📌 교내 '인공지능' 수업을 통해 공부한 내용을 정리한 것입니다.
요약
① Universal approximation theorem
② Activation function
③ DNN : why deep?
④ Random Initialization
- tanh, ReLU : 가중치가 0으로 고정
- sigmoid : 가중치가 suboptimal matrix 형태로 업데이트
⑤ Application example : Face recognition
1️⃣ Universal approximation thm , activation function
① Universal approximation theorems
👀 충분한 가중치가 적용되었을 때, MLP 로 어떠한 함수도 근사시킬 수 있다.
- hidden layer 에 있는 hidden unit 의 개수가 충분히 많다면 2개의 layer 로 구성된 MLP 로 모든 함수를 근사시킬 수 있다.

🤔 그렇다면 딥러닝을 왜 사용하는가 →효율성의 문제
② 활성화 함수
👀 활성화 함수는 non-linearlity 를 부여하여 NN 으로 비선형적인 문제를 풀 수 있도록 한다.
- 비선형 함수를 통해 각 layer 사이를 비선형적으로 연결시켜준다.
- 궁극적으로 세상에 있는 복잡한 문제는 linear 하게 풀 수 없는 문제가 더 많다.
- 활성화함수가 존재해야 layer 를 쌓으며 feature extraction 을 통해 space transformation 을 수행할 수 있다.

💨 활성화 함수가 없으면 공간변환이 발생하지 않아 layer 를 쌓아도 선형변환만 발생함
층을 쌓는 것이 무의미 해짐 🙄
🐾 참고 : linear vs non-linear

③ 활성화 함수 종류
👀 활성화 함수로 미분 가능하고 non-linear 한 함수가 자주 사용된다.

👀 Gradient descent (역전파) 계산시 필요한 활성화 함수 미분

2️⃣ DNN
① Deep Neural network
👀 layer 를 많이 쌓은 네트워크 = DNN



👀 Fully-connected Network (Dens layer) : 뉴런들이 전결합 되어있는 상태

👀 Convolution Neural Network : layer 가 전결합 되어 있지 않다.

👀 뉴런 사이의 결합 형태에 따라 종류가 다양하다.
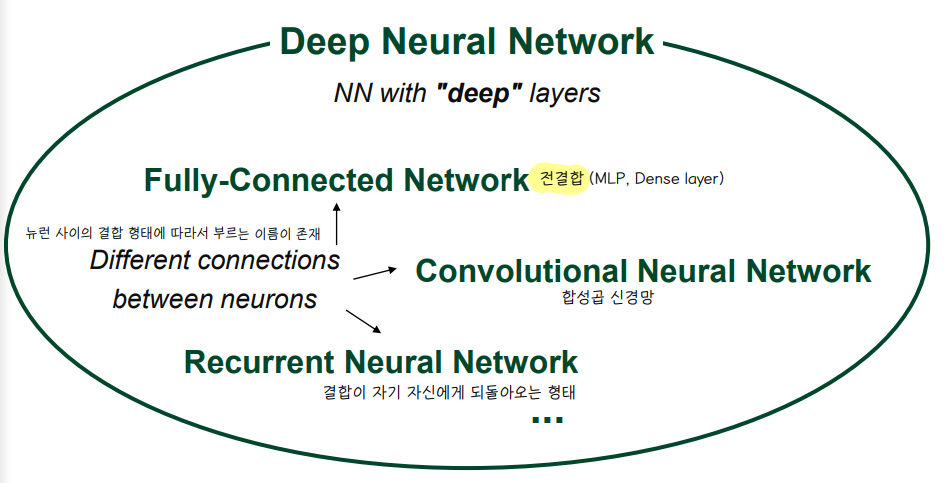
👀 서로 다른 결합 형태의 layer 를 섞어서 모델을 생성하기도 한다.

② 깊은 층을 형성하는 이유 ft. Circuit Theory Analogy
👀 Small (hidden units) n-layer dnn == Shallower network with exponentially more hidden units
💨 그러나 효율성은 왼쪽 network 가 더 좋음!

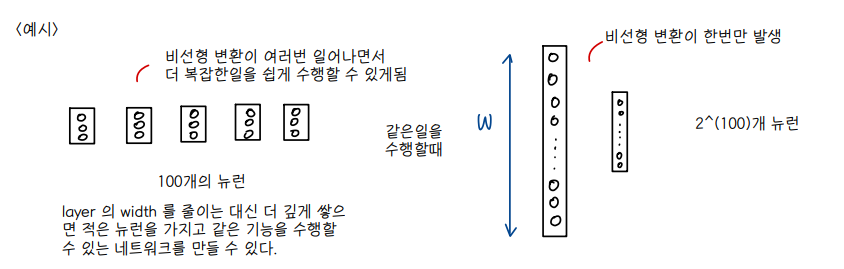
- 뉴런 개수는 적더라도 층을 깊이 쌓은 network 가 오히려 비선형 변환이 여러번 발생하며 더 복잡한 task 를 쉽게 수행할 수 있다.
③ Forward propagation in DNN

④ Backpropagation in DNN
👀 dw, dz, dy 로 연산되는 연쇄과정 이해하기!

👀 MLP 에서 정리했던 gradient descent 연산 과정 대입해서 이해할것
👉 dW = error(1)* input
👉 error(1) = error(2) * W * f '
👻 error(2) * W = dy = input gradient




⑤ hyperparameters
👀 Parameter
- 기계가 training 을 통해 값을 update 한다.

