👀 계량경제학 개인 공부용 포스트 글입니다.
1. Causality in Practice
① Motivation
• 세상은 연관관계로 구성되어 있다. 사람들은 종종 상관관계를 인과관계로 착각하곤 한다.
• 연구자들은 인과관계를 정의하는데 관심이 있다.
② What do we mean by causality?

• 선형회귀 모델에서, 만약 E[u | x1,x2,...,xk] = E[u] 가정 (Conditional mean independence : u의 평균은 x에 독립적이다) 을 만족한다면, β1은 y에 대한 x1의 인과효과로 볼 수 있다. (※ 한치록 계량경제학 설명 참고하기 : 고정된 설명변수)
• CMI 는 u 와 x가 uncorrelated 되어있다는 것을 의미한다.
↪ 쉽게 설명하면, X와 Y가 명확한 인과적 관계를 가지려면, 이를 제외한 변수들 (u) 을 통제해야 (즉, u는 x와 연관이 없어야) 한다는 의미
③ Tree Thresta to Causal inference
◯ CMI 조건을 위배하고 내생성을 발생시키는 주요 요인들
• Omitted variable bias
• Measurement error bias
• Simultaneity bias
• regressor 가 error term 과 관련이 있으면, 해당 regressor 를 endogenous 하다고 말한다.
2. Omitted variable bias : 누락된 변수로 인해, Cov(x,u) 가 0이 되지 않으며 내생성이 발생한다.
◯ Definition
• 연구자들이 가장 많이 우려하는 부분 중 하나이다.
• Basic idea : y에 영향을 미치고, x와 상관관계가 있는 변수 z 를 포함하고 있는 estimation error u
• 예를들어 아래와 같은 모델이 있다고 가정해보자. 이때 CMI 는 true model 에 대해서만 적용된다.
• x에 대해 추정된 계수 β1_hat 은 다음과 같다.
↪ cov(x,z) = 0 이거나, β2=0 로 z가 y에 영향이 없을 때에만 추정된 계수가 unbiased 하다.
↪ bias 의 크기와 방향은 β2와 cov(x,z)/var(x) 에 의해 정해진다. z가 y에 positive effect (β2 > 0) 을 미치고, x와 z는 양의 상관관계를 (cov(x,z) > 0) 가진다면, bias 는 양의 부호를 가진다.
◯ Example
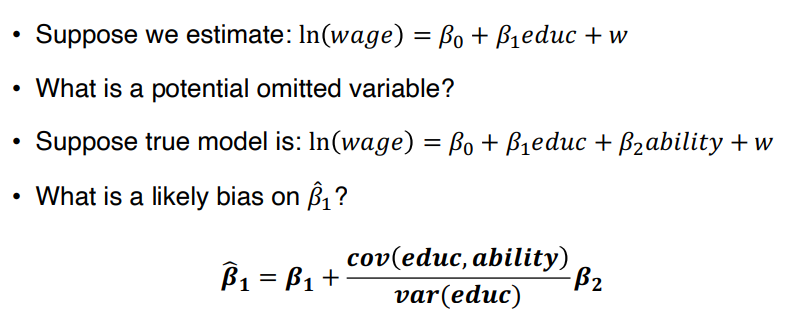
◯ OVB formula
• Omitted variable 이 여러개라면 bias 부분은 복잡하게 계산된다.
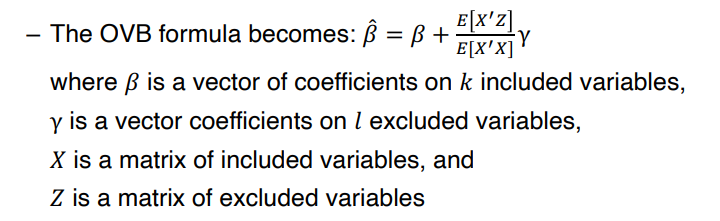
• 이러한 Omitted variable bias 를 제거하기 위해선, omitted variable 의 유형이 Observable 한지 Unobservable 한지에 따라 달라진다.
◯ Observable omitted variable
⑴ Functional Form Misspecification: observable omitted variable 의 special case
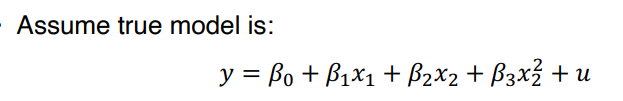
• 그러나 squared term x2^2 을 omitted 할 가능성이 높다.
• 이런 경우에는 squared term 이나 cubed term 을 추가해보면서, 계수값에 변화가 있는지 살펴볼 수 있다.
⑵ Davidson-MacKinnon Test
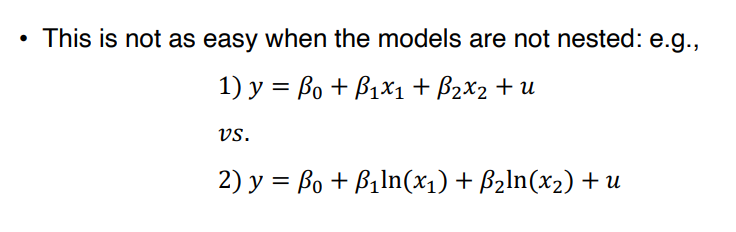

• 모델이 중첩되어 있지 않다면, 가설검정을 진행하는 방식을 채택해볼 수 있다.
◯ Unobservable omitted variable

• ability 를 측정 및 관측할 수 없는 경우 → ability 와 상관관계가 있는, 근접할 수 있는 다른 변수 (ex. IQ) 를 찾는다 : Proxy variable
◯ Proxy variable

↪ x3* = δ0 + δ1•x3 + v
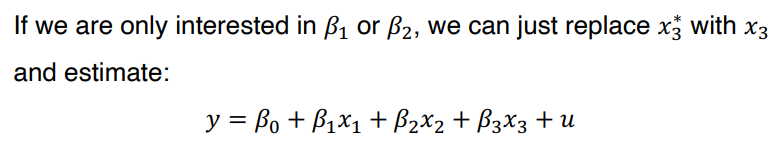

↪ proxy 를 포함시킨 후에는 다른 변수가 unobservable variable 을 설명하지 않는다. 즉, E(v | x1,x2,x3) = 0 이다. E[x3* | x1,x2,x3] = E[x3* | x3] 라면, 즉 x3에 대해 통제했을 때, x1 혹은 x2에 의존하지 않는다면 x3 는 x3* 에 대한 좋은 proxy 라 할 수 있다.

