📌 필사 노트 링크 : https://colab.research.google.com/drive/10Zt5TD76kS8rApqzHIytv2gjUG-SYuTa?usp=sharing
[kaggle] 회귀-필사.ipynb
Colaboratory notebook
colab.research.google.com
📌 캐글 노트북 링크 : https://www.kaggle.com/code/teampycaret/house-prices-prediction-using-pycaret
House Prices Prediction using PyCaret
Explore and run machine learning code with Kaggle Notebooks | Using data from House Prices - Advanced Regression Techniques
www.kaggle.com
🔹 dataset
- 미국 아이오와주의 에임스 지방의 주택가격 정보 데이터셋
✔ 분석 목적
- 주택가격에 영향을 미치는 요인 파악, 주택가격 예측
✔ 변수
- 목적 변수 : SalePrice
- 설명 변수 : 80개
- data shape : (1460, 81)
👩💻 pycaret
📌 AutoML
- 데이터 성격에 맞게 자동으로 데이터 분석 모델을 추천해주는 자동화 머신러닝 기법
- feature engineering 을 자동으로 추출, 하이퍼 파라미터 자동 탐색
- 코딩, 전처리, 모델선택, 파라미터 튜닝 작업을 자동화
- 데이터셋만 있으면 간단히 모델링부터 하이퍼 파라미터 튜닝과 feature importance 등의 작업까지 가능
👻 기반 기술 기초
- HPO (하이퍼 파라미터 최적화)
| Grid Search | GridSearchCV (sklearn) |
| Random Search | RandomizedSearchCV (sklearn) |
| Bayesian Search | Hyperopt |
- NAS (신경망 구조 탐색) : 진화 알고리즘 기반 탐색, 강화학습 기반 탐색, 경사하강법 기반 탐색
👻 AutoML 라이브러리 종류
| pycaret | https://pycaret.gitbook.io/docs/ |
| autosklearn | https://automl.github.io/auto-sklearn/master/ |
| autokeras | https://autokeras.com/tutorial/overview/ 👉 이미지, 텍스트, 정형 데이터 모두 지원 |
| FLAML | https://microsoft.github.io/FLAML/docs/getting-started |
| lightautoml | https://github.com/sberbank-ai-lab/LightAutoML |
| H20 | https://docs.h2o.ai/h2o/latest-stable/h2o-docs/automl.html#code-examples |
| autoGluon | https://auto.gluon.ai/stable/index.html 👉 이미지, 텍스트, 정형 데이터 모두 지원 |
| MLJAR | https://mljar.com/ 👉 표 형식의 데이터를 위한 autoML |
| AutoX | https://www.kaggle.com/code/poteman/autox-welcome-to-star-and-fork/notebook |
👀 참고 (위의 표 이외의 다양한 프레임워크가 존재)
- https://www.kaggle.com/code/rohanrao/automl-tutorial-tps-august-2021/notebook
- https://dbrang.tistory.com/1533
📌 pycaret
- 기존에 있던 사이킷런, XGBoost, LightGBM, spaCy 등 여러가지 머신러닝 라이브러리를 ML high-Level API 로 제작한 라이브러리이다.
- 분류, 회귀, 클러스터링, 이상탐지, 시계열 (beta) 문제에 적용할 수 있다.
- 단 몇 줄의 코드만으로 데이터 분석 및 머신러닝 모델 성능 비교까지 가능하고 Log 를 생성해 이력을 남겨준다.
| Classification | from pycaret.classification import * |
| Regression | from pycaret.regression import * |
| Clustering | from pycaret.clustring import * |
| Anomaly Detection | from pycaret.anomaly import * |
| NLP | from pycaret.nlp import * |
| Association Rule Mining | from pycaret.arules import * |
👉 https://pycaret.readthedocs.io/en/latest/api/nlp.html : pycaret nlp
👻 pycaret 적용 순서
- library import
- Load dataset
- Setup environment
- Compare models : 다양한 모델 비교
- Create models : 사용할 모델 생성
- (Model ensemble, Voting, Stacking)
- Tune models : 모델 튜닝
- Plot models, Feature importance : 모델의 결과를 시각화
- Predict for Validation, evaluate model : 3번에서 train_size 로 지정하고 남은 데이터로 predict 예측
- Finalize for Deployment
- Prediction
- Save model, Load model, submit
◯ 기본 분석 과정
(1) Setup 데이터 준비
- 데이터를 머신러닝에 사용할 수 있도록 로드 및 전처리
from pycaret.classification import setup
a = setup(dataset, target = , train_size = , ignore_features = , session_id = ,...)
