📌 교내 융합소프트웨어프로젝트 수업에서 진행한 개인 데이터 분석 프로젝트에 대한 시리즈 글 입니다.
📌 https://aifactory.space/competition/detail/2052 를 공부한 내용을 정리하였습니다.
시계열 데이터 이상징후 감지 딥러닝 모델 입문+실전+해커톤 무료 온라인 세미나
aifactory.space
* 정리된 내용에 활용된 모든 이미지는 해당 강의 영상에 나와있는 이미지 입니다. 문제가 될 시 게시물을 삭제조치하도록 하겠습니다.
1️⃣ 통신사의 AI 기술 및 해커톤 소개
📌 통신산업 + AI
💨 네트워크 구조 : 유선망, 무선망
💨 네트워크 구축과 운용은 어떻게 이루어지는가 → 가전제품 구매방식과 유사하다
- 설계 , 구축, 구성, 관리의 4단계 과정으로 정의된다.
- 기존에는 운용자의 노하우와 수작업에 의존해서 운용했으나, 현재는 AI+SDN 기반의 네트워크 운용 업무로 전환되었다. SW 기반의 자동화/지능화 된 네트워크 체계로 DX 화
💨 AI 기술은 과연 네트워크 감시/관리 관점에서 네비게이션 같은 존재였을까?
- AI가 없어도 네트워크는 관리되어 왔고, 여전히 운용자가 필요하다.
- 네트워크에서 발생되는 경보, 성능, Log 정보들을 중앙에서 감시 : NMS/EMS 중심의 네트워크 관리
💨 네트워크 분야 AI 에 대한 현장 니즈

- 실 장애/고장 이벤트만 알면 Good, 장애를 차단할 수 있다면 Best
- 네트워크 AI 를 통해 '장애원인 분석 + 이상탐지'
💨 KT 무선망을 위한 네트워크 AI 적용 사례
- LTE/5G 망을 위한 이상탐지 솔루션
- 코어망 시그널에 대한 성능 데이터 수집 Dr.Core 무선
- 수집된 Time Windows 내 CDR 데이터에 대해 LSTM AutoEncoder 딥러닝을 통한 정상 패턴 복원
- 복원된 패턴값(예측)과 실측값의 Distance 를 통한 정상/비정상 분류


💨 통신은 일상에 가까이 있지만 영상이나 이미지 분야 대비 데이터나 오픈소스를 구하기 어려워 커뮤니티가 잘 활성화 되어있진 않다.
2️⃣ 네트워크 데이터에서의 시계열 이상탐지 모델
📌 시계열 데이터

💨 추세성+주기성 = 시계열 데이터
◽ 시계열 데이터에서 추세성을 제외하면 주기성을 살펴볼 수 있다.

◽ 추세성 : 데이터의 장기적 변동을 뜻함. 선형추세 말고도 지수적 추세도 있다.
◽ 순환성 : 주기를 가지지만 일정하지 않고 반복이 없는 데이터의 변동
◽ 계절성 : 일정한 주기를 가지고 반복되는 데이터 변동
◽ 불규칙성 : 알 수 없거나 돌발적인 요인에 의해 발생하는 데이터 변동
👉 시계열 데이터의 추세성과 주기성(계절성)을 중심으로 '통신 사업자 관점' 에서 살펴보자
📌 시계열 데이터 전처리
💨 회귀모델용 학습 데이터 생성 : 이전 시점의 값들을 통해 다음 시점의 '값' 을 예측한다.
◽ 예지보전 측면에서 회귀모델이 분류모델보다 적합하다.
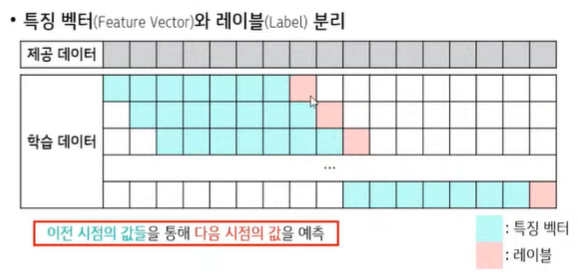
◽ 데이터의 특징에 따라 최적의 윈도우 크기는 모두 다르다.
