1️⃣ 6강 복습
🔹 Main Topic : Graph Neural Networks
① 복습 : Node embedding
• 그래프에서 유사한 노드들이 함수 f 를 거쳐 d 차원으로 임베딩 되었을 때, 임베딩 공간 내에서 가까이 위치하도록 만드는 것


↪ Encoder : 각 노드를 저차원 벡터로 매핑
↪ Similarity function : 원래 그래프 내에서의 노드 간 유사도와 임베딩 공간에서 노드 벡터의 내적값이 유사하도록 만드는 함수
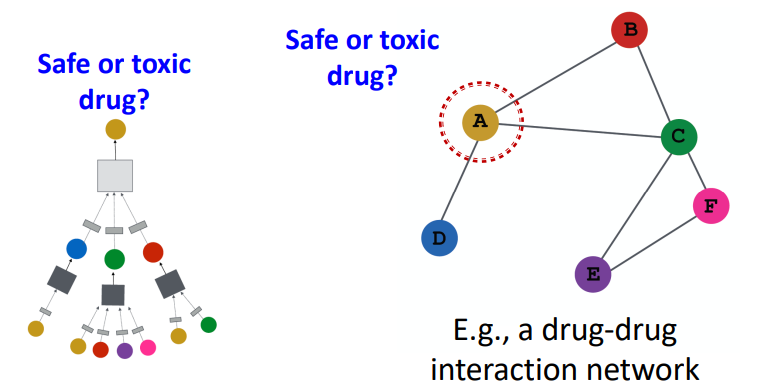
• Shallow Encoding (embedding lookup) : 임베딩 행렬에서 노드의 임베딩 벡터를 각 칼럼에 담아, 단순히 벡터를 읽어오는 방식 → 🤨 노드 간에 파라미터를 공유하지 않기 때문에 노드의 개수가 증가할 수록 행렬의 크기가 계속 늘어나게 되며, 훈련 과정에서 보지 못한 노드는 임베딩을 생성할 수 없다. 또한 노드의 feature 정보는 포함되지 않는다.
② GNN
• 단순히 look up 하는 임베딩 방식의 한계를 극복하고자 다중 레이어로 구성된 encoder 를 활용
• Task : Node classification, Link prediction, Community detection, network similarity

👀 그러나 문제가 있다
↪ 네트워크는 임의의 크기를 가지고 있으며 복잡한 topological 구조를 가진다.
↪ 특정한 기준점이나 정해진 순서가 없다.
↪ 동적이며 multimodal feature 를 가진다.

