DeepAR: Mastering Time-Series Forecasting with Deep Learning
Amazon’s autoregressive deep network
towardsdatascience.com
👀 Summary
▸ DeepAR : Amazon's autoregressive deep network (work on multiple time series)
• first successful model to combine Deep learning with traditional Probabilistic Forecasting
https://arxiv.org/pdf/1704.04110.pdf
🔹 다변량 시계열
• 각 시간 단위마다 여러 개의 값을 가지는 데이터. 하나의 변수가 아닌 2개 이상의 변수의 시계열을 이용해 각 변수간 시계열에 따라 영향을 미치는 정도를 파악.
• 단변량 시계열과 다변량 시계열의 차이는, 예측을 위해 사용하는 시계열 변수를 X라고 한다면, X 변수의 시계열 수에 있다. X의 시계열이 1개이면 단변량 시계열이고 2개 이상이면 다변량 시계열이다. 예측하고자 하는 변수와 상관없이 X의 개수가 중요하다. 단일 시계열의 과거값 (X_t-1) 을 이용해 그 시계열의 미래값 (X_t) 를 예측하는 분석을 단변량 시계열 분석이라 한다. 예측하고자 하는 변수는 무조건 1개이다.
https://m.blog.naver.com/2sat/221168219214
[시계열 분석의 기초] 시계열 모형의 종류-2
[시계열 분석의 기초] 시계열 모형의 종류-2 (1) 투입된 변수의 개수에 따라 &nb...
blog.naver.com
• Multiple time series VS Multivariate time series
↪ 예시로 쉽게 설명하자면, 만약 여러 집단의 환자들의 체중을 모니터링 하는 상황이라면, 각 환자마다 매일 체중 값을 측정하게 되면서 각 환자별로 여러 개의 시계열 데이터가 얻어지게 될 것인데, 이것이 바로 Multiple time series 이다. 반면, 특정 환자 한명의 건강상태를 모니터링 하는 상황이라면, 환자의 매일 체중, 체온, 혈압, 콜레스테롤 수치 등을 측정하고 고려해야 하는데 이것이 바로 Multivariate time series 이다.
🔹 DeepAR
➰ DeepAR 의 특징
• Multiple time series 를 지원하는 모델로, global 한 특성을 학습해 예측 성능을 높인다.
• Extra covariates (features) 를 지원한다. 가령 기온을 예측한다고 했을 때, 습도, 기압 등의 변수를 추가해서 예측을 진행할 수 있다.
• 단일한 예측값을 결과로 내뱉지 않고, Probabilistic output 을 결과로 가져온다.
• 여러 개의 시계열을 가지고 학습을 진행하기 때문에, 각 시계열 간의 유사성을 공유하여, 이전에 학습되지 않은 데이터도 예측을 진행할 수 있다.
➰ LSTM in Deep AR
• DeepAR 은 Probabilistic 한 결과를 내뱉기 위해 LSTM 네트워크 구조를 사용한다. LSTM 를 직접적으로 사용하기 보단, 가우시안 가능도 함수를 매개변수화 (parameterize) 하기 위해 사용한다. 즉, 가우시안 함수의 θ = (μ, σ) 파라미터를 추정하기 위해 사용한다.
• 자연어처리 분야에서 Transformer 구조가 지배적이나 시계열 분야, local temporal data (시간 데이터) 를 다룰 땐, LSTM 의 성능이 훨씬 더 뛰어나다.

➰ DeepAR 의 구조 in traning
↪ 시계열 i 에 대해 특정 time step t 에 있다고 가정해보자.
(1) LSTM cell 은 feature 변수 x(i,t) 와 목적 변수 z(i, t-1) 을 입력으로 받는다. 또한 hidden state 인 h(i, t-1) 을 이전 time step 결과로부터 전달 받는다.
(2) LSTM cell 은 h(i,t) 를 결과로 내뱉고 다음 time step 에 이 값을 전달한다.
(3) h(i,t) 를 계산할 때, μ, σ 도 계산되는데, 이는 가우시안 가능도 함수 p(y_i|θ_i)= l(z_i,t|Θι,t) 의 파라미터 값이 된다. 모델은 목적 변수 z(i,t) 가 실제 정답값과 가까울 수 있도록 하는 모수를 찾기 위해 학습을 진행한다.
↪ DeepAR 은 각 time 마다 단일한 data point 을 대상으로 학습을 진행하기 때문에 autoregressive (AR, 자기회귀모델 : 변수의 과거 값의 선형 조합을 이용해 관심있는 변수를 예측) 라고 부른다.
➰ DeepAR 의 구조 in inference
↪ inference 단계에서는 이전 단계의 predicted output (training 을 통해 학습된 모델로부터 얻어진 sample) 을 다음 단계의 input 으로 활용한다는 점에서 차이가 존재한다.