💨 분석 모델용 학습 데이터 생성 : 이전 시점의 값들을 통해 다음 시점의 '상태' 를 예측
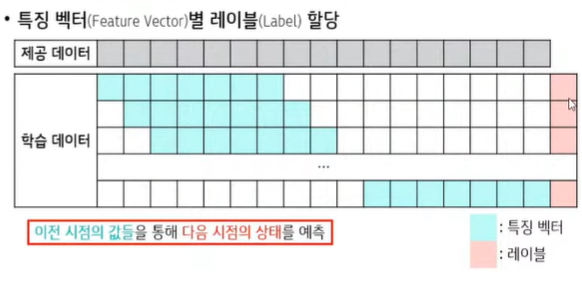
📌 이상탐지 모델 구현
💨 이상과 정상의 기준 정의
◽ 통신 사업자 데이터는 이상 발생 빈도가 매우 낮아, 충분한 수의 데이터 확보가 어려움
◽ 이상탐지가 아닌 "이상 징후" 탐지, 즉 예지보전 Predictive Maintenance 이 필요함
◽ 궁극적으로 사전에 이상발생을 예측해 발생 자체를 막는 것이 중요하다.
◽ '이상' 정의 기준 : 손실 값이 임계치 초과 시 이상이라 간주 👉 (실측치-예측치) 차이값 Loss
💨 이상과 정상의 기준 정의 - 예지보전 측면에서
🤔 실측치가 예측치보다 낮을 때도 이상인가요
◽ 특정 장비의 트래픽 저하는 다른 장비의 트래픽 증가로 이어질 수 있으므로 이상이라 간주함 (다중화, 부하분산)
🤔 임계치를 결정하는 방법은
◽ 시간 흐름에 따른 손실 값의 분포 변화를 반영하여 동적으로 정의한다 👉 동적 임계치
📌 이상탐지 모델 평가
💨 평균과 정확도의 함정
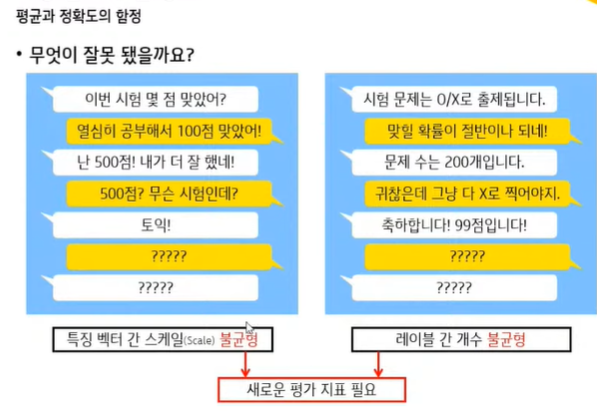
💨 정확도를 대체할 새로운 평가지표 : 혼동행렬

◽ 정확도 뿐만 아니라 정밀도, 재현율, F1 score, F-beta score 지표를 사용
◽ 통신사업자의 시계열 네트워크 데이터 이상 탐지 모델에서는 F2 score 를 사용하는 경우가 많다.
3️⃣ 비지도 학습 기반 시계열 이상탐지 기법
📌 Anomlay or Fault
💨 Fault detection
- 고장 여부 또는 품질의 좋고 나쁨을 판별
- Fault 의 빈도는 일반적으로 낮음
- 낮은 품질의 빈도는 높을 수도 있음
- 도메인 지식에 대한 의존성이 높음
◽ 판별 방법 : Model-based 모델이 비정상적으로 작동할 경우, Data-based 데이터 분포를 통해 확인, Knowledge-based 전문가가 판별
◽ Fault type
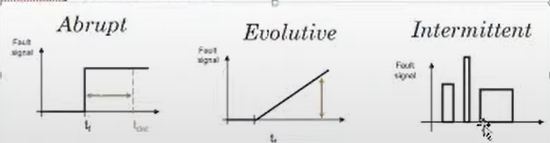
💨 Anomaly detection
- 데이터 분포상의 이상치 판별
- 낮은 빈도
- Novelty detection
- Outlier detection
- Domain Knowledge 에 대한 의존성이 낮음
- Fault Detection 의 대안