| dataset | 모델링에 사용할 데이터 지정 |
| target | 타겟값으로 사용할 피처 지정 |
| train_size | 학습에 사용할 데이터 비율 지정 |
| session_id | random_state와 같은 기능 |
| silent | True 로 설정하면 입력된 데이터의 형태에 따라서 알아서 데이터를 조정한다. |
| ignore_features | 학습에 사용하지 않을 피처 지정 |
- 전처리 파라미터는 머신러닝 기법 별로 상이하다.
👀 출력 결과 : 다양한 description 이 제공된다.
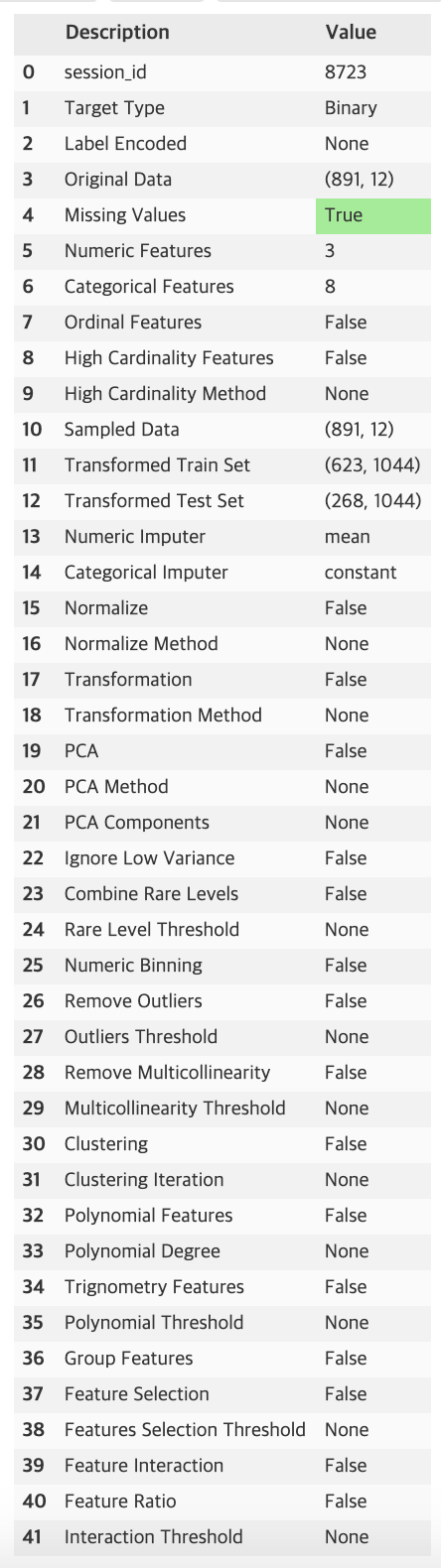
⭐ 설정한 preprocessing 파라미터에 따라 성능이 좌우됨 (필사한 노트북 참고)
(2) 모델 생성 및 비교
| 모듈 | 내용 |
| model( ) | 머신러닝 기법에 따라 구현된 모델들을 나열해준다. |
| compare_models( ) | Setup 된 데이터를 각각 ML 모델에 적용 후 비교한다. |
| create_model( ) | model( ) 에 기입한 ML 모델을 선택해서 생성한다. |
👀 지원하는 ML 파라미터 이름
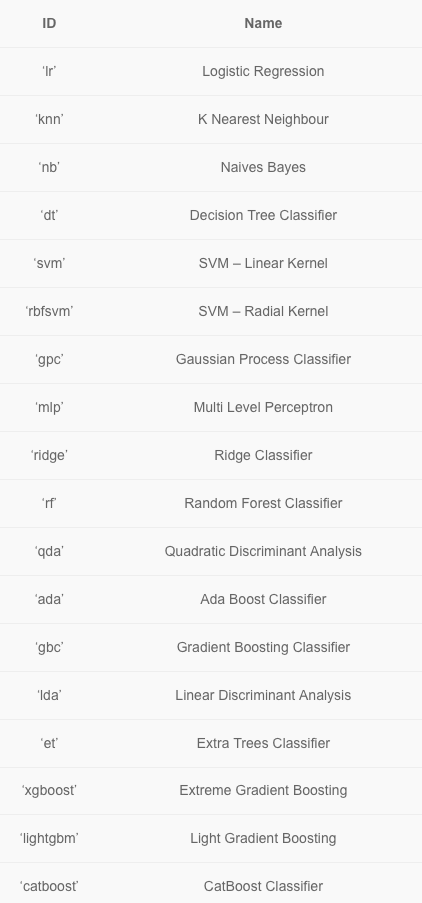
🏃♀️ 여러개의 모델을 비교 : compare_models
- 20가지의 각 모델별 MAE, MSE, RMSE, R2, RMSLE, MAPE 와 프로세스 시간을 비교해준다.
