👀 LLM을 활용한 실전 AI 애플리케이션 개발 책 스터디 정리 자료
(저작권 문제시 잠금하겠습니다~!)
▶️ 깃헙코드
1. 허깅페이스 트랜스포머란
◯ Transformer 라이브러리
• 공통된 인터페이스로 트랜스포머 모델을 활용할 수 있도록 지원하여 딥러닝 분야의 핵심 라이브러리 중 하나 (오픈소스 라이브러리)
• 모델과 토크나이저 → transformer 라이브러리 : AutoTokenizer, AutoModel
• 데이터셋 → datasets 라이브러리
from transformers import AutoTokenizer, AutoModel
text = "What is Huggingface Transformers?"
# BERT 모델 활용
bert_model = AutoModel.from_pretrained("bert-base-uncased")
bert_tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
encoded_input = bert_tokenizer(text, return_tensors='pt')
bert_output = bert_model(**encoded_input)
# GPT-2 모델 활용
gpt_model = AutoModel.from_pretrained('gpt2')
gpt_tokenizer = AutoTokenizer.from_pretrained('gpt2')
encoded_input = gpt_tokenizer(text, return_tensors='pt')
gpt_output = gpt_model(**encoded_input)
• output 은 임베딩된 숫자 벡터 결과
2. 허깅페이스 허브 탐색하기
◯ 허깅페이스 허브
Hugging Face – The AI community building the future.
huggingface.co
• 다양한 사전 학습 모델과 데이터셋을 탐색하고 쉽게 불러와 사용할 수 있도록 제공하는 온라인 플랫폼
• Space : 자신의 모델 데모를 제공하고 다른 사람의 모델을 사용해볼 수 있는 기능
◯ 모델허브
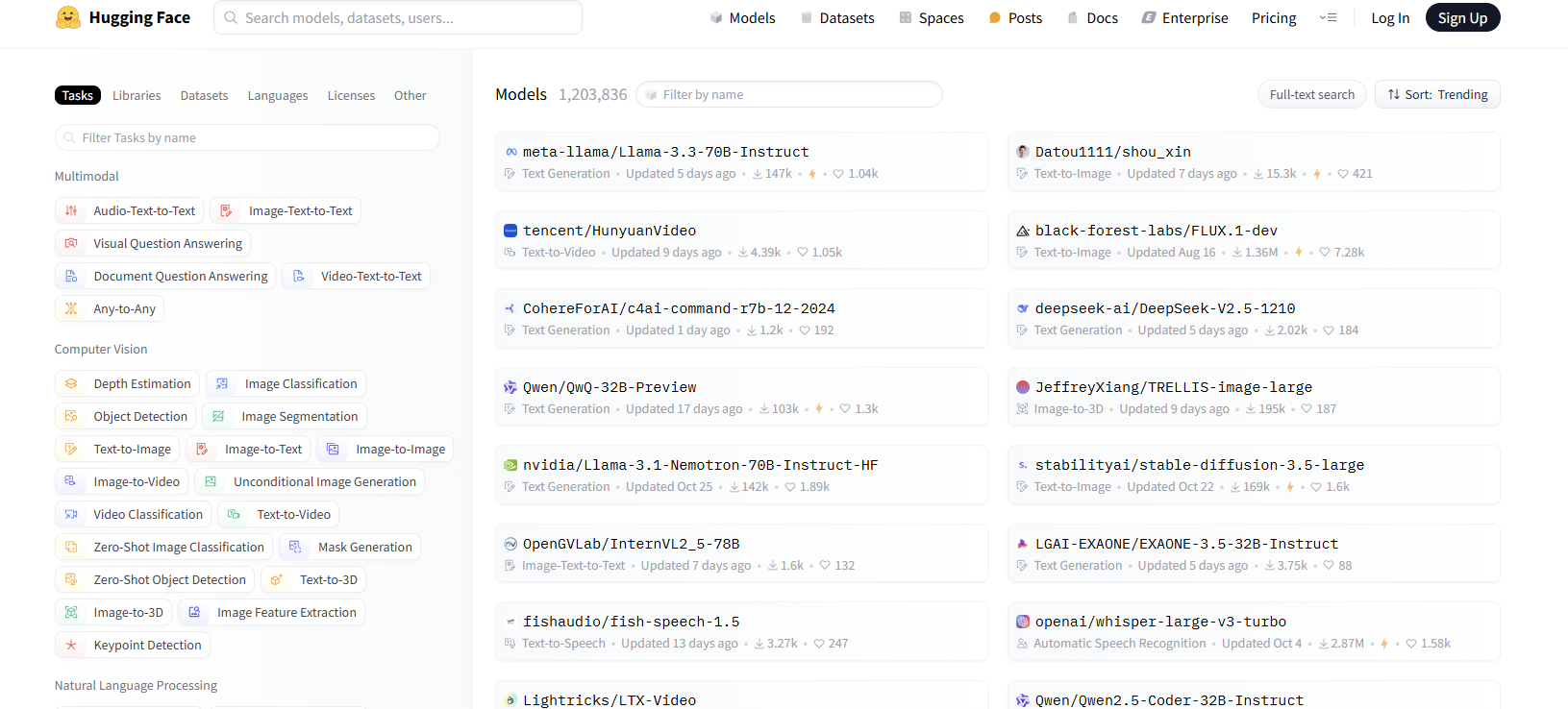
• 어떤 작업에 사용하는지, 어떤 언어로 학습된 모델인지 다양한 기준으로 모델을 분류. NLP, CV, Audio, Multimodal 등 다양한 작업 분야의 모델을 제공한다.

