👀 계량경제학 개인 공부용 포스트 글입니다.
◯ 더미변수, 상호작용항, 제곱항, 로그
• 상호작용항 : 한 변수의 영향이 다른 변수의 값에 의존할 수 있도록 할 때 상호작용항을 포함시킨다. 대표적인 상호작용항 이용의 예로는 이중차분법 (DiD) 이 있다. DiD 는 정책의 효과를 분석할 때 널리 사용된다.
• 제곱항 : 설명변수 증가의 효과가 그 설명변수 값이 증가함에 따라 + 에서 - 으로 바뀌거나 - 에서 + 로 바뀌는 경우 (포물선 모양처럼), 해당 설명변수의 제곱항을 우변에 포함한 모형을 설정할 수 있다.
• 로그 : 크기 자체보다는 증가율을 고려하는 거이 적절한 변수의 경우 통상적으로 로그를 취한다. 그러나 0의 값을 가질 수도 있기 때문에 까다로운 상황이 발생할 수 있다.
11. 다중회귀 관련 추가 주제
① 이진적 설명변수
• 더미변수를 포함시키는 것은 상대 집단을 기준 집단으로 삼아 비교한다는 뜻이다.
• 더미변수의 계수는 당해 집단과 기준집단 간의 절편의 차이를 의미한다.
• 더미변수들을 모두 우변에 포함시키면 공선성 문제가 발생하기 때문에, 더미변수 중 하나는 제외시켜야 한다.
• EX. 나이 : young (30대 이하), middle (40-50대) , old (60대이상)
↪ young 더미변수를 모형에서 제외시킨다는 것은 young = 1 인 집단을 기준 집단으로 삼는다는 것이며, 회귀식의 절편은 30대 이하의 절편이고, middle 계수는 40-50대와 30대 이하 간 절편의 차이, old 계수는 60대 이상과 30대 이하 간 절편의 차이를 나타낸다. 30대 이하와 다른 연령대 집단 간 수준 차이를 추정하고 통계 유의성 검정을 하고자 한다면, young 더미변수는 모형에서 제외시킨다.
② 상호작용항
◯ 예제
• log(wage) = β0 + β1•school + β2•exper + δ0•female + δ1•(female x school) + u
↪ 남성 : log(wage) = β0 + β1•school + β2•exper + u
↪ 여성 : log(wage) = (β0 + δ0) + (β1 + δ1)•school + β2•exper + u
↪ δ0 : 여성과 남성 간 절편의 차이
↪ δ1 : 여성과 남성 간 school 계수의 차이
◯ R에서 상호작용 추가하는 코드
lm(log(wage) ~ female*school + exper, data = wage1)
↪ female*school 는 female + school + female:school 과 동일한 표현이다. R에서는 상호작용항을 만들 때 콜론 부호 : 를 사용한다.
◯ 상호작용항과 더미변수의 의미
• 상호작용항은 교차되는(곱해지는) 한 변수의 영향이 교차되는 다른 변수의 값에 따라 달라지도록 해준다.
• 더미변수항은 절편의 차이를 불러오고, 상호작용항의 계수는 기울기의 차이를 불러온다.
• 상호작용항이 포함된 모형에서 더미변수의 계수가 음수라 하여 반드시 D=1 인 집단의 종속변수 값이 더 낮을것으로 기대 되는 것은 아니다. 기울기가 상이하여 두 직선이 어디선가는 반드시 서로 만나기 때문이다. 종속변수 기댓값은 설명변수 값들이 어디에 위치에 있는지에 따라 달라진다.
↪ 교차점 : x* = - δ0/δ1
• 특별한 이유가 없는 한, 교차항을 포함시키고자 한다면 반드시 서로 곱해지는 두 변수들을 각각 포함시켜야 할 것이다. 교차항인 female•school 을 포함시키려면, 그 안에 두 변수인 female 과 school 을 모두 별도의 설명변수로 포함시켜야 한다.
• 집단 간 구조 차이의 검정 : 상호작용항이 포함된 모형을 이용해 모집단 내 상이한 집단 간 종속변수와 설명변수들의 함수관계가 동일한지 상이한지 검정할 수 있다. 기울기의 차이에만 관심이 있으면 상호작용항의 계수가 0인지 검정하면 되고, 절편까지 포함하여 동일한지 관심 있으면 더미변수와 상호작용항의 계수들이 모두 0이라는 귀무가설을 F 검정하면 된다.
③ 이중차분
◯ 예제
• Y : 체력
• 1년동안 프로그램을 실시한 학교와 실시하지 않은 학교에서 프로그램 시작 시점 (before) 과 종료시점 (after) 에 학생들의 체력을 측정하여 프로그램의 효과를 평가하고자 한다.