- 코드 실행 후 결과 테이블에 자동으로 추천 모델을 하이라이트해준다.
- 추천 상위 기준은 디폴트 값으로는, 분류 모델은 정확도, 회귀모델은 R2의 점수가 높은 순에서 나준 순으로 정렬해준다.
top5 = compare_models(sort='Accuracy', n_select=5)
print(top5)
# n_select 파라미터를 지정하여 가장 성능이 좋은 모델 5개를 출력해볼 수 있음
# 파라미터로 원하는 metric 으로 정렬 가능, 사용을 원하는 모델 개수를 지정 가능
◽ 파라미터
| sort | 모델을 정렬할 평가지표 지정 |
| n_select | 상위 몇개의 모델을 선택할지 지정 |
| fold | 교차검증할 폴드수 지정 |
👀 출력 결과
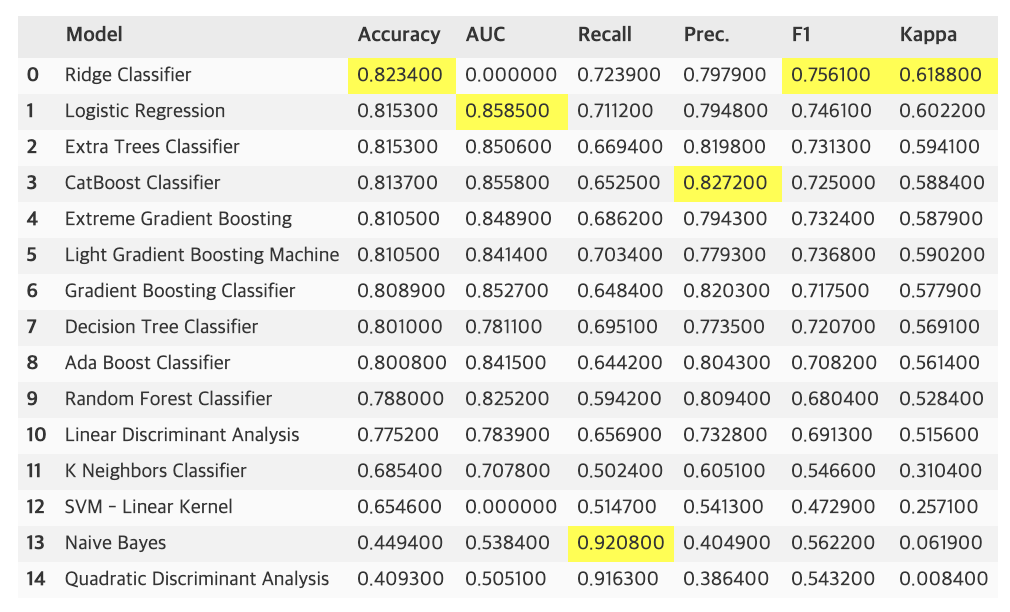
- 각 metric 별로 가장 성능이 좋은 위치에 노란색으로 하이라이트됨
🏃♀️ 하나의 ML 모델 생성 : create_model
# 랜덤포레스트 모델 생성 예시
rf = create_model('rf', fold=5)
- compare_models 를 참고하여 모델 하나를 선택해 create_model 로 살펴본다. fold 를 생성하여 자동으로 교차검증을 수행 (하이퍼 파라미터 탐색 자동화) 해준다. fold 의 기본 값은 10이다. fold 들의 평균 metric 값도 출력해준다.
