📌 교내 융합소프트웨어프로젝트 수업에서 진행한 개인 데이터 분석 프로젝트에 대한 시리즈 글 입니다.
👀 이상치 탐색 개요
01. 이상치 탐색의 개념
📌 이상치
- 통계학 측면에서 이상치는 관측치들이 주로 모여있는 곳에서 멀리 떨어져 있는 관측치로 정의됨
- 이상치 탐색은 탐색 영역에 따라 Outlier detection, Noise detection, Anomaly detection, Novelty detection, Fraud detection, Instrusion detection 등 다양한 용어로 사용된다.
📌 이상치의 구분
- 비합리적인 이상치 : 입력 오류 등 자료의 오염으로 인해 발생한 이상치
- 합리적인 이상치 : 정확하게 측정은 되었으나 다른 자료들과 전혀 다른 경향이나 특성을 보이는 이상치를 말한다.
📌 이상치 탐색의 목적
- 분석 결과의 안전성을 위한 이상치 제거, 자료의 대체 등을 위한 목적
- 중요한 (새로운) 정보 탐색을 위한 목적
- 이상패턴 감지
02. 이상치 탐색 방법의 분류


📌 단변량 자료에서의 이상치 탐색
- 이상치 영역을 정의해 이상치를 탐색하는 방법
- 정의된 이상치 영역의 포함 여부에 대한 판단
📌 다변량 자료에서의 이상치 탐색
- 연관성이 존재하는 2개 이상의 변수 정보를 활용해 관측치 사이의 거리, 밀도 등을 기반으로 이상치를 탐색
📌 시계열 자료에서의 이상치 탐색
- 단변량 자료의 이상치 탐색 방법과 유사한 개념임
👀 이상치 탐색 방법
01. 시계열 자료에서 이상치 탐색
📌 시계열 자료에서 이상치 탐색은 대부분 모형 적합을 통해 관측치 사이의 연관성을 제거한 잔차를 산출한 후 잔차에 대해 방법을 적용한다.
① 신뢰구간 이상치 탐색 z-test
- 데이터가 정규분포를 따를 때 사용가능한 신뢰구간으로 이상치 탐색
- 신뢰구간 밖에 있는 데이터는 이상치라고 판단
- t-분포 등 특정 확률분포에 피팅되면 정규분포가 아니더라도 그 확률 분포의 신뢰구간 결정 방법을 적용 가능

🏃♀️ 정규분포 판단 여부
from statsmodels.stats.weightstats import ztest
_, p = ztest(데이터)
print(p) # 0.05 이하로 나오면 정규분포와 거리가 멀다는 뜻
② Time series decomposition
- 시계열 데이터 중 정규분포에 가까운 데이터를 뽑아내는 방법
👀 stationary
- 정상성, 안정성
- 평균, 분산, 공분산이 일정한 stationary 시계열에 대해서만 미래 예측이 가능하다.
- 시계열 데이터는 stationary 하지 않고 계속 변화하는데, Stationary 한 부분과 그렇지 않은 부분으로 나누어 분석하기 위해 주로 사용하는 기법
👀 decomposition
- 시계열 데이터는 decomposition 을 통해 추세, 계절성, 잔차(residual) 성분으로 분리가 되고 그 중 Residual 성분의 데이터가 정상성에 가까운 형태를 띈다.
- 정상성에 가까운 데이터는 정규분포를 띄는데, 따라서 residual 데이터를 사용해 신뢰구간을 구할 수 있다.
🏃♀️ 단변수 사용 decomposition (주식 데이터 예시 코드 참고함)
from statsmodels.tsa.seasonal import seasonal_decompose
# period = n : 계절적 성분 가정을 위한 일수 지정
# extrapolate_trend='freq' : Trend 성분을 만들기 위한 rolling window 때문에 필연적으로 trend, resid에는 Nan 값이 발생하기 때문에, 이 NaN값을 채워주는 옵션이다.
result = seasonal_decompose(데이터, model='additive', two_sided=True,
period=n, extrapolate_trend='freq')
result.plot()
plt.show()

👉 이런식으로 원 데이터에서 Trend, Seasonal, Resid 가 분해됨
👉 잔차는 평균 0을 기준으로 분포. 만약 잔차가 크다면 이는 일반적인 추세나 계절성에서 벗어난 날로 해석
# 👀 계절 성분 확인
result.seasonal[:100].plot()

# 👀 잔차 분포 확인
fig, ax = plt.subplots(figsize=(9,6))
_ = plt.hist(result.resid, 100, density=True, alpha=0.75)
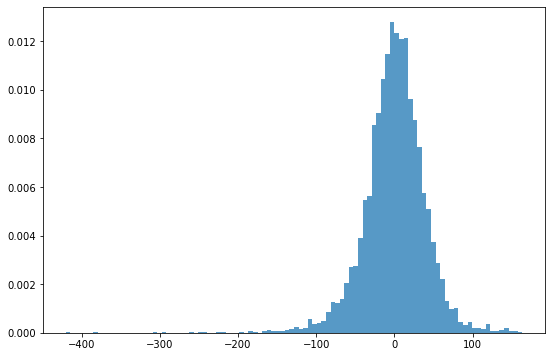
🏃♀️ 정규분포를 따르는 residual 을 기준으로 신뢰구간을 벗어나는 데이터 찾기
mu, std = result.resid.mean(), result.resid.std()
print("이상치 갯수:", len(result.resid[(result.resid>mu+3*std)|(result.resid<mu-3*std)]))
➰ 아래부터는 다변량 이상치 탐색 기법 ➰
③ Clustering : 정상 데이터끼리, 이상치 데이터끼리 그룹화
(1) Kmeans 방법
- 각 변수 데이터로 부터 추출된 residual 값들을 대상으로 Kmeans clustering 을 진행 👉 count 가 적은 그룹이 특이 그룹으로 이상치로 판단한다.
(2) DBSCAN 방법
④ Forecasing : 시계열 예측 모델을 만들어 예측 오차가 크게 발생하는 지점은 이상한 지점으로 간주한다. 일반적으로 autoencoder 로 탐색한다.
02. 딥러닝 시계열 데이터 이상탐지 : LSTM AE
📌 Autoencoder
- 입력된 데이터를 재구성 (복원) 하는 기능을 가진 알고리즘이다.
- 정상 데이터에 대한 특징을 학습하고, 학습된 모델에 데이터를 입력했을 때 재구성한 결과와 학습된 정상 특징과의 차이점을 비교하여 이상 여부를 판단

💛 시계열 이상치 탐지 파이썬 패키지 : https://github.com/yzhao062/anomaly-detection-resources#32-time-series-outlier-detection
참고자료
◽ https://velog.io/@nameunzz/Anomaly-Detection
◽ https://daewonyoon.tistory.com/289
◽ http://aispiration.com/corona/univariate-time-series.html
'3️⃣ Study at Univ > ○ 노트북 필사' 카테고리의 다른 글
| [개인 프로젝트] 시계열 이상치 탐지 스터디 ③ - Prophet (0) | 2022.05.16 |
|---|---|
| [개인 프로젝트] 시계열 이상치 탐지 스터디 ② (0) | 2022.05.11 |
| Pycaret - AutoML (0) | 2022.04.13 |
| [kaggle] 2021년 여름방학 필사 스터디 파일 (0) | 2022.04.06 |
| [kaggle] 필사정리 Note_5 (0) | 2022.04.02 |



댓글