🔹 Deep learning for Graphs
① Notation

• V : 노드집합
• A : 인접행렬 (연결 여부를 나타내는 방식 : binary)
• X : node feature 행렬
• N(v) : v 의 이웃노드 집합
② Convolutional Neworks
※ 정리 참고 : https://manywisdom-career.tistory.com/71
[인공지능] GNN
Summary ✨ Idea for deep learning for graphs ◾ Multiple layers of embedding transformation ◾ At every layer, use the embedding at previous layer as the input ◾ ⭐⭐ Aggregation of neighbors ✨ Graph convolutional network ◾ Mean aggregaton → p
manywisdom-career.tistory.com
• Convolutional 연산 : Sliding window 를 통해 얻은 정보를 모두 더해 output 을 도출
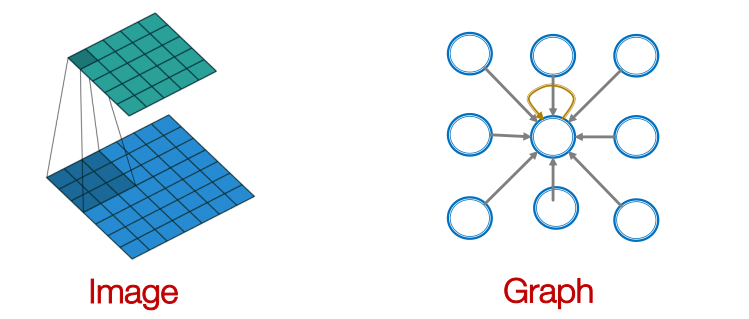
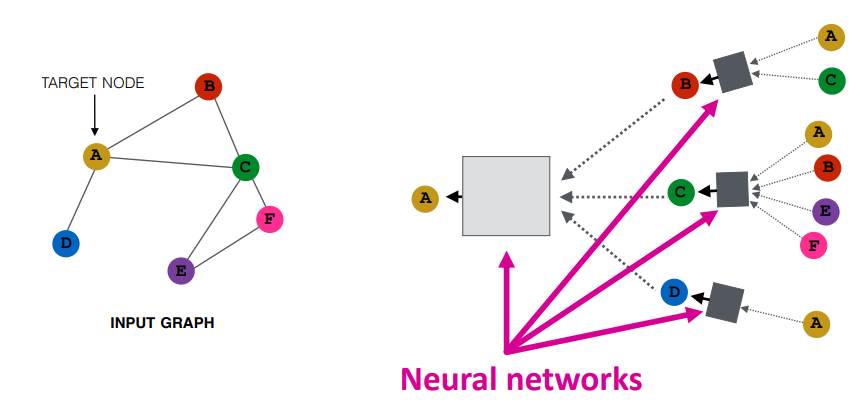
• 이웃노드의 정보를 변환하고 결합하여 특정 노드를 임베딩한다.
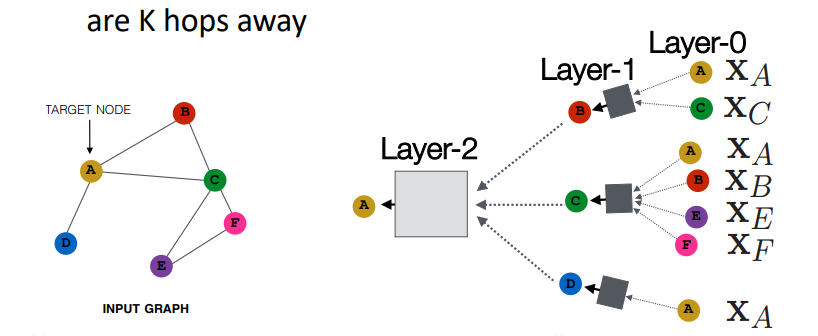
• Layer-k embedding : k hop 만큼의 이웃노드의 정보를 가져와 임베딩 했다는 의미
• Neighborhood aggregation : 이웃노드로부터 정보를 집계하는 방식은 네트워크마다 다르다. 이때 집계하는 함수는 permutation invariant (입력 데이터의 순서에 영향을 받지 않는) 함수여야 하며, 기본적으로 많이 사용하는 방식은 정보를 average (평균) 하는 기법을 많이 사용한다.
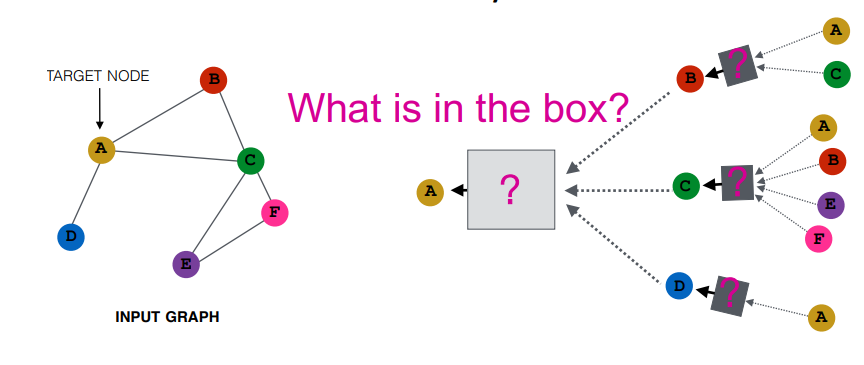
③ 수학 공식