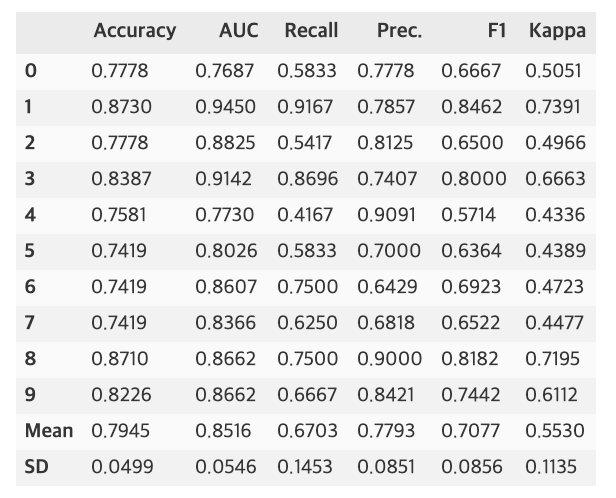
◽ 파라미터
| estimator | 어떤 모델을 사용할건지 결정 |
| ensemble | estimator 를 앙상블한 결과를 나타냄 |
| method | bagging 혹은 boosting 선택 가능 |
| fold | K-fold 수 |
| round | 점수 반올림으로 표시할 자리를 적는다. |
| cross_validation | True 시 교차검증을 사용함 |
(3) 모델 최적화/모델 결합
| 모듈 | 내용 |
| tune_model( ) | 모델의 하이퍼 파라미터를 최적화하는 모듈. 반복 횟수나 최적화 metric 을 선택 가능 |
| ensemble_model( ) | 앙상블 기법을 구현한 모듈로 배깅과 부스팅을 파라미터에서 선택할 수 있다. |
| blend_models( ) | voting 알고리즘을 구현한 모듈로 compare_models 에서 성능이 잘 나온 모델을 선택하는 파라미터 n_select 를 적용시켜 할 수 있다. 보팅 방식으로 method = 'soft' 혹은 'hard' 를 지정할 수 있다. |
| stack_models( ) | stacking ensemble 방법을 구현한 모듈이다. compare_models 에서 성능이 잘 나온 모델을 선택하는 파라미터 n_select 를 적용시켜 할 수 있다. |
🏃♀️ 모델튜닝 : tune_model
| estimator | 사용할 모델 입력 |
| fold | K-fold 수 |
| n_iter | random grid search 를 한 회차당 반복할 횟수 |
| custom_grid | 직접 파라미터 범위 조정 |
| optimize | 파라미터 튜닝 과정에서 어떤 점수를 기준으로 할 것인지 선택 👉 Accuracy, AUC, Recall, Precision, F1 |
| choose_better | 성능이 높아지지 않을 경우 tuning 을 하지 않은 모델을 반환 |
(4) Prediction
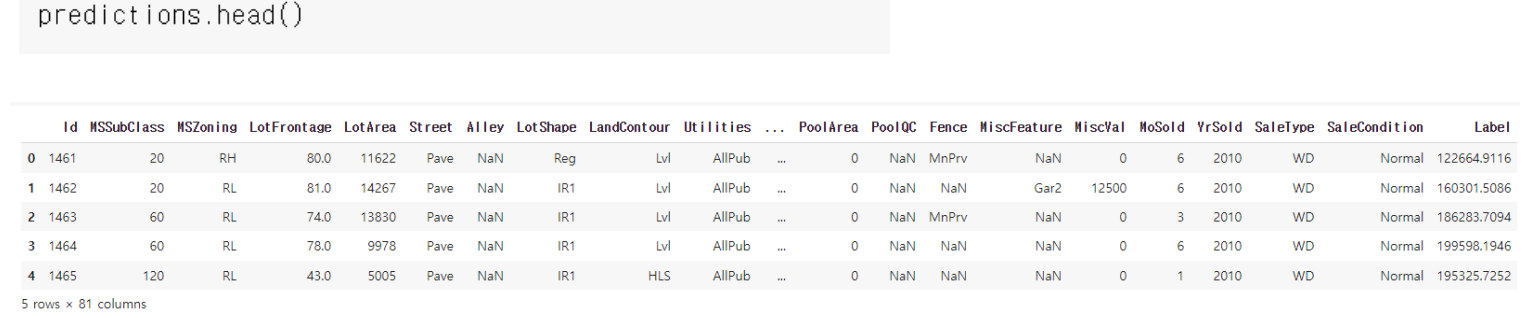
- finalize_model( ) : 전체 데이터로 마지막 학습을 진행
- predict_model( ) : 학습된 모델변수와 테스트할 데이터프레임을 입력한다.