• treatment group : 체력증진 프로그램에 참여한 학생들 집단
• control group : 참여하지 않은 학생들 집단
| 통제집단 | 처치집단 | |
| Before | A | B |
| After | C | D |
• 단순한 '차이' 의 방법은 프로그램의 효과만을 보기에는 불완전하다. 학교 간 체계적인 차이 (통제집단 vs 처치집단), 체력 측정 시기가 다른 데 (Before vs After) 에서 오는 체계적인 차이로 인해 오차평균 0 가정이 위배되어 OLS 추정량이 프로그램의 효과를 편향되게 추정할 수 있다.
• 가령 B와 D만을 고려하여, 프로그램의 효과를 살펴본다고 했을 때 여기에는 프로그램의 효과와 시차로 인한 평균 체력 차이를 합산한 값을 구해준다. "처치집단의 시간효과" 만을 제외한다면 프로그램의 효과만을 구할 수 있을 것이다. 여기서 핵심적인 가정이 등장한다. 바로 "parallel trend assumption" 이다.
• parallel trend assumption : 프로그램이 없었다면 전후 시기 종속변수의 평균적인 증가분은 처치집단과 통제집단에서 동일하였을 것이다 라는 가정이다. 해당 가정을 통해 측정시점 차이로 인한 처치집단 시간효과는 통제집단의 전후비교를 통해 알아낼 수 있다. 통제집단은 처치를 받지 않았기 때문에 그 전후비교는 오직 통제집단 시간효과와 같기 때문이다.
• a,b,c,d 를 A,B,C,D 범주에 속하는 체력 측정치들의 평균이라 하면
↪ d-b = (처치효과) + (처치집단 시간효과)
↪ c-a = (통제집단 시간효과)
↪ 처치집단 시간효과와 통제집단 시간효과가 동일하다는 가정 하에 처치효과는 = (d-b) - (c-a) 가 된다.
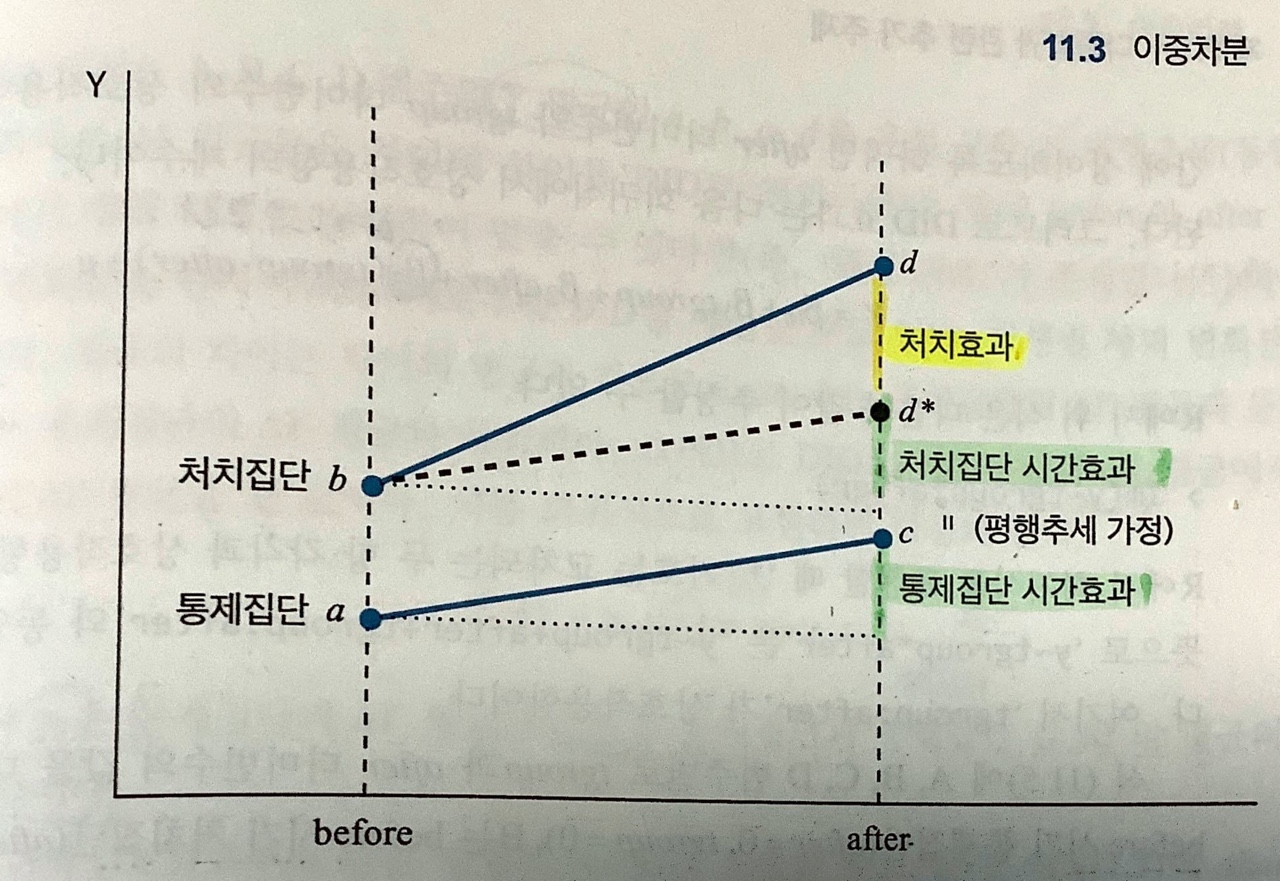
↪ 정책 효과가 DiD 라고 하는 것은 시간효과가 처치집단과 통제집단 간에 동일하다고 가정하는 것과 같다.