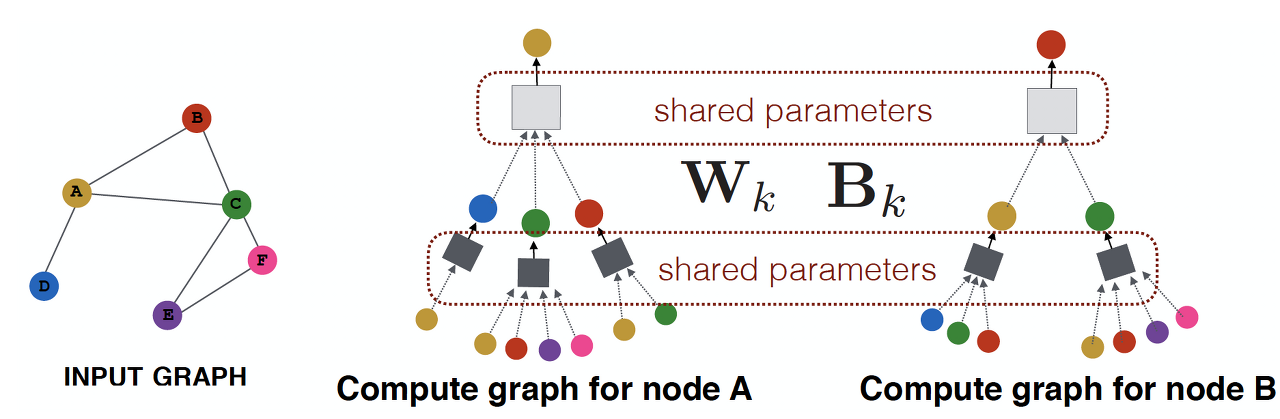
👉 Wk, Bk : 학습할 가중치 파라미터로 Wk 는 이웃노드들로부터 집계한 정보에 대해 부여하는 가중치이고 Bk 는 현재 계산중인 노드의 이전 레이어에서의 (자기 자신의) 임베딩 정보에 대한 가중치이다. 이 두 값을 통해 이웃정보에 집중할지, 자기 자신의 값의 변환에 집중할지 결정한다. 이 파라미터는 특정 노드를 임베딩할 때 모든 노드에 대해 공유되는 값이기 때문에, 새로운 노드나 그래프에 대해서도 일반화시킬 수 있다.
④ GNN 훈련방식
• Goal : Node embedding Zv
• input : Graph
↪ Unsupervised setting : 그래프 구조를 supervision으로 사용
↪ Supervised setting [Node classification] : node label y 에 대해, 실제 라벨과 노드 임베딩 결과값 기반의 예측 라벨값 사이의 loss function 을 정의하여 훈련을 진행
2️⃣ 코드리뷰
https://colab.research.google.com/drive/1DsdBei9OSz4yRZ-KIGEU6iaHflTTRGY-?usp=sharing
cs224w 6강 복습과제.ipynb
Colaboratory notebook
colab.research.google.com
🔹 Dataset
• Cora dataset
- 다른 논문을 인용하는 연결구조를 표현한 것 : Citation Network
- 2708 개의 과학 분야 논문 출간에 대한 데이터로, 각 논문은 7개 class 분류 중 하나에 속한다.
- 5429 개의 링크 (엣지)로 구성되어 있다.
- 각 노드는 단어사전을 기반으로 0 (해당 단어가 존재하지 않음) 혹은 1 (해당 단어가 존재함) binary 값을 가진 단어벡터로 이루어져 있다. 단어사전은 1433개의 단어로 구성되어 있다 👉 node_features = 1433
- Main Task : node classification (CrossEntropyLoss - 다중분류)

① Data Normalization
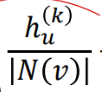
→ GCN 과정에서 노드 차수로 정규화 하는 과정
dataset = Planetoid("/tmp/Cora", name="Cora")
print(f'정규화 없이 행렬의 각 행의 값 합산 결과 : {dataset[0].x.sum(dim=-1)}')
dataset = Planetoid("/tmp/Cora", name="Cora", transform = T.NormalizeFeatures()) #🐾
print(f'정규화를 적용해 행렬의 각 행의 값 합산 결과 : {dataset[0].x.sum(dim=-1)}') # dim = axis
② GCN model architecture
class GCN(torch.nn.Module) :
def __init__(self, num_node_features : int, num_classes : int, hidden_dim : int = 16, dropout_rate : float = 0.5) :
super().__init__()
self.dropout1 = torch.nn.Dropout(dropout_rate)
self.conv1 = GCNConv(num_node_features, hidden_dim)
# (conv1): GCNConv(1433, 16)
self.relu = torch.nn.ReLU(inplace = True)
self.dropout2 = torch.nn.Dropout(dropout_rate)
self.conv2 = GCNConv(hidden_dim, num_classes)
# (conv2): GCNConv(16, 7)
def forward(self, x : Tensor, edge_index : Tensor) -> torch.Tensor :
x = self.dropout1(x)
x = self.conv1(x, edge_index)
x = self.relu(x)
x = self.dropout2(x)
x = self.conv2(x, edge_index)
return x
③ Training and Evaluation
def train_step(model : torch.nn.Module, data : Data, optimizer : torch.optim.Optimizer,loss_fn : LossFn) :
Tuple[float, float]
model.train()
optimizer.zero_grad()
mask = data.train_mask
logits = model(data.x, data.edge_index)[mask]
preds = logits.argmax(dim=1)
y = data.y[mask]
loss = loss_fn(logits, y)
acc = (preds == y).sum().item() / y.numel() #✔ numel : torch tensor 크기를 반환
loss.backward()
optimizer.step()
return loss.item(), acc
@torch.no_grad()
def eval_step(model : torch.nn.Module, data : Data, loss_fn : LossFn, stage : Stage) :
model.eval()
mask = getattr(data, f'{stage}_mask')
logits = model(data.x, data.edge_index)[mask]
preds = logits.argmax(dim=1)
y = data.y[mask]
loss = loss_fn(logits, y)
acc = (preds == y).sum().item() / y.numel() #✔
return loss.item(),acc
• optimizer.zero_grad() : 파라미터 초기화
• preds = logits.argmax(dim=1) : 예측값 인덱스 반환 👉 7개의 class 인덱스 중 하나를 반환

