📌 파이썬 머신러닝 완벽가이드 공부 내용 정리
📌 실습 코드
https://colab.research.google.com/drive/1aMlFfX927tDFnPUisw2M3tB6NwGy5c7q?usp=sharing
08. 텍스트 분석(2).ipynb
Colaboratory notebook
colab.research.google.com
1️⃣ 문서 군집화
💡 문서 군집화
✔ 개념
- 비슷한 텍스트 구성의 문서를 군집화 하는 것
- 텍스트 분류 기반의 문서 분류는 사전에 target category 값이 필요하지만, 이 없이도 비지도 학습 기반으로 동작 가능하다.
1. 텍스트 토큰화 & 벡터화
2. 군집화 알고리즘 적용 : Kmeans
3. cluster_centers_ 로 군집별 핵심 단어 추출하기
✔ 실습 - 상품/서비스 리뷰 데이터 카테고리별 군집화
# 📌 데이터 프레임 만들기
document_df = pd.DataFrame({'filename' : filename_list, 'opinion_text' : opinion_text})
# 📌 토큰화 함수 만들기
from nltk.stem import WordNetLemmatizer
import nltk
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
lemmar = WordNetLemmatizer()
def LemTokens(tokens):
return [lemmar.lemmatize(token) for token in tokens]
def LemNormalize(text):
return LemTokens(nltk.word_tokenize(text.lower().translate(remove_punct_dict)))
#📌 피처 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer(tokenizer = LemNormalize, stop_words = 'english', ngram_range=(1,2), min_df = 0.05, max_df = 0.85)
feature_vect = tfidf_vect.fit_transform(document_df['opinion_text'])
# 📌 K-means clustering : (자동차-전자제품-호텔)
from sklearn.cluster import KMeans
km_cluster = KMeans(n_clusters=5, max_iter = 10000, random_state=0)
km_cluster.fit(feature_vect) # ✨
cluster_label = km_cluster.labels_
cluster_centers = km_cluster.cluster_centers_
document_df['cluster_label'] = cluster_label
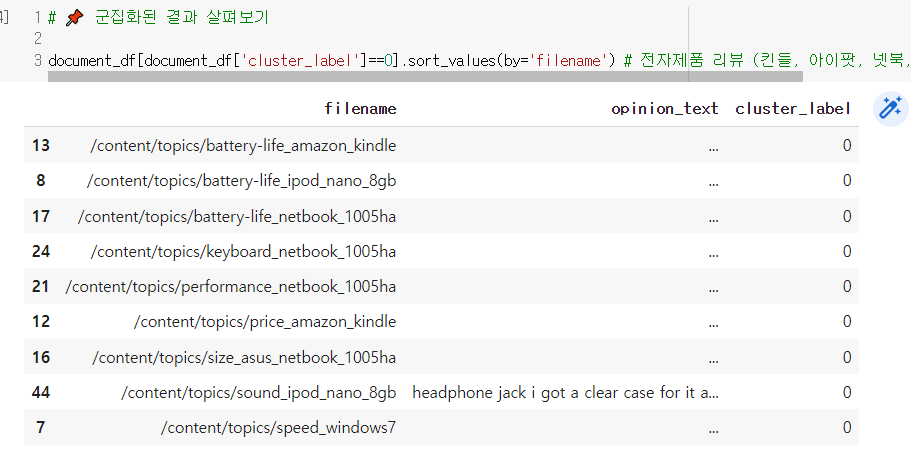
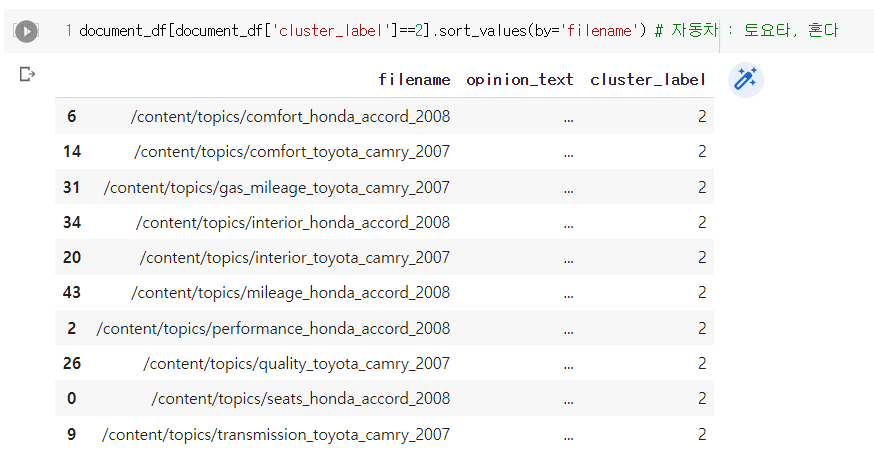
# 📌 군집별 핵심 단어 추출하기
cluster_centers = km_cluster.cluster_centers_ #⭐
print('cluster_centers shape :',cluster_centers.shape)
print(cluster_centers)