• Y = β0 + β1•tgroup + β2•after + β3•(tgroup•after) + u
↪ β3 : DID 효과
• 동일추세 가정은 오차평균0 가정보다 약한 가정이다. 가령 η_A, η_B, η_C, η_D 를 각 범주의 오차평균이라고 할 때, 평행추세 가정은 (η_D - η_B) - (η_C - η_A) = 0 이라는 뜻이고, 오차평균 0 가정은 η_A = η_B = η_C = η_D = 0 임을 의미한다. 오차평균0 가정이 성립하면 평행추세 가정도 성립한다. β3 만을 편향없이 추정하려면 평행추세 가정만 있으면 된다.
④ 제곱항
• 포물선 모양처럼 X가 일정수준에 달할 때까지 Y값이 증가하다가 그 이후 감소하거나 그 반대인 상황을 모형으로 표현하는데 유용하다.
• Y = β0 + β1•X1+ β2•X1^2 + β3•X2 + u
↪ X2 가 고정될 때 X1 이 d 만큼 증가하면 Y 의 평균은 대략 (β1+2•β2•X1)•d 만큼 증가한다. 효과가 X1 값의 수준에 영향을 받는다. 부호가 바뀌는 반환점은 -β1/(2•β2) 이다.
◯ 예제 1 : 나이의 2차함수로서의 흡연량
• cigs = β0 + β1•log(income) + β2•log(cigprice) + β3•educ + β4•age + β5•age^2 + u
↪ 평균적으로 젊은 나이에는 나이를 먹을수록 담배를 더 피웠다가, 나중에는 나이를 먹을수록 흡연량을 줄이는 경향이 있다. 따라서 age 를 제곱한 항도 추가한다. 함수 관계가 포물선 모양임을 고려할 때 β4 > 0 , β5 < 0 의 관계를 보일 것으로 예상한다.
↪ 추정결과 : β4 =0.780 , β5 = -0.009 (모두 통계적으로 유의) ⇨ age의 계수가 양수이고, age^2의 계수가 음수이므로 나이의 증가효과는 처음에 양이다가 나이가 들수록 감소함을 볼 수 있다. 이러한 효과 감소가 지속되다가 -β5/(2•β4) 의 값인 약 43세 이후에는 나이가 들수록 감소하는 것으로 추정된다.
※ 반환점이 표본 값 범위 내에 포함되어 있는지 확인하는 것은 중요하다.
◯ 예제 2 : 건평과 주택가격
• price 집값, lotsize : 건평, 침실수가 3개인 집들만을 대상으로 건평과 집값의 관계를 살펴보자
data(Housing, pacakage='Ecdat')
h3 <- subset(Housing, bedroos=3)
ols <- lm(log(price) ~ log(lotsize) + I(log(lotsize)^2), data = h3)
summary(ols)
↪ R에서 제곱항을 지정할 때 I() 를 빠뜨리면 안된다.
↪ 추정 결과, log(lotsize) 의 계수는 3.29 이고 log(lotsize)^2 의 계수는 - 0.165 이며 5% 유의수준에서 통계적으로 유의하다. 건평이 작을 때는 건평 증가의 효과가 크지만, 건평이 점점 커지면서 건평 증가의 효과는 점점 줄어드는 것으로 해석해 볼 수 있다.
↪ 그러나 반환점을 계산해보면 log(lotsize) 가 9.965 일 때 도달하게 되는데, log(lotsize) 의 표본 최댓값은 9.655로 표본 내에는 반환점에 도달한 경우가 없다. 따라서 반환점에 도착하는 관측치가 없기 때문에 선형회귀를 하더라도 우상향하는 관계를 얻을 것으로 예상된다.