➰ Gaussian Likelihood
• MLE 목표 : sample data 를 더 잘 설명해줄 수 있는 확률분포의 최적의 파라미터 값을 찾는 방법
• 가우시안 (정규) 분포 는 μ 와 σ 를 모수로 갖는 분포이다.
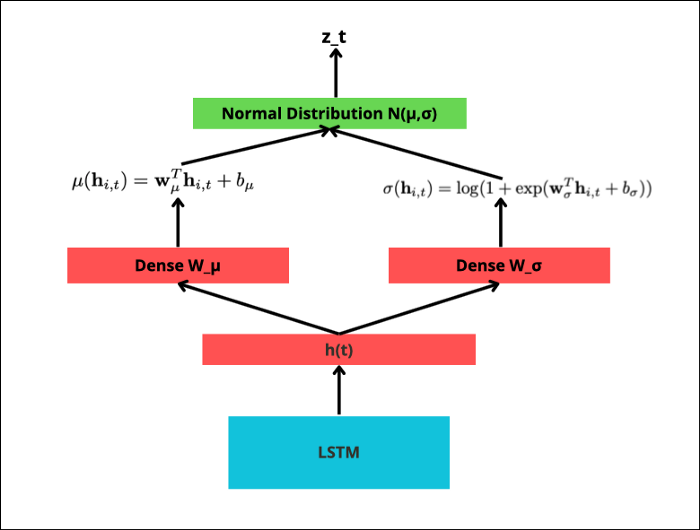
• 모수 추정 단계는 다음과 같다. LSTM cell 이 hidden state h(t) 를 계산한 후, μ 를 계산하기 위해 dense layer W_μ 를 통과한다. 마찬가지로 σ에 대해서도 dense layer W_ σ 를 통과한다. 이를 통해 얻은 모수 값으로 가우시안 분포를 생성하여 sample 을 만든다. 이 sample 값이 실제 정답 관측값 z(i,t) 와 얼마다 유사한지 계산하면서 training 이 이어진다. LSTM cell 의 가중치와 2개의 dense layer W_μ , W_ σ 는 역전파를 통해 값이 업데이트 된다. inference 단계에서는 z(i,t) 를 사용하지 않음에 주의하자.
➰ Auto Scaling
• 여러 개의 이질적인 time series 를 다루는 것은 까다롭다. 가령 상품 매출 데이터라고 한다면, 특정 상품의 매출 단위는 천원대 일 수 있고, 다른 상품의 매출 단위는 몇십억 단위일 수도 있다. 이러한 단위의 차이는 모델이 학습할 때 방해가 될 수 있다. 이를 방지하기 위해 DeepAR 은 auto-scaling 메커니즘을 도입한다. 각 time step t 마다 결과로 도출되는 z(i,t) 를 v(i) 로 rescaling 해준다.
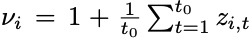
• DeepAR 은 auto-scaling 으로 자동적으로 정규화를 해주지만, 입력으로 넣기 전에 먼저 직접 정규화를 해주면 모델의 성능이 훨씬 향상될 수 있다는 점을 참고하자.
➰ 장단점
• DeepAR 은 ARIMA 와 같은 전통적인 시계열 모형보다 성능이 뛰어나며, 정상성 변환과 같은 추가적인 feature preprocessing 과정이 필요 없다는 장점이 있다.
• DeepAR 모델이 등장하고 나서, Temporal Fusion Transformer (TFT) 같은 모델들이 등장했는데, 이 둘의 차이점에 대해 알아보자.
↪ Multiple time series : DeepAR 은 각 시계열 임베딩을 분리해 계산하고 이를 LSTM 의 feature 로 활용해 서로다른 시계열 데이터를 구별할 수 있다. TFT 도 LSTM 구조를 사용하지만, TFT 는 임베딩을 LSTM 의 초기 hidden state h_0 을 구성하기 위해 활용한다는 점에서 차이가 존재한다.
↪ Type of Forecasting : TFT 는 AR 모델이 아니다. TFT 는 multi-horizon forecasing model 이다. 따라서 AR 모델처럼 one by one 으로 output 을 제공하지 않고 한번에 prediction 값을 내놓는다.
📚 Vocab
• natively : 기본적으로
• milestone : 중요한 단계
• intervals : 간격, 사이, 음정
• decisively : 결정적으로
• versatile : 변하기 쉬운
'🎸 기타 > 🎃 영어' 카테고리의 다른 글
| [Daily English] Nostalgic cartoon characters fuel retailers in recession (0) | 2023.02.10 |
|---|---|
| [Daily English] As AI war rages, Korea seeks a place among giants (0) | 2023.02.09 |
| [Blog] Time Series Transformation Package : scalecast (0) | 2023.01.27 |
| [Blog] ChatGPT 와 데이터사이언스 (0) | 2023.01.26 |
| [2023] 영어 공부 계획 (0) | 2023.01.25 |



댓글