# 행 : 개별 군집 --> 3개의 군집
# 열 : 개별 피처 --> 4611개의 word feature
# 값 : 0~1 사이의 값으로 1에 가까울수록 중심과 가까운 값을 의미한다.
cluster_centers shape : (3, 4611)
[[0. 0.00099499 0.00174637 ... 0. 0.00183397 0.00144581]
[0.01005322 0. 0. ... 0.00706287 0. 0. ]
[0. 0.00092551 0. ... 0. 0. 0. ]]
💨 cluster_model.cluster_centers_.argsort()[:,::-1] → array 값이 큰 순서대로 정렬된 index 값을 반환

2️⃣ 문서 유사도
👀 개요
💡 코사인 유사도
✔ 코사인 유사도 cosθ
- 벡터의 크기보다는 벡터의 상호 방향성이 얼마나 유사한지에 기반한다 👉 두 벡터 사이의 사잇각을 구해서 얼마나 유사한지 수치로 적용한다.
- 90◦ 이하 : 유사 벡터들
- 90◦ : 관련성이 없는 벡터들
- 90~180◦ : 반대 관계인 벡터들
✔ 코사인 유사도가 문서 유사도로 자주 사용되는 이유
- 문서를 피처벡터화한 행렬은 희소행렬일 경우가 높은데, 희소행렬 기반의 문서와 문서 벡터 간의 '크기' 에 기반한 유사도 지표 (유클리드 거리 기반) 는 정확도가 떨어지기 쉽다.
- 문서의 길이가 긴 경우에는 빈도수(크기) 에 기반한 비교가 어렵다. 가령 세 문장으로 구성된 B 문서에 한글이라는 단어가 3번 등장했고, 30개 문장으로 구성된 A 문서에 한글이라는 단어가 5번 등장했을 때, B 문서가 한글과 더 밀접하게 관련된 문서라 판단할 수 있다.
✔ 사이킷런 모듈
|
from sklearn.metrics.pairwise import cosine_similarity
|
- 희소행렬, 밀집행렬 모두 가능
- 행렬 또는 배열 모두 가능
from sklearn.feature_extraction.text import TfidfVectorizer
doc_list = ['if you take the blue pill, the story ends' ,
'if you take the red pill, you stay in Wonderland',
'if you take the red pill, I show you how deep the rabbit hole goes']
tfidf_vect_simple = TfidfVectorizer()
feature_vect_simple = tfidf_vect_simple.fit_transform(doc_list)
print(feature_vect_simple.shape)
(3,18)
# 3개 문장, 18개의 (중복없는) 단어 벡터
from sklearn.metrics.pairwise import cosine_similarity
#📌 first parameter : 비교 기준이 되는 문서의 피처행렬
#📌 second parameter : 비교되는 문서의 피처행렬
# 첫번째 문서 기준으로 나머지 문서와 유사도 계산해보기
pair = cosine_similarity(feature_vect_simple[0], feature_vect_simple)
print(pair)
[[1. 0.40207758 0.40425045]]
# 전체 문서에 대해 유사도 구해보기
sim_cos = cosine_similarity(feature_vect_simple, feature_vect_simple)
print(sim_cos)
print(sim_cos.shape)
[[1. 0.40207758 0.40425045]
[0.40207758 1. 0.45647296]
[0.40425045 0.45647296 1. ]]
(3, 3)
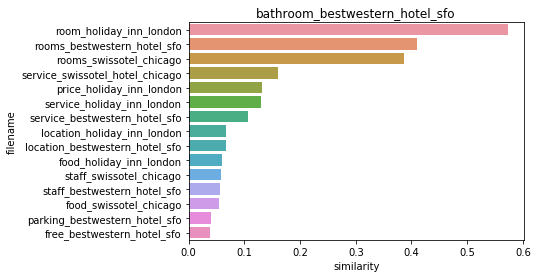
👀 문서 유사도 결과 시각화 예시 - Opinion review data
3️⃣ 한글 텍스트 처리
📌 네이버 영화 평점 데이터 기반 감성분석
💡 한글 NLP 처리의 어려움
✔ 띄어쓰기
- 영어의 경우 띄어쓰기를 잘못하면 없는/잘못된 단어로 인식된다.