◯ Summary
• OVB 는 인과관계를 성립하지 못하게 한다.
• 생략된 관찰가능한 변수는 회귀분석에서 통제되어야 한다. 다른 수식을 반드시 검정해야한다. 만약 관찰되지 않은 변수의 계수가 우리가 관심 있는 것이 아니라면, proxy 를 사용해 다른 매개 변수에서 OVB를 제거할 수 있습니다. Proxy 는 관찰 불가능한 변수의 계수의 부포를 결정하는데 사용될 수 있다.
3. Measurement error bias
① Measurement error bias

• 변수의 측정을 부정확하게 할 때, 측정오차가 발생한다. 가령 항상소득과 저축 사이의 인과관계를 보고자 할 때, permanent income 은 관측이 불가능하여, 최근 10년간의 평균 소득으로 이를 대체하게 되면 이로인한 bias 가 발생하게 된다.
• EX. avg. tax rate is noisy measure of marg. tax rate
• Proxy 와 개념이 비슷해보일 수 있는데, Proxy 는 완전히 관측 불가능한/측정 불가능한 변수를 대체하기 위해 사용되는 것이고, 측정 오류는 관찰하지 않은 변수가 잘 정의되어 있고 정량화할 수 있지만 측정값에 오차가 있는 경우를 말한다.
② Measurement error of Dependent variable
◯ estimation
• bias 에 있어 y에 measurement error 가 존재하는 것은 문제가 되지 않는다. 다만 standard error 가 커질 수 있다.

• y* 를 y의 대체값이라 했을 때, error e 는 y-y* 와 같다. 그러나 우리는 y를 관찰해야 하므로 위와 같이 식을 추정해볼 수 있다.
• E(e|x) = 0 이라면 OLS 추정치는 consistent 하고 unbiased 하다. 문제가 되는 부분은 standard error 가 커진다는 것 뿐이다. Var(u+e) > Var(u)
③ Measurement error of Independent variable
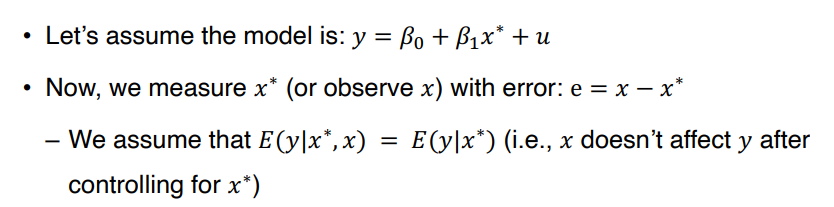
• 2가지 가정
⑴ Measurement error, e, is uncorrelated with the observed measure,x
⑵ Measurement error, e, is uncorrelated with the unobserved measure x*
↪ ⑴ 가정에서 x* 를 x-e 로 대체하면, bias 는 없다. 대신 standard error 가 증가한다.
↪ 그러나 ⑵ 가정에서 e 가 x* 와 uncorrelated 하다고 하면, 이는 e가 x와는 correlated 함을 의미하기 때문에 biased 된 estimate 를 얻는다. 해당 문제를 Classical Error-in-variables라고 한다.
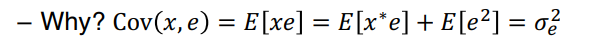
4. Simultaneity bias
• y 변수의 변화에 x가 영향을 받을 때 발생하는 문제이다.
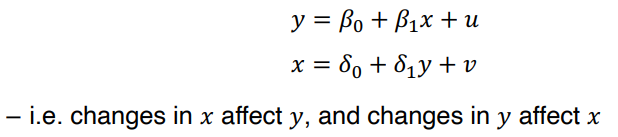
• Simultaneity bias 가 발생하는 이유
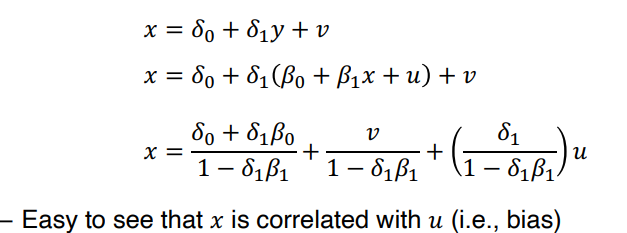
5. Bad Controls
• Simultaneity bias 와 같이 bad control 은 bias 를 가져온다.
• Bad control revives the selection bias again
◯ Summary

'1️⃣ AI•DS > ⚾ 계량경제•통계' 카테고리의 다른 글
| 계량경제학 스터디 Lecture 5. Instrumental variables (0) | 2023.05.15 |
|---|---|
| 계량경제학 강의_한치록_단순회귀 7장 (0) | 2023.05.15 |
| 계량경제학 강의_한치록_단순회귀 5장, 6장 (0) | 2023.05.13 |
| 계량경제학 강의_한치록_단순회귀 4장 (0) | 2023.05.12 |
| 계량경제학 스터디 Lecture 3. Matching (0) | 2023.05.12 |

댓글