◽ 판별방법
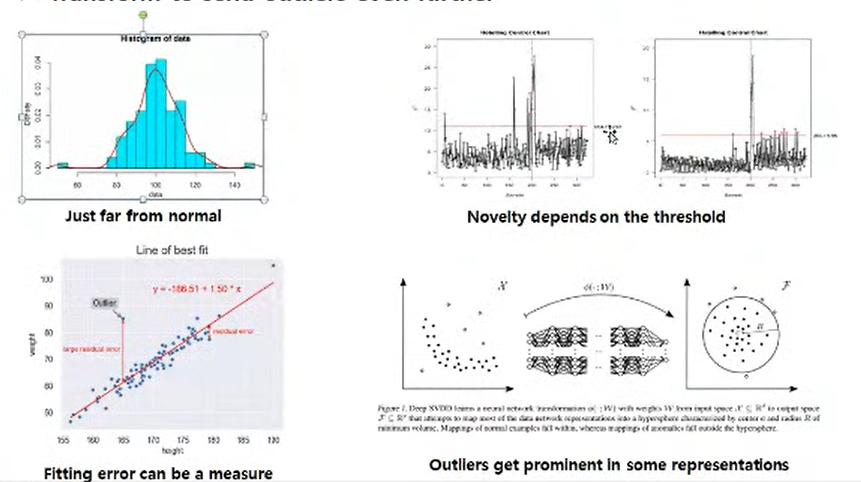
1. 분포에서 벗어난 수치
2. threshold 를 정하는 방법 👉 fitting 한 모델을 기준으로 멀리 떨어진 것
3. fitting 을 하기 어려우면 중심으로부터 멀리 떨어져있는 개념을 도입
📌 Types of Anomaly Detection
💨 Supervised AD
- 정상치와 이상치 데이터가 존재하고 각각의 레이블이 있음
- EX. HMG, the World's first AI-Based Diagnotics for Fault Detection
💨 Unsupervised AD
- 정상치와 이상치 데이터가 섞여있으나 레이블이 없음
- 훈련 데이터에서 출변 빈도가 낮으면 비정상으로 판단
⭐ Auto Encoder : 비지도 학습의 대표적인 모델
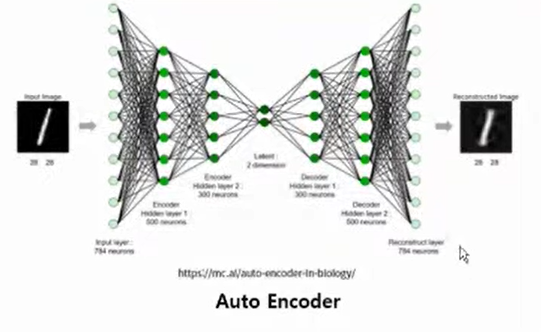
- 레이어를 거칠수록 unit 의 개수가 줄어들다가 다시 늘어남
- 원데이터와 출력 데이터가 최대한 같아지도록 훈련
- 중간에 있는 unit 에 원데이터에 대한 특성이 나타나게 됨
- 만약 발견하지 못한 데이터가 들어오면 그 데이터를 잘 복원하지 못하게 됨 👉 입력과 출력 사이의 차이가 커짐 : 훈련 셋에서 본 적 없는 데이터로 간주 : outlier, anomaly 라고 판단
◽ AutoEncoder : Reconstruction Error = degree of Anomaly
💨 Semi-Supervised AD
- 정상치와 이상치 데이터가 섞여있으므로 일부 데이터의 레이블이 존재
- 표준적인 방법론이 정립되지 않음
4️⃣ 가상화폐 데이터에서의 시계열 이상 탐지 모델
📌 암호화폐 데이터에서 이상탐지를 하는 이유
◽ Trading : 비싸게 팔고싶어서
◽ BI : 거래패턴 등을 파악해 비즈니스 인사이트를 창출
◽ 사기거래탐색
📌 암호화폐 데이터에서 이상탐지 해보기
① 기본적인 통계(정규분포) 를 이용한 이상탐지 해보기
◽ anomaly data : 평균에서 벗어난, 즉 평소와 다른 데이터 포인트를 의미한다.
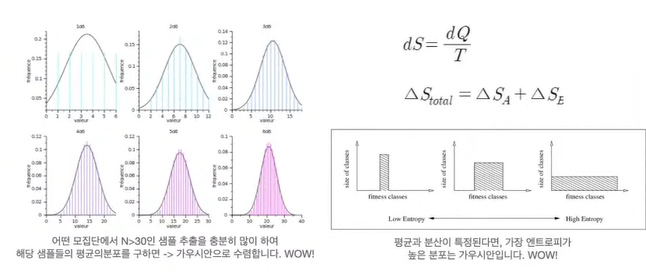
◽ 잘 모르겠을 땐 일단 Gaussian 분포를 사용하자 👉 굉장히 많은 데이터들을 설명하는데 가우시안 분포가 사용된다.