- 그러나 한국어는 띄어쓰기에 따라 의미가 달라지는 경우가 존재한다.
- ex. 아버지 가방에 들어가신다, 아버지가 방에 들어가신다
✔ 다양한 조사
- 워낙 경우의 수가 많기 때문에 어근 추출 등의 전처리 시 제거하기가 어렵다.
- 라틴어 계열의 언어보다 NLP 처리가 어렵다.
💡 KoNLPy
✔ 대표적인 한글 형태소 패키지
- 형태소 분석 : 말뭉치를 형태소 (단어로서 의미를 가지는 최소 단위) 어근 단위로 쪼개고 각 형태소에 품사 태깅 (POS tagging) 을 부착하는 작업을 지칭한다.
- Kkma, Hannanum, Komoran, Mecab, Twitter 형태소 분석 모듈을 사용할 수 있다.
💡 실습

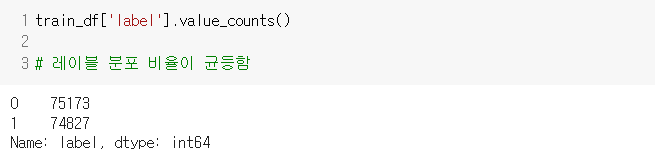
🏃♀️ 감정 레이블 분포 확인
🏃♀️ 텍스트 전처리
# 널값은 공백으로 변환
import re
train_df = train_df.fillna(' ')
# 문서에 숫자는 공백으로 변환 : \d 는 정규표현식으로 숫자를 의미
train_df['document'] = train_df['document'].apply(lambda x : re.sub(r'\d+', " ", x))
# test set 에도 동일하게 적용하기
test_df = pd.read_csv('ratings_test.txt', sep='\t')
test_df = test_df.fillna(' ')
test_df['document'] = test_df['document'].apply( lambda x : re.sub(r"\d+", " ", x) )
🏃♀️ 토큰화 + TfidfVectorizer
# 📌 한글 형태소 분석을 통해 형태소 단어로 토큰화하기
# ✨ SNS 분석에 적합한 Twitter class
from konlpy.tag import Okt
okt = Okt()
def tw_tokenizer(text) :
tokens_ko = okt.morphs(text) # 토큰화
return tokens_ko
# 📌 텍스트 벡터화
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# ⭐ 위에서 정의한 토큰화를 Tfidf tokenizer 인자로 넘기기
## 수행시간 10분 이상 소요함
tfidf_vect = TfidfVectorizer(tokenizer = tw_tokenizer, ngram_range =(1,2), min_df = 3, max_df = 0.9)
tfidf_vect.fit(train_df['document'])
tfidf_matrix_train = tfidf_vect.transform(train_df['document'])
🏃♀️ 로지스틱 회귀 훈련 : GridSearchCV
# 📌 로지스틱 회귀 감성 분석 분류 수행 : GridSearchCV
lg_clf = LogisticRegression(random_state=0)
params = {
'C' : [1,3.5,4.5,5.5,10]
}
grid_cv = GridSearchCV(lg_clf, param_grid = params, cv = 3, scoring='accuracy', verbose=1)
grid_cv.fit(tfidf_matrix_train, train_df['label'])
print(grid_cv.best_params_, round(grid_cv.best_score_,4))
# C = 3.5일 때 최적
🏃♀️ test data set 예측 수행
# 📌 테스트 세트로 최종 감성 분석 예측 수행하기
from sklearn.metrics import accuracy_score
tfidf_matrix_test = tfidf_vect.transform(test_df['document'])
best_estimator = grid_cv.best_estimator_ # ⭐⭐
preds = best_estimator.predict(tfidf_matrix_test) # ⭐⭐
print('로지스틱 회귀 정확도 : ', accuracy_score(test_df['label'], preds))
# 0.86172
4️⃣ 실습
👀 대형 온라인 쇼핑몰 Mercari 제품 가격 예측
💡 대회 목표, 데이터셋 소개
✔ 제품에 대한 여러 속성 및 제품 설명 등의 텍스트 데이터 👉 제품 예상 가격을 판매자들에게 제공
| train_id | 데이터 id |
| name | 제품명 - text |
| item_condition_id | 판매자가 제공하는 제품상태 (텍스트 범주) |
| category_name | 카테고리 명 - text |
| brand_name | 브랜드 이름 -text |
| price | 제품 가격, 예측을 위한 타깃 속성에 해당 |