👀 HyperParameter
- trial error, 즉 사람이 직접 값을 바꿔가며 최적의 값을 결정해야 한다.

⑥ Random Initialization problem
👀 초기값을 다르게 설정하면 훈련 결과도 달라진다.
- 초기값을 잘 설정해주는 것도 매우 중요하다 ⭐⭐
- 일반적으로는 small random number 로 초기값을 설정한다.
👀 초기값을 0으로 설정할 때 발생하는 문제점
(1) 활성화 함수가 tanh 나 ReLU 일때
- Weight 값이 0에서 벗어나지 못하며 weight update 가 이루어지지 않는다.
(2) 활성화 함수가 Sigmoid 일때
- weight matrix 가 칼럼별로 항상 같은 값으로만 갱신되는 suboptimal 한 현상이 발생하기 때문에 최적의 weight 값을 찾지 못하는 문제가 발생한다.
- weight 값이 다양해야 훈련도 잘 이루어진다.
⭐ 결론은 가중치 초기값을 0으로 설정하면 안!된!다!
3️⃣ DNN 의 응용 : Face recognition
① Training data
👀 layer 를 많이 쌓은 네트워크 = DNN
- 전체 20명으로 구성되어 있고, 한 사람당 32개의 흑백 사진이 존재하는데 각 사진별로 사람의 표정, 얼굴 방향, 선글라스 착용 유무가 다르게 설정되어 있다. 원래 이미지 데이터는 120x128 크기의 픽셀로 이루어져 있다.
- 목표는 사람이 어느방향을 보고 있는지 left, right, straight ahead, up 중에 하나를 맞추는 것

- 120x128 pixel 의 원본 이미지를 30x32 크기로 변환시킨 후, 2d 인 matrix 를 1d로 flatten 시켜 크기가 960인 벡터를 입력으로 넣는다.
- hidden unit 은 3개, output unit 은 4개
- 최종적으로 960 x 3 x 4 network 가 훈련된다.
② DNN design
👀 Input Encoding : 인풋을 어떤 형태로 표현하여 NN에 넣을까?
(1) Feature extraction (preprocessing)
- 사람이 직접 결정한 key feature 를 뽑아 인풋으로 넣어준다.
- (예) 이미지 데이터에서 edge, region of uniform intensity 등 특정 부분을 추출해 인풋으로 넣어준다.
- (단점) 피처를 추출하는데 시간이 오래 걸리고, 피처의 개수가 이미지마다 다르게 추출되는, 즉 input 개수가 고정되지 않는 문제점이 발생할 수 있다. 따라서 이 방법은 잘 사용하지 않는다.
(2) Coarse-resolution
- 연산량을 줄이기 위해 이미지의 크기를 줄이는 방법이다.
- Face recognition 도 이 방법을 사용하여 120x128 이미지 픽셀을 30x32 크기로 줄였다. 즉 연산량이 16배 감소했다고 볼 수 있다. (가로 1/4, 세로 1/4)
- 원본 이미지를 그대로 인풋으로 넣어주는 것 보단, course resolution 을 하여 원본 이미지를 요약한 형태로 넣어주는 것이 복잡도를 줄여 오히려 학습에는 더 좋다.
👀 Output Encoding
(1) One Unit Scheme
- multiple threshold values 를 사용하여 output 이 1개로 도출되는 표현 방식을 사용

(2) Multiple Unit Scheme
- single threshold value 를 사용하여 다수의 output 을 도출하는 표현식을 사용
- One hot encoding 이 대표적인 표현식
- 1과 0으로 구성된 원핫인코딩 방식뿐 아니라 각 값을 '확률값'으로 표현하는 표현식도 존재한다.

- multiple output 표현하면 1. target function 을 표현하는데 있어서 자유도가 높다 2. 가장 큰 값과 그 다음으로 큰 값의 차이가 클수록 nn 이 더 결과에 자신있다고 해석하는 confidence 방법을 사용할 수 있다 는 장점이 있다.
(3) Ground Truth 의 형태

- Target 값을 원핫인코딩으로 도출하는 것 보단 오른쪽과 같은 소수점 방식으로 표현하는 것이 좋다.
- 가령 시그모이드 함수라고 하면, 시그모이드는 최대값이 0.99999로 정답인 1에 근접해지기 위해 bound 없이 가중치가 계속 증가하는 문제점이 발생한다. 0.9는 시그모이드가 도출해낼 수 있는 bound 가 있는 값이므로 가중치가 유한한 값으로 결정될 수 있다.
- 👀 그러나 실제 딥러닝에서는 왼쪽 원핫 인코딩 형식으로 표현함
👀 Network architecture
- 은닉층을 몇 개 사용할 것인가 👉 trial error
- 하나의 layer 에 대해 몇 개의 은닉노드를 사용할 것인가 👉 trial error

👀 Hyperparameters
- 학습률 설정
- 0에 가까운 작은 값으로 가중치를 초기화한다.
- 교차검증을 통해 에포크 수를 결정한다.
- 검증 데이터 셋에서 가장 좋은 성능을 보인 nn 의 구조가 최종 nn 이 된다.

'1️⃣ AI•DS > 📒 딥러닝' 카테고리의 다른 글
| [인공지능] Training CNN (0) | 2022.04.26 |
|---|---|
| [인공지능] CNN (0) | 2022.04.23 |
| [인공지능] MLP (0) | 2022.04.21 |
| [인공지능] Basic Neural Network (0) | 2022.04.21 |
| [인공지능] Introduction to AI/Deep learning (0) | 2022.04.21 |




댓글