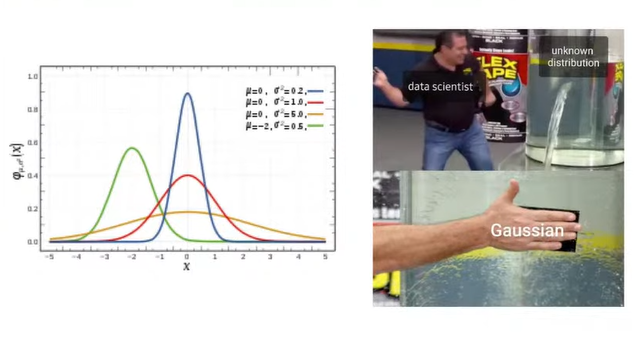
◽ 왜 가우시안으로 가정할까? - 중심극한 정리와 Maximum Entropy Theorm
◽ 비트코인 거래 데이터에 정규분포 적용해보기
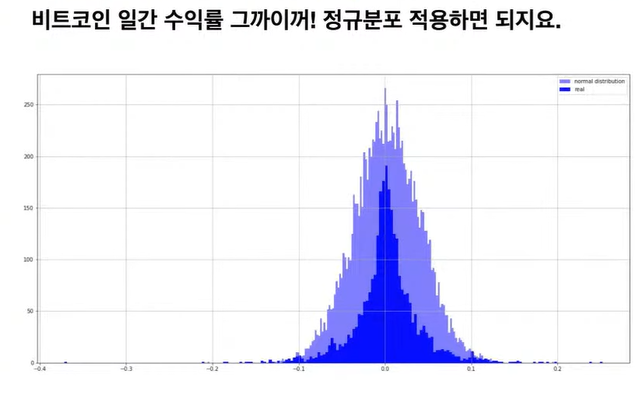
◽ 이상치 탐지해보기
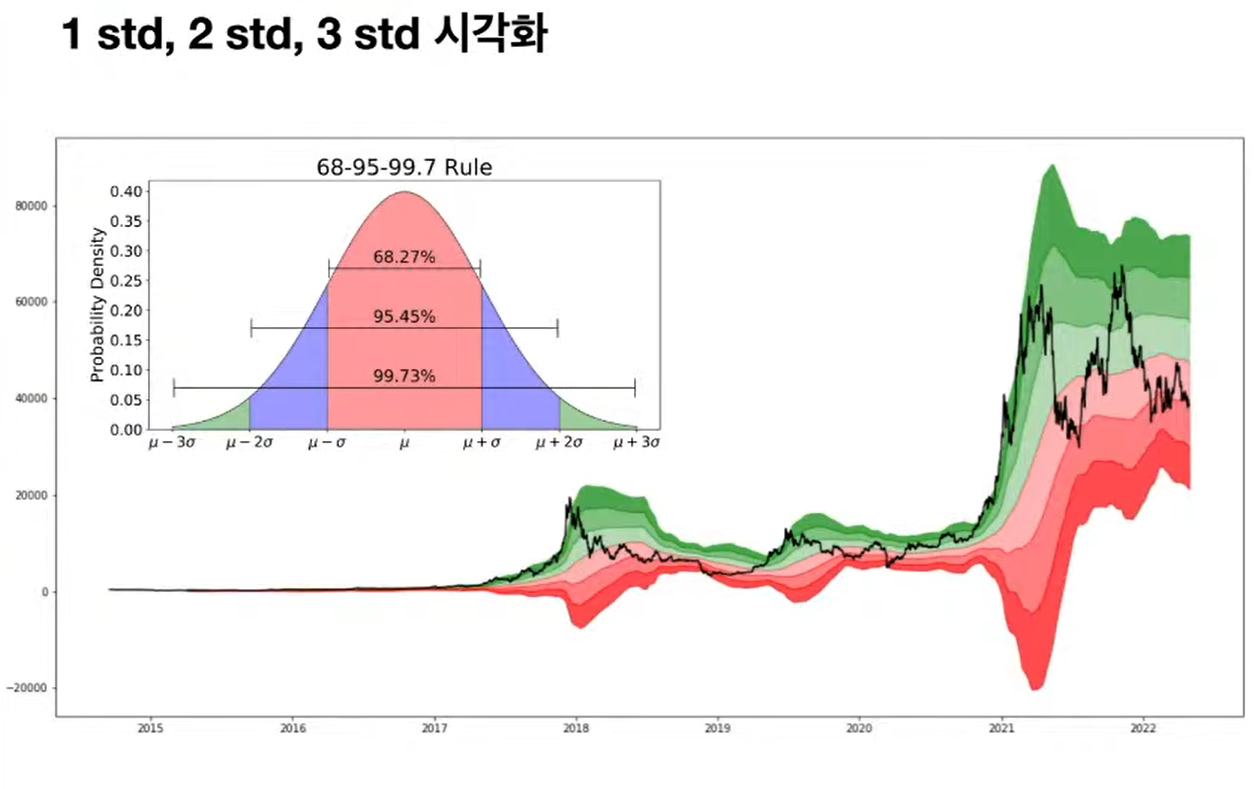
- 전체 데이터 포인트의 5% 밖에 없는 거래 데이터는 이상치로 간주해볼 수 있음
- 상승추세나 하락추세가 발생하는 구간에서 2δ 를 넘어가는 이상치 포인트들을 확인해볼 수 있음
- 주식수익률이 정규분포라고 가정하고 시각화한 지표
② 시계열 모델 Prophet 을 이용한 이상탐지 해보기
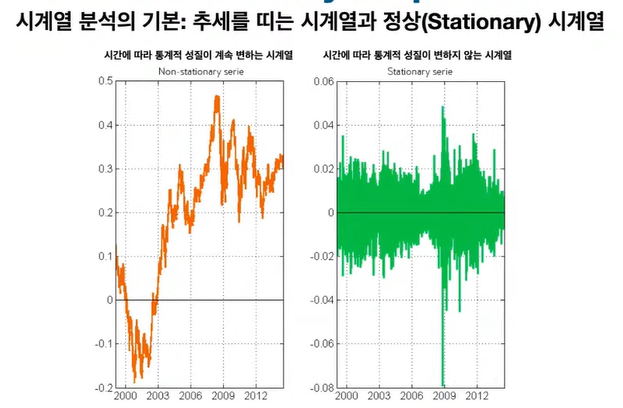