| shipping | 배송비 무료 여부 (1이면 무료로 판매자가 지불, 0이면 구매자 지불) |
| item_description | 제품에 대한 설명 -text |
👉 텍스트 + 정형 (범주형) 데이터를 적용해 회귀분석을 수행
💡 분석 흐름
1️⃣ 전처리
🏃♀️ 칼럼별 데이터 유형/널값 확인
s.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1482535 entries, 0 to 1482534
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 train_id 1482535 non-null int64
1 name 1482535 non-null object
2 item_condition_id 1482535 non-null int64
3 category_name 1476208 non-null object
4 brand_name 849853 non-null object
5 price 1482535 non-null float64
6 shipping 1482535 non-null int64
7 item_description 1482531 non-null object
dtypes: float64(1), int64(3), object(4)
memory usage: 90.5+ MB
💨 brand_name 은 상품 브랜드 이름으로 가격에 영향을 미치는 주요 요인으로 판단되나, 널값이 너무 많다.
💨 category_name, item_descriptoin 도 널값이 존재함
🏃♀️ target 분포 확인
# price 값 분포 살펴보기
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
y_train_df = s['price']
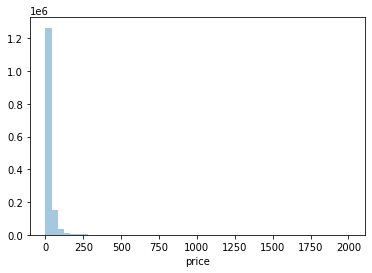
plt.figure(figsize=(6,4))
sns.distplot(y_train_df, kde = False) # 가격이 낮은 데이터가 많음 👉 로그변환 뒤 다시 살펴보기
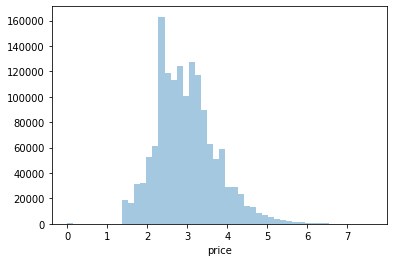
import numpy as np
y_train_df = np.log1p(y_train_df)
sns.distplot(y_train_df, kde=False)
# 로그변환 뒤, 값이 비교적 정규분포에 가까운 데이터를 이루게 됨 👉 원래 데이터에도 로그 변환을 적용하기
s['price'] = np.log1p(s['price'])
🏃♀️ 칼럼별로 자세히 살펴보기 - int64 타입인 shipping 칼럼과 item_condition_id 칼럼
print('shipping 값 유형 \n', s.shipping.value_counts()) # 분포가 비교적 균일
print('item_condition_id 값 유형', s.item_condition_id.value_counts()) # 판매자가 제공하는 제품 상태로, 자세히 각 값의 의미를 알 수 없으나, 1,2,3 값이 위주로 이루어짐
shipping 값 유형
0 819435
1 663100
Name: shipping, dtype: int64
item_condition_id 값 유형 1 640549
3 432161
2 375479
4 31962
5 2384
Name: item_condition_id, dtype: int64
🏃♀️ 칼럼별로 자세히 살펴보기 - object 타입인 item_description 칼럼 살펴보기
# 제품 설명 칼럼은 Null 값이 별로 없긴 하지만, 별도 설명이 없는 경우 'No description yet' 으로 되어있다 👉 얼마나 많은지 살펴보기
boolean_cond = s['item_description'] == 'No description yet'
s[boolean_cond]['item_description'].count() # 82489건 : 의미있는 속성값으로 사용될 수 없음 👉 적절한 값으로의 변경이 필요
🏃♀️ 칼럼별로 자세히 살펴보기 - object 타입인 categort_name 칼럼 살펴보기
# category_name 칼럼 살펴보기
# Men/Top/T-shirts 처럼
# / 로 분리된 카테고리를 하나의 문자열로 나타내고 있다 👉 단어를 토큰화 하여 별도의 피처로 저장하기
def split_cat(category_name) :
try:
return category_name.split('/')
except :
return ['Other_Null', 'Other_Null', 'Other_Null'] # Null 일 경우 반환값
# 대분류/중분류/소분류
s['cat_dae'], s['cat_jung'], s['cat_so'] = zip(*s['category_name'].apply(lambda x : split_cat(x)))