final_model = finalize_model(model_train)
prediction = predict_model(final_model, data=dataset)

(5) 모델 평가/시각화
| 모듈 | 내용 |
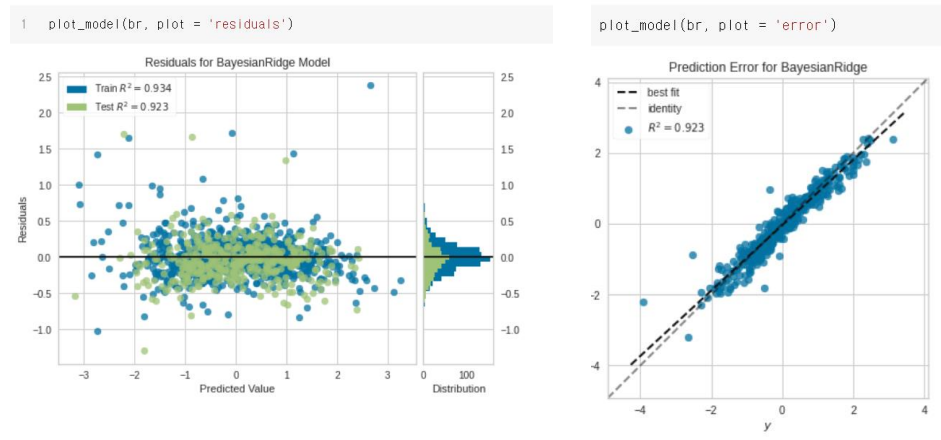
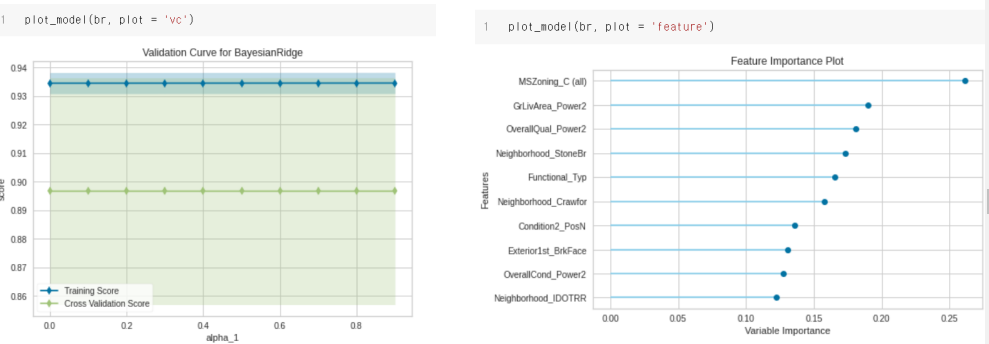
| plot_model( ) | 학습한 모델에 대한 각종 지표들을 시각화한 플롯을 그려준다. plot 입력 인자로 auc, threshold, confusion matrix 등 약 15가지 이상의 다양한 플롯들을 지원한다. plot = 'feature' 를 입력하면 변수 중요도를 출력해준다. |
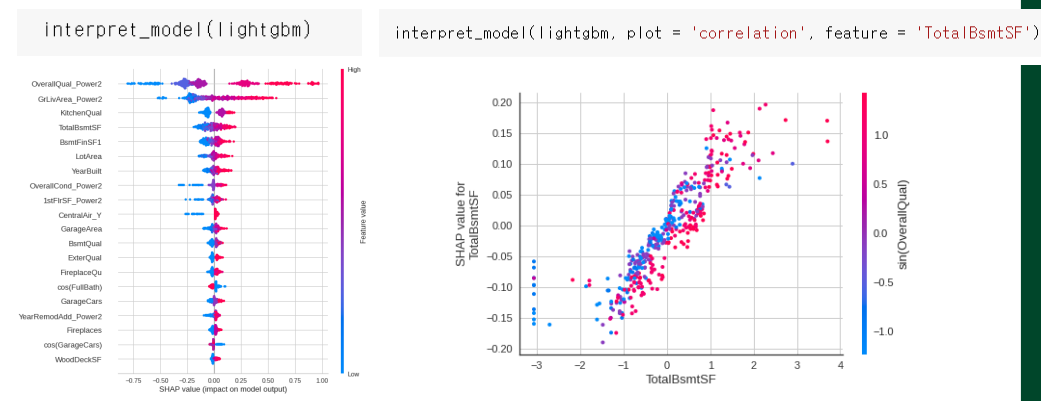
| interpret_model( ) | 모델이 예측한 결과에 대해 각 파라미터들이 얼마나 영향을 주었는지 시각화해 보여준다. ◽ https://shap.readthedocs.io/en/latest/ |
| evaluate_model( ) | 모델 분석 후 각 플롯을 볼 수 있도록 api 를 제공한다. 한번에 플롯을 전부 띄우고 싶으면 plot model 보단 이 모듈을 사용하는 것이 좋다. |
| get_leaderborard( ) | setup 이후 훈련된 모든 모델을 출력한다. |
| dashboard( ) | 모델 분석에 대한 사용자 인터페이스를 제공해준다. |
| check_fairness( ) | 데이터셋에 각 feature 들에 대해 measure 를 확인해볼 수 있도록 모듈을 제공한다. |
| check_metric( ) | 확인하고 싶은 metric 과 정답 레이블, 예측 레이블을 넣어주면 결과값이 출력된다. |
◯ 분석과정 예제
👀 preprocessing parameter : https://pycaret.readthedocs.io/en/latest/api/regression.html
(1) setup without preprocessing
from pycaret.regression import *
# 1️⃣ 데이터 준비/전처리
reg1 = setup(train, target = 'SalePrice', session_id = 123, silent = True)
# 2️⃣ 여러개의 모델링 결과 비교
compare_models(sort = 'RMSE')
# 3️⃣ 2번 결과를 바탕으로 상위에 해당하는 모델에 대하여 개별 모델링을 진행
catboost = create_model('catboost', verbose = False)
gbr = create_model('gbr', verbose = False)
xgboost = create_model('xgboost', verbose = False)
# 4️⃣ 모델 튜닝 or 앙상블/스태킹
blend_m = blend_models(estimator_list = [catboost, gbr, xgboost])
stack_m = stack_models(estimator_list = [gbr, xgboost], meta_model = catboost, restack = True)
💥 직접 코랩에서 돌렸을 땐 catboost regressor 가 상위 모델 후보지에 없었음
(2) setup with preprocessing