◽ 추세를 띄는 시계열은 시간에 따라 통계적 성질이 계속 변하기 때문에 시계열 분석을 하는 의미가 없다.
◽ 시계열 분석은 기본적으로 과거 데이터들을 가지고 예측, 신뢰구간 생성 등을 하는 것인데, 과거 데이터의 통계적 성질이 현재 데이터의 통계적 성질이 많이 다르다면, 분석에 의미가 없다.
💨 가장 널리 사용되고 오래된 시계열 모델 : Autogressive Model
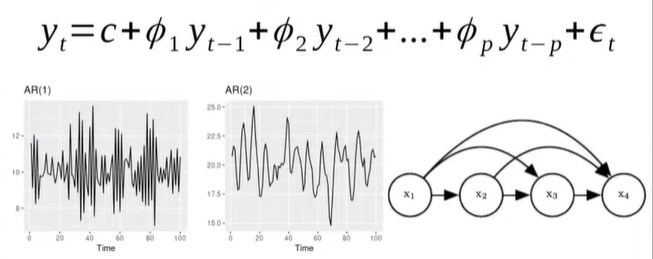
💨 Prophet : 페이스북의 현대적인 시계열 예측 모델
◽ 비즈니스 예측에 적합한 모델
◽ 일간 계절성, 주간 계절성, 연간 계절성을 고려하는 파라미터가 존재 → 계절성이나 추세패턴을 어느정도 가지고 갈 수 있는 모델이다.
