👀 계량경제학 개인 공부용 포스트 글 입니다.
① 더미변수
◯ 더미변수
• 남여 임금격차 : Y = α + β•Educ + ϒ•male + u
• Y = α + β•Educ + ϒ•male + u
Y_m = α + β•Educ + ϒ•1 + u
Y_f = α + β•Educ + ϒ•0+ u
-----------------------------------------
Y_m - Y_f = ϒ
→ 해석 : 여성에 비해 남성은 ϒ 만큼 임금을 더 (덜) 받는다.
• 로그 차분인 경우에는 상대적 변화율을 의미한다 : lnY = α + β•Educ + ϒ•male + u
↪ lnYm - lnYf = (Ym - Yf)/Yf = 여성대비 남성 임금의 상대적 변화율 = 100•ϒ
↪ 해석 : 여성에 비해 남성은 100•ϒ % 임금을 더 (덜) 받는다.
◯ 차분
• 1중차분 : 더미변수 1개
↪ ex. 코로나 시기 이전과 이후의 소득차이 (모든 개체가 코로나에 영향을 동일하게 받는다고 가정)
• 2중차분 : 더미변수 2개
↪ 정책시행 : 코로나 시기 이전/이후
↪ 영향집단 : 코로나의 영향을 받는 그룹 (ex. 자영업자) 과 그렇지 않은 그룹 (ex. 봉급생활자)
• 3중차분 : 더미변수 3개
↪ 코로나 시기 이전/이후
↪ 코로나 영향을 받는 그룹과 그렇지 않은 그룹
↪ 청년층/중장년층
② DiD 예제
◯ 기본설명
• 소각장 건설이 주택 가격에 미치는 영향에 대한 연구
• 1978년에 소각장이 지어질 것이라는 공문이 나고, 1981년에 건설이 시작됨 ⇨ 1978년과 1981 년의 자료만 사용하여 분석
• 알고 싶은 것 : 소각장 근처에 위치한 주택 가격 (처치집단) 들이 소각장에서 멀리 떨어진 주택들의 가격 (통제집단) 보다 더 많이 떨어지는지
• 주택가격들에 영향을 미칠 수 있는 변수들은 포함시키고, 관심을 갖는 변수는 nearinc 로 설정해 소각장 3마일 이내의 주택이면 1, 그외는 0으로 할당한다. 종속변수는 log(price) 주택가격으로 소각장을 짓기 시작한 1981년에 대한 더미변수 (y81) 가 추가된다. 여기서 log 를 취한 이유는 % 로 표현하기 위함이다.

↪ nearinc : 집단 더미
↪ y81 : 정책 더미
↪ 각각의 더미에 대한 변수를 넣고, 추가로 해당 더미들을 곱한 교호항을 넣는다.
↪ β3 : 소각장 근처에 위치한 주택(1)이면서, 소각장 건설이 시작된 이후 시점(1) ⇨ key factor
• 처치그룹 (nearinc = 1) 에 대해 자세히 살펴봄 : 정책 시행 전과 후의 주택 가격 차이 = β2 + β3

• 통제그룹 (nearinc = 0) 에 대해 자세히 살펴봄 : 정책 시행 전과 후의 주택 가격 차이 = β2

• 처치그룹과 통제그룹 간의 정책 시행 전과 후의 주택 가격 차이 : ( β2 + β3 ) - β2 = β3
◯ R코드
library(wooldridge);library(stargazer);library(haven)
data(kielmc , package = 'wooldridge')
data(package = 'wooldridge')
# view(kielmc)
# 단순히 DID 추정 계수만을 포함시켜 추정
DiD <- lm(log(rprice) ~ nearinc*y81, data = kielmc)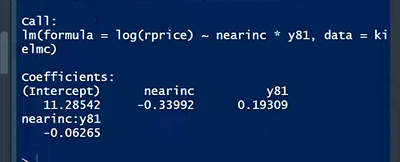
# 주택 가격에 영향을 줄 수 있는 이용가능한 변수들을 포함시켜 제대로 모형 추정
DiDcontr <- lm(log(rprice) ~ nearinc*y81 + age + I(age^2) +
log(inst) + log(land) + log(area) + rooms + baths, data = kielmc)
※ R stargazer : 논문에 들어가는 표 형태로 제작하기
stargazer(DiD, DiDcontr, type = "html", out = "did비교.doc")

• β3에 대한 해석 ⭐

③ 삼중차분 DDD 모형
◯ 기본설명
• DDD 는 두 개의 DID 모형을 다시 차분하는 것이다.
• 특정 정책의 효과가 (정책이 시행되는 그룹과 시행되지 않는 그룹 간의 차이가 있는지) 와 (정책과는 관련이 없는 특정 다른 집단 간의 차이여부)를 동시에 고려하고자 할 경우 사용한다.
• EX. 코로나 더미, 자영업자여부 더미, 수도권 여부 더미
• DID 는 2개의 이항변수 (정책더미, 처치/통제그룹 더미) 가 필요한 반면, DDD 는 3개의 이항변수가 필요하다.


◯ 코드실습
• y: 소비
• time : 정책 전후 (ex. 근로장려세제 도입 전후) 더미변수
• treat : 정책에 영향을 받는 그룹과 받지 않는 그룹을 구분
• lambda : 또 다른 더미 (ex. 대도시 vs 농촌)
ddd <- haven::read_dta('ddd.dta')
model1 <- lm(y~treat + time + treat*time, data = ddd, subset = lambda == 1)
model2 <- lm(y~treat + time + treat*time, data = ddd, subset = lambda == 0)
model3 <- lm(y~treat + time + lambda + treat*time + treat*lambda + treat*time*lambda, data = ddd)
stargazer::stargazer(model1, model2, model3, column.labels = c("DID1(lambda = 1)", "DID2(lambda = 0)", "DDD"),
type="text", keep.stat = c("n", "adj.rsq"), out = "DDD결과.doc")

• 해석
↪ DID1 : 3.209*** : 대도시 지역에서는 정책효과로 인해 영향을 받는 그룹이 그렇지 않은 그룹보다 소비가 3.209 정도 더 많다.
↪ DID2 : -0.143 : 농촌 지역에는 정책효과로 인해 영향을 받는 그룹이 그렇지 않은 그룹보다 소비가 -0.143 정도 더 낮다. (통계적으로 유의한 수치는 아님)
↪ DDD : 3.352*** = (3.209) - (-0.143) = DID1 과 DID2 추정 (treat x time) 차이
'1️⃣ AI•DS > ⚾ 계량경제•통계' 카테고리의 다른 글
| 계량경제학 강의_한치록_단순회귀 2.5~2.7장 (1) | 2023.05.10 |
|---|---|
| 계량경제학 스터디 Lecture 2. Regression (1) | 2023.05.10 |
| 계량경제학 강의_한치록_단순회귀 1장~2.4장 (0) | 2023.05.09 |
| 계량경제학 스터디 Lecture 1. Introduction (0) | 2023.05.08 |
| 계량경제학 스터디 CH11,12,13,14,15정리 (0) | 2023.04.09 |


댓글