# ✨ zip 과 * 를 사용하면, 생성된 리스트의 각 요소를 여러 개의 칼럼으로 간단하게 값을 분리할 수 있다.
print('대분류 유형 : \n', s['cat_dae'].value_counts())
print('중분류 개수 :', s['cat_jung'].nunique())
print('소분류 개수 :', s['cat_so'].nunique())
대분류 유형 :
Women 664385
Beauty 207828
Kids 171689
Electronics 122690
Men 93680
Home 67871
Vintage & Collectibles 46530
Other 45351
Handmade 30842
Sports & Outdoors 25342
Other_Null 6327
Name: cat_dae, dtype: int64
중분류 개수 : 114
소분류 개수 : 871
🏃♀️ 널값 채워넣기
# brand_name, category_name, itme_desription 칼럼의 Null 값은 Other Null 로 채우기
s.brand_name = s.brand_name.fillna(value='Other_Null')
s.category_name = s.category_name.fillna(value='Other_Null')
s.item_description = s.item_description.fillna(value='Other_Null')
2️⃣ 피처 인코딩 , 피처 벡터화
◾ 선형 회귀의 경우 원 핫 인코딩 적용이 훨씬 선호된다 👉 인코딩할 피처는 모두 원핫인코딩 적용하기
◾ 피처벡터화는 짧은 텍스트의 경우 Count 기반의 벡터화, 긴 텍스트는 TF-IDF 기반의 벡터화를 적용
1️⃣ brand_name 상품의 브랜드명 : 4810 개의 유형이나, 비교적 명료한 문자열로 되어 있으므로 별도의 피처 벡터화 없이 인코딩 변환을 적용하기
2️⃣ name 상품명 : 거의 개별적인 고유한 상품명을 가지고 있음 , 적은 단어 위주의 텍스트 형태 👉 Count 기반 피처 벡터화 변환 적용하기
3️⃣ category_name : 대중소 분류 세 개의 칼럼으로 분리되었는데, 각 칼럼별로 원핫인코딩 적용하기
4️⃣ shipping , item_condition_id 두 칼럼 모두 유형값의 경우가 2개, 5개로 적으므로 원핫인코딩 수행
5️⃣ item_description : 평균 문자열 크기가 145로 비교적 크므로 Tfidf 벡터화하기
🏃♀️ 피처 벡터화
cnt_vect = CountVectorizer()
X_name = cnt_vect.fit_transform(s.name)
tfidf = TfidfVectorizer(max_features = 50000, ngram_range = (1,3), stop_words = 'english')
X_descp = tfidf.fit_transform(s.item_description)
print(X_name.shape) # 희소행렬 : (1482535, 105757)
print(X_descp.shape) # 희소행렬 : (1482535, 50000)
🏃♀️ 피처 인코딩 : LabelBinarizer 원핫인코딩을 이용해 희소행렬 형태의 원핫인코딩 도출
# 📌 모든 인코딩 대상 칼럼은 LabelBinarizer 를 이용해 희소행렬 형태의 원핫인코딩으로 변환하기 : sparse_output = True
from sklearn.preprocessing import LabelBinarizer
# brand_name, item_condition_id, shipping 피처들을 희소행렬 원핫인코딩으로 변환
lb_brand_name = LabelBinarizer(sparse_output = True)
X_band = lb_brand_name.fit_transform(s.brand_name)
lb_item_cond_id = LabelBinarizer(sparse_output = True)
X_item_cond_id = lb_item_cond_id.fit_transform(s.item_condition_id)
lb_shipping = LabelBinarizer(sparse_output = True)
X_shipping = lb_shipping.fit_transform(s.shipping)
# 대중소 피처들을 희소행렬 원핫인코딩으로 변환
lb_cat_dae = LabelBinarizer(sparse_output = True)
X_cat_dae = lb_cat_dae.fit_transform(s.cat_dae)
lb_cat_so = LabelBinarizer(sparse_output = True)
X_cat_so = lb_cat_so.fit_transform(s.cat_so)
lb_cat_jung = LabelBinarizer(sparse_output = True)
X_cat_jung = lb_cat_jung.fit_transform(s.cat_jung)
print(type(X_band)) # csr_matrix 타입