◽ 비정상 시계열 형태도 분석할 수 있는 모델 (비즈니스 모델 - 아이스크림은 여름에 잘팔린다 → seasonality)

◽ 도메인 지식을 가진 사람들이 빠르게 전처리 없이 접근할 수 있는 패키지
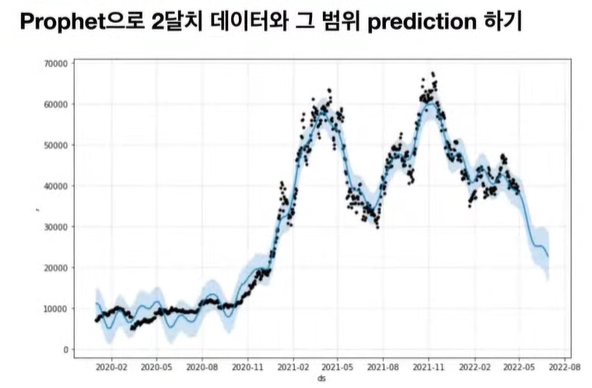
import prophet
import pandas as pd
model = prophet.Prophet(daily_seasonality = True, weekly_seasonality = True)
model.fit(data)
prediction = model.predict(model.make_future_dataframe(preiods=N))
- normalize, scaling 도 내부적으로 장착되어 있음
- EDA 과정에서 가볍게 돌려보기 좋은 모델
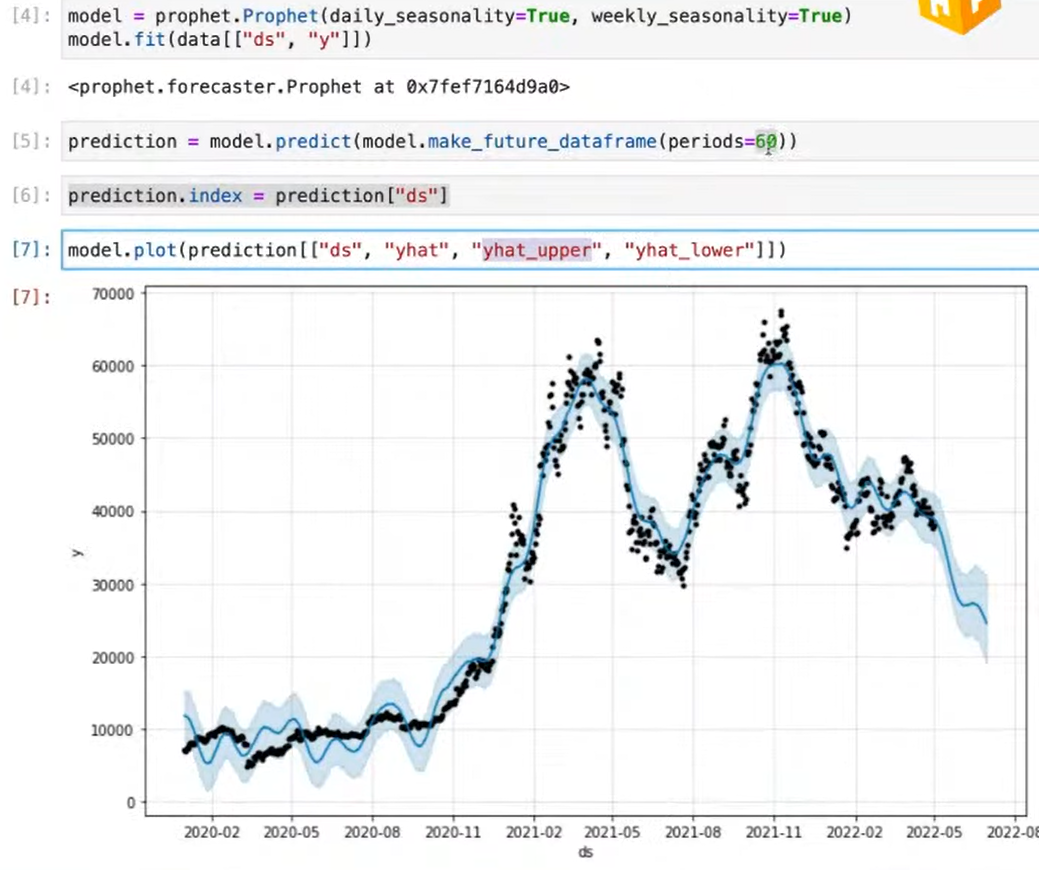
- ds : 일간 가격 데이터 포인트
- yhat : 예측결과
- yhat_upper, yhat_lower : 신뢰구간 👉 periods 설정하여 그 기간만큼 예측하게 되는데, periods 값이 클수록 신뢰구간도 넓어짐
👀 데이터분석을 할 때 중요한건, 데이터로부터 무엇을 모르는지, acuuracy 를 얼마나 믿을 수 있는지를 더 중요하게 생각해야 한다.
