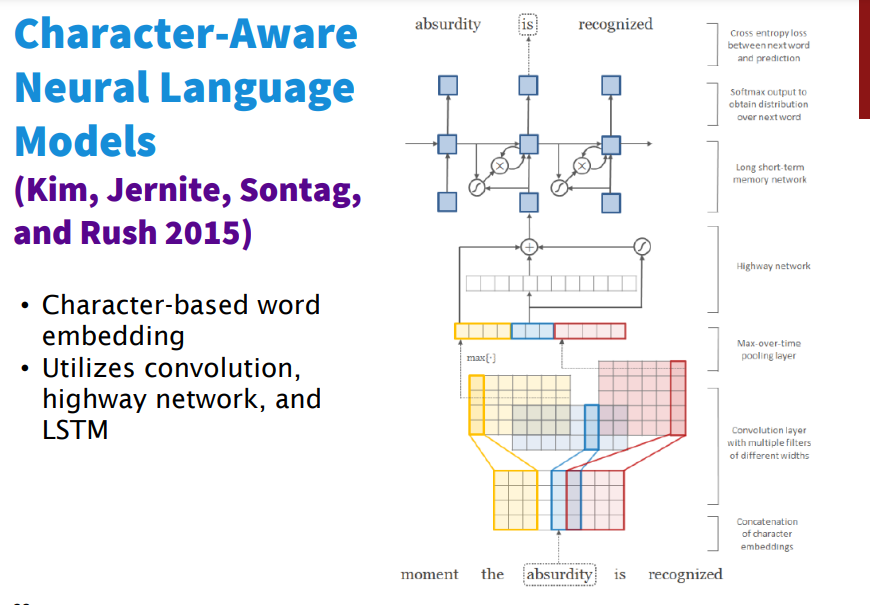
'1️⃣ AI•DS > 📗 NLP' 카테고리의 다른 글
| Glove 실습 (0) | 2022.05.31 |
|---|---|
| [cs224n] 12강 내용정리 (1) | 2022.05.23 |
| 텍스트 분석 ② (0) | 2022.05.17 |
| 텍스트 분석 ① (0) | 2022.05.14 |
| [cs224n] 10강 내용 정리 (0) | 2022.05.13 |




댓글