④ Train function define and Training
SEED = 42
MAX_EPOCHS = 200
LEARNING_RATE = 0.01
WEIGHT_DECAY = 5e-4
EARLY_STOPPING = 10
def train(model : torch.nn.Module, data : Data, optimizer : torch.optim.Optimizer,
loss_fn : LossFn = torch.nn.CrossEntropyLoss(), max_epochs : int = 200,
early_stopping : int = 10, print_interval : int = 20, verbose : bool = True) :
history = {'loss':[],'val_loss' : [], 'acc' : [], 'val_acc' : []}
for epoch in range(max_epochs) :
loss, acc = train_step(model, data, optimizer, loss_fn)
val_loss, val_acc = eval_step(model, data, loss_fn, 'val')
history['loss'].append(loss)
history['acc'].append(acc)
history["val_loss"].append(val_loss)
history['val_acc'].append(val_acc)
if epoch > early_stopping and val_loss > np.mean(history['val_loss'][-(early_stopping +1) : -1]) :
if verbose :
print('\n ealry stopping ...')
break
if verbose and epoch % print_interval == 0 :
print(f'\nEpoch : {epoch} \n----------- ')
print(f'Train loss : {loss:.4f} | Train acc : {acc:.4f}')
print(f'Val loss : {val_loss : .4f} | Val acc : {val_acc : .4f}')
test_loss, test_acc = eval_step(model, data, loss_fn, "test")
if verbose:
print(f"\nEpoch: {epoch}\n----------")
print(f"Train loss: {loss:.4f} | Train acc: {acc:.4f}")
print(f" Val loss: {val_loss:.4f} | Val acc: {val_acc:.4f}")
print(f" Test loss: {test_loss:.4f} | Test acc: {test_acc:.4f}")
return history
• loss function 정의 및 하이퍼파라미터 정의 (max_epoch, early stopping)
• accuracy, loss 출력 함수 정의
torch.manual_seed(SEED)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = GCN(dataset.num_node_features, dataset.num_classes).to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr = LEARNING_RATE, weight_decay = WEIGHT_DECAY)
history = train(model, data, optimizer, max_epochs = MAX_EPOCHS, early_stopping = EARLY_STOPPING)
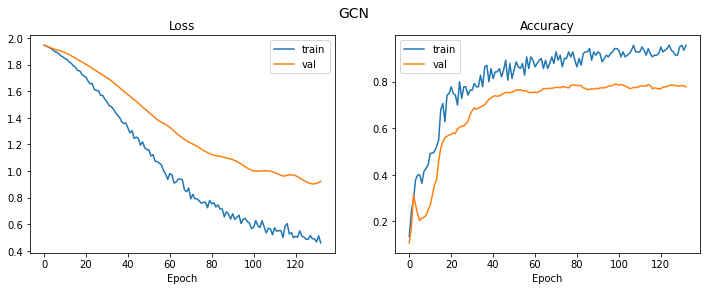
plt.figure(figsize = (12,4))
plot_history(history, 'GCN')
'1️⃣ AI•DS > 📘 GNN' 카테고리의 다른 글
| [cs224w] Frequent Subgraph Mining with GNNs (0) | 2023.01.27 |
|---|---|
| [cs224w] Theory of Graph Neural Networks (0) | 2023.01.06 |
| [CS224W] Message Passing and Node classification (0) | 2022.11.17 |
| [CS224W] PageRank (0) | 2022.11.02 |
| [CS224W] 1강 Machine Learning With Graphs (0) | 2022.10.11 |




댓글