- preprocessing 이 없었던 모델 성능 결과보다 약간 개선된 결과를 보임
from pycaret.regression import *
reg1 = setup(train, target = 'SalePrice', session_id = 123,
normalize = True, normalize_method = 'zscore',
transformation = True, transformation_method = 'yeo-johnson', transform_target = True,
ignore_low_variance = True, combine_rare_levels = True,
numeric_features=['OverallQual', 'OverallCond', 'BsmtFullBath', 'BsmtHalfBath',
'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr',
'TotRmsAbvGrd', 'Fireplaces', 'GarageCars', 'PoolArea'],
silent = True)
| normalize | 수치형 변수들을 주어진 범위로 스케일링함 |
| normalize_method | 스케일링 방법을 결정 👉 zscore (디폴트), minmax, maxabs, robust |
| transformation | 데이터의 power transform 여부 |
| transformation_method | transformation 의 유형을 결정 👉 yeo-johnson (디폴트), quantile |
| transform_target | 타겟변수가 정의된 방법을 통해 변환됨 (피처 변환과 별개로 타겟 변수에 대해 변환을 적용) |
| ignore_low_variance | low variance 를 가진 범주형 피처들이 데이터에서 제거됨 |
| combine_rare_levels | 특정 임계값보다 낮은 범주형 피처들의 레벨의 빈도 백분위수가 단일 수준으로 결합됨 |
| numeric_features | 데이터 타입이 맞지 않거나, silent 파라미터가 True 일 때 수치형 변수 타입을 직접 정의할 수 있음 |
👀 https://runebook.dev/ko/docs/scikit_learn/auto_examples/preprocessing/plot_map_data_to_normal : yeo-johnson PowerTransformer 정규분포 변환
(3) setup with advance preprocessing
from pycaret.regression import *
reg1 = setup(train, target = 'SalePrice', session_id = 123,
normalize = True, normalize_method = 'zscore',
transformation = True, transformation_method = 'yeo-johnson', transform_target = True,
numeric_features=['OverallQual', 'OverallCond', 'BsmtFullBath', 'BsmtHalfBath',
'FullBath', 'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr',
'TotRmsAbvGrd', 'Fireplaces', 'GarageCars', 'PoolArea'],