print('X_brand shape : ', X_band.shape) # 인코딩 칼럼이 무려 4810 개 이지만, 피처 벡터화로 텍스트 형태의 문자열이 가지는 벡터 형태의 매우 많은 칼럼과 함께 결합되므로 크게 문제될 것은 없음
<class 'scipy.sparse.csr.csr_matrix'>
X_brand shape : (1482535, 4810)
X_name + X_descp + (원핫인코딩 피처들을 희소 행렬로 변환 후 피처 벡터화된 희소 행렬들) 결합하기! 👉 hstack()
🏃♀️ 하나의 feature 행렬 X 도출하기
from scipy.sparse import hstack
import gc
sparse_matrix_list = (X_name, X_descp, X_band, X_item_cond_id, X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
X_features_sparse = hstack(sparse_matrix_list).tocsr()
print(type(X_features_sparse), X_features_sparse.shape)
<class 'scipy.sparse.csr.csr_matrix'> (1482535, 161569)
3️⃣ 회귀 모델링
평가지표 : RMSLE
def rmsle(y , y_pred):
# underflow, overflow를 막기 위해 log가 아닌 log1p로 rmsle 계산
return np.sqrt(np.mean(np.power(np.log1p(y) - np.log1p(y_pred), 2)))
def evaluate_org_price(y_test , preds):
# 원본 데이터는 log1p로 변환되었으므로 exmpm1으로 원복 필요.
preds_exmpm = np.expm1(preds)
y_test_exmpm = np.expm1(y_test)
# rmsle로 RMSLE 값 추출
rmsle_result = rmsle(y_test_exmpm, preds_exmpm)
return rmsle_result
import gc
from scipy.sparse import hstack
def model_train_predict(model,matrix_list):
# scipy.sparse 모듈의 hstack 을 이용하여 sparse matrix 결합
X= hstack(matrix_list).tocsr() #⭐
X_train, X_test, y_train, y_test=train_test_split(X, s['price'],
test_size=0.2, random_state=156)
# 모델 학습 및 예측
model.fit(X_train , y_train)
preds = model.predict(X_test)
del X , X_train , X_test , y_train
gc.collect()
return preds , y_test
🏃♀️ 릿지회귀
linear_model = Ridge(solver = "lsqr", fit_intercept=False)
sparse_matrix_list = (X_name, X_band, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
linear_preds , y_test = model_train_predict(model=linear_model ,matrix_list=sparse_matrix_list)
print('Item Description을 제외했을 때 rmsle 값:', evaluate_org_price(y_test , linear_preds))
sparse_matrix_list = (X_descp, X_name, X_band, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
linear_preds , y_test = model_train_predict(model=linear_model , matrix_list=sparse_matrix_list)
print('Item Description을 포함한 rmsle 값:', evaluate_org_price(y_test ,linear_preds))
Item Description을 제외했을 때 rmsle 값: 0.5023727038010544
Item Description을 포함한 rmsle 값: 0.4712195143433641
⭐ 포함했을 때 rmsle 값이 많이 감소 👉 영향이 중요함
- (수행시간이 길어서 패스했지만) LightGBM 의 rmsle 는 0.455, 두 모델을 앙상블( lgbm 결과값에 0.45를 곱하고 선형모델엔 0.55를 곱함) 하여 구한 결과는 0.450으로 도출
'1️⃣ AI•DS > 📗 NLP' 카테고리의 다른 글
| [cs224n] 12강 내용정리 (2) | 2022.05.23 |
|---|---|
| [cs224n] 11강 내용 정리 (1) | 2022.05.19 |
| 텍스트 분석 ① (0) | 2022.05.14 |
| [cs224n] 10강 내용 정리 (0) | 2022.05.13 |
| [cs224n] 9강 내용 정리 (0) | 2022.05.09 |




댓글