◽ Prophet 분해하기 : 추세, 시즈널러티, 구간을 분해해서 따로 값을 시각화할 수 있다 👉 EDA 하기 좋음
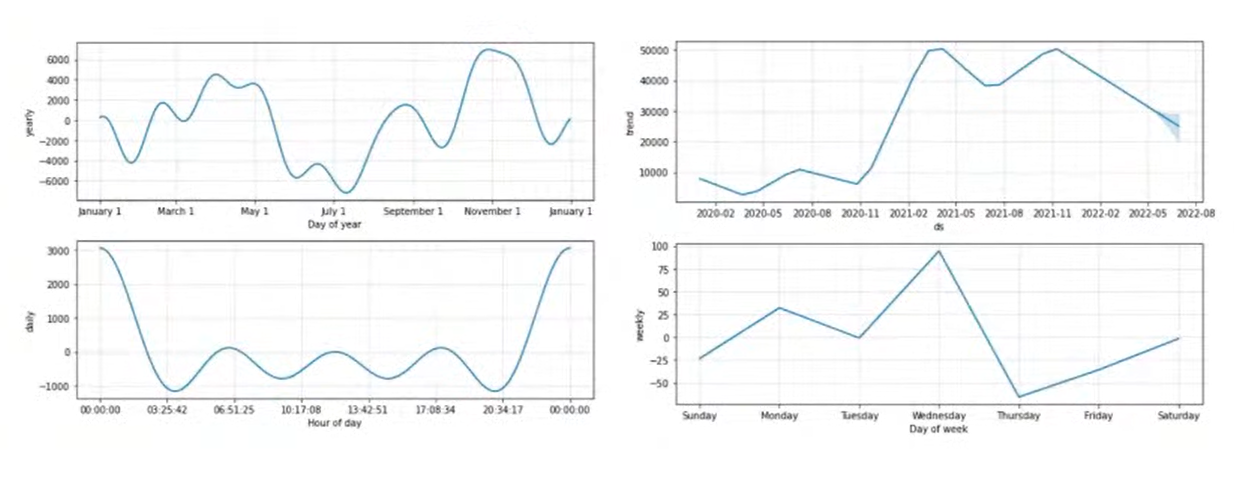
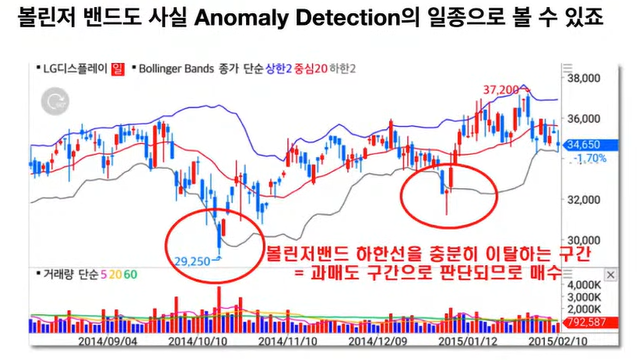
◽ 신뢰구간을 벗어나는 데이터에 대해서 그 데이터 포인트들을 이상치로 간주
📌 주식/크립토 데이터의 특성
◽ Noise 99, Info 1 , Non-Stationary (비정상 시계열 - 주기성,추세성을 많이 포함하고 있는 데이터임)
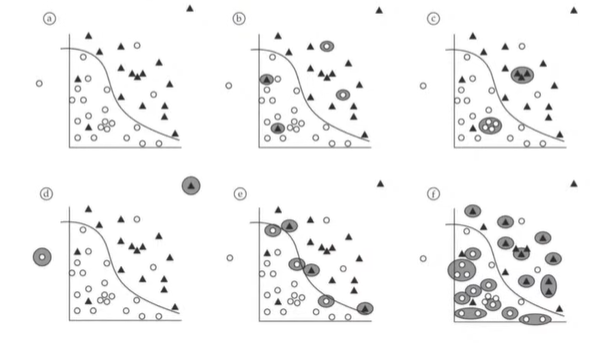
◽ 비정상 시계열엔 복잡한 통계모형은 쓸수 없는가?