ordinal_features= {'ExterQual': ['Fa', 'TA', 'Gd', 'Ex'],
'ExterCond' : ['Po', 'Fa', 'TA', 'Gd', 'Ex'],
'BsmtQual' : ['Fa', 'TA', 'Gd', 'Ex'],
'BsmtCond' : ['Po', 'Fa', 'TA', 'Gd'],
'BsmtExposure' : ['No', 'Mn', 'Av', 'Gd'],
'HeatingQC' : ['Po', 'Fa', 'TA', 'Gd', 'Ex'],
'KitchenQual' : ['Fa', 'TA', 'Gd', 'Ex'],
'FireplaceQu' : ['Po', 'Fa', 'TA', 'Gd', 'Ex'],
'GarageQual' : ['Po', 'Fa', 'TA', 'Gd', 'Ex'],
'GarageCond' : ['Po', 'Fa', 'TA', 'Gd', 'Ex'],
'PoolQC' : ['Fa', 'Gd', 'Ex']},
polynomial_features = True, trigonometry_features = True, remove_outliers = True, outliers_threshold = 0.01,
silent = True #silent is set to True for unattended run during kernel execution
)
| ordinal_features | 범주형 피처들을 인코딩 |
| polynomial_features | 기존 피처들을 이용해 새로운 피처를 생성 |
| trigonometry_features | 기존 피처들을 이용해 새로운 피처를 생성 |
| remove_outliers | train 데이터의 outlier 제거 |
| outliers_threshold | 제거되는 outlier 퍼센트 지정 |
(4) plot
◽ Interpret_model : 모델이 예측한 결과에 대해 각 파라미터들이 얼마나 영향을 주었는지 시각화하여 보여줌
(5) finalize , predict
final_m = finalize_model(bend_all)
predictions = predict_model(final_m , data = test)
◯ 참고
➕ https://minimin2.tistory.com/137
➕ https://jaeworld.github.io/data%20science/PyCaret/
➕ https://koreapy.tistory.com/744
➕ https://leo-bb.tistory.com/62
➕ https://today-1.tistory.com/17
➕ https://dacon.io/competitions/official/235647/codeshare/2428
'3️⃣ Study at Univ > ○ 노트북 필사' 카테고리의 다른 글
| [개인 프로젝트] 시계열 이상치 탐지 스터디 ② (0) | 2022.05.11 |
|---|---|
| [개인 프로젝트] 시계열 이상치 탐지 스터디 ① (0) | 2022.05.09 |
| [kaggle] 2021년 여름방학 필사 스터디 파일 (0) | 2022.04.06 |
| [kaggle] 필사정리 Note_5 (0) | 2022.04.02 |
| [kaggle] 필사 정리 Note_4 (0) | 2022.03.11 |



댓글