• 설명변수 표본값의 범위를 넘어서는 지점에 대해 추정 결과를 사용한 예측을 하는 것을 extrapolation (외삽) 이라고 한다. 이러한 외삽은 해석이 옳지 않기 때문에 해서는 안 된다.
• 제곱항이 들어가 있는 모형에선 반환점을 구해주는 것이 좋다. 만일 표본 내에서 반환점을 넘어섰으면 제곱항이 포함된 모형이 자료를 잘 기술해주는 경우가 많다. 반환점을 넘어서지 않았다면 함부로 반환점에 대해 이야기 하지 않는 것이 좋다.
⑤ 0이 될 수 있는 설명변수의 로그 변환
• 금액이나 수량처럼 변화율을 기준으로 논의를 전개하는 것이 자연스러운 변수는 보통 로그를 취한다. 가령 "소득" 이 그렇다. 100만원에서 110만원으로 증가하는 것은 10만원 증가이며 10% 증가이다. 반면 500만원이 10% 증가하면 550만원이고, 100만원이 5개 있는 상황으로 해석하면 110만원과 550만원이 비교가 자연스럽다.
• 로그는 오직 양의 값에만 취할 수 있고 0이나 음수에는 취할 수 없다. 자료에 따라 0의 값을 가질수도 있기 때문에 로그를 취할 수 없는 경우가 발생하기도 한다.
◯ 0값이 있는 경우 사용할 대체 방법
⑴ 값이 0인 관측치 제외시키기 : lm(y~log(x1), subset= x1 > 0)
↪ X1 > 0 인 부분집합만을 사용한다는 단점이 있다.
⑵ 0을 특정한 단위 값으로 치환 : 0의 값을 특정한 양의 값으로 치환 후 로그를 취하는 방법으로, 특정한 값은 연구자가 정한다. 가령 x1 이 '원' 단위 금액이고 연구자가 0원을 1원으로 치환하고자 한다면 x1a = ifelse(x1>0, x1, 1) 과 같이 한 후 lm(y~log(x1a)) 로 회귀분석을 하면 된다. 다만 이 방법을 사용할 때에는 반드시 단위를 붙여서 "0원을 1원으로 치환한다" 라고 표현해야 한다.
⑶ 더하나 마나 한 값을 더하기 : X1 값에 매우 작은 값을 더한 다음 로그를 취하는 방법이다. X1 값의 규모를 고려할 때 가령 X1 의 규모가 1,000,000 이라면, 이에 비해 아주 작은 값인 1을 더해준다. lm(y~log(1+x1)). 그러나 이러한 방법은 선택하는 숫자가 자의적이고 선택에 따라 추정값이 달라진다는 것이다. 해당 방법을 사용할 때에도 더하는 숫자의 의미를 분명히 알고 있어야 한다.
⑷ 0을 1로 치환한 후 0에 해당하는 더미 사용 : 0을 1로 치환하고 나서 1이라는 자의적인 선택의 영향을 제거하기 위해 X1=0 에 해당하는 더미변수를 포함하는 방법이다. lm(y~log(x1a) + I(x1==0)) 으로 회귀하는 것이다. 이렇게 더미변수를 추가하면, 추정 결과에 아무런 실질적인 차이가 없게 된다.
⑸ 비선형성을 제곱항으로 처리 : 로그를 취하지 않는 방법이다. 그러나 종속변수와 log(x1) 의 관계가 선형이면 종속변수와 X1의 관계는 비선형이 되기 때문에, X 의 제곱항을 포함시켜 함수의 형태를 유연하게 할 필요가 있다.
⑥ 함수형태 설정 오류의 검정
• 함수형태가 올바르게 설정되었는지 검정하는 것 : Ramsey 교수가 제안한 회귀설정오류 검정 (RESET) 이 많이 사용된다. 우변에 맞춘 값의 제곱, 세제곱, 네제곱 등을 추가하여 이 추가된 설명변수들의 유의성을 표준적인 F 검정을 이용해 검정한다. p값이 작다면 모형 설정이 잘못되었다는 증거다.
library(lmtest)
ols <- lm(y~x1+x2)
resettest(ols, power = 2:3)
'1️⃣ AI•DS > ⚾ 계량경제•통계' 카테고리의 다른 글
| 계량경제학 강의_한치록_가정의 현실화 13장 (1) | 2023.05.22 |
|---|---|
| 계량경제학 강의_한치록_가정의 현실화 12장 (1) | 2023.05.22 |
| 계량경제학 스터디 Lecture 7. DiD (0) | 2023.05.19 |
| 계량경제학 강의_한치록_다중회귀 10장 (1) | 2023.05.19 |
| 계량경제학 강의_한치록_다중회귀 9장 (0) | 2023.05.18 |

댓글