5️⃣ 케라스로 시계열 이상탐지 모델 시작해보기
📌 시계열 데이터
- 순차데이터를 입력으로 한 문제 정의 : 기온, 체중, 주식, 자연어 데이터 등
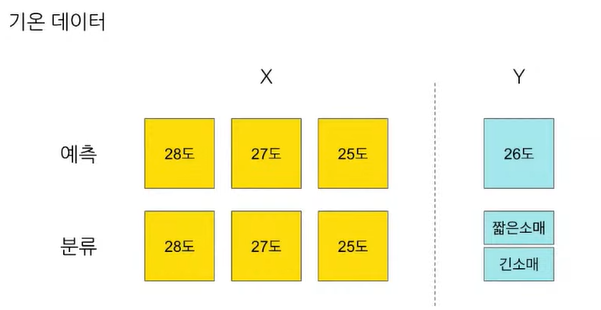
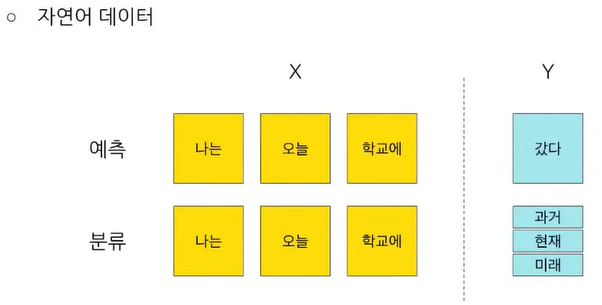
📌 시계열 데이터 task
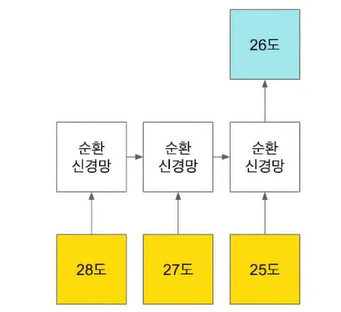
- 예측문제 : 순환 신경망
- 이상징후 탐지
1. 분류문제 - 클래스 불균형이 존재하기 때문에 적용하기 어려움
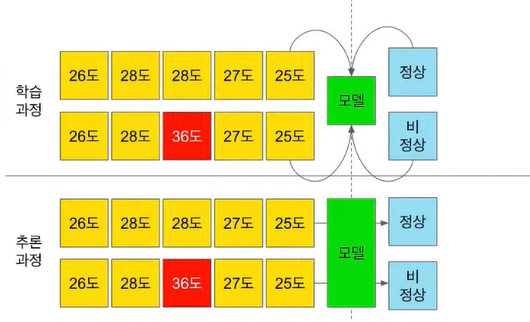
2. 분류문제 - 비지도 학습
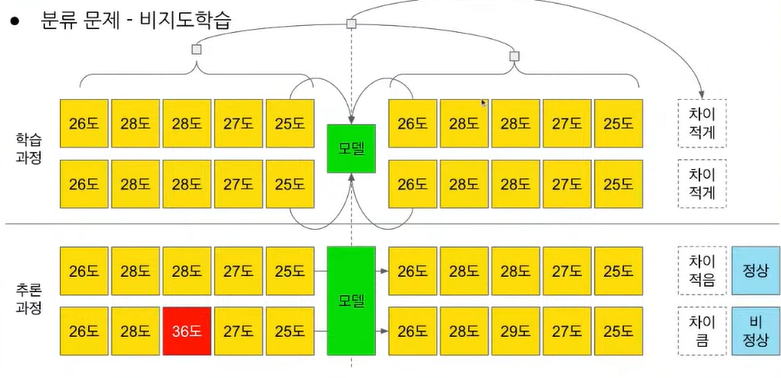
◽ Autoencoder
- 입력 시계열 특성과 출력 시계열 특성의 차이가 작아지도록 학습 (정상 데이터만 학습의 입력으로 넣어서 훈련해야함)
- 추론 과정에서 비정상 데이터를 넣으면 input 과 output 의 차이가 큼
'3️⃣ Study at Univ > ○ 노트북 필사' 카테고리의 다른 글
| [개인 프로젝트] 시계열 이상치 탐지 스터디 ③ - Prophet (0) | 2022.05.16 |
|---|---|
| [개인 프로젝트] 시계열 이상치 탐지 스터디 ① (0) | 2022.05.09 |
| Pycaret - AutoML (0) | 2022.04.13 |
| [kaggle] 2021년 여름방학 필사 스터디 파일 (0) | 2022.04.06 |
| [kaggle] 필사정리 Note_5 (0) | 2022.04.02 |



댓글