• 모델의 이름 및 요약 정보, 모델 설명 카드, 모델 트렌드, 모델 추론 테스트 등을 확인해볼 수 있다.
◯ 데이터셋허브

• 데이터셋크기, 유형 등이 추가되어있다.

• KLUE : 한국어 언어 이해 평가의 약자로 텍스트 분류, 기계 독해, 문장 유사도 판단 등 다양한 작업에서 모델의 성능을 평가하기 위해 개발된 벤치마크 데이터셋이다. MRC데이터, YNAT 데이터 등 8개 데이터가 포함되어 있다. 학습용/검증용/테스트용 데이터셋으로 구분되어 있다.
◯ 스페이스

• 모델 데모를 간편하게 공개할 수 있는 기능이다. 스페이스를 사용하면 별도의 복잡한 웹페이지 개발 없이 모델 데모를 바로 공유할 수 있다.

• 객체인식 모델 Yolo v9 화면으로, 왼쪽에 모델 추론에 사용할 이미지를 업로드할 수 있는 영역과 사용할 모델의 종류, 추론에 사용할 모델 설정을 선택할 수 있는 영역이 있다.

◯ LLM 리더보드
Open LLM Leaderboard - a Hugging Face Space by open-llm-leaderboard
huggingface.co
Open Ko-LLM Leaderboard - a Hugging Face Space by upstage
huggingface.co

• 표에 나타날 벤치마크 항목 리스트 : ko-GPQA, Average 등
• 모델 학습 방식 : pretrained, fine-tuned 등
• 모델 크기, 파라미터 데이터 형식 등
3. 허깅페이스 라이브러리 사용법 익히기
◯ 바디와 헤드
• 허깅페이스는 모델을 Body와 Head로 구분한다. 같은 Body를 사용하면서, 다른 작업에 사용할 수 있도록 만들기 위해서이다.
• 가령 같은 BERT body를 사용하지만, 텍스트 분류 헤드, 토큰 분류 헤드 등 작업 종류에 따라 서로 다른 헤드를 사용할 수 있다.
• 모델 불러오기
from transformers import AutoModel
model_id = 'klue/roberta-base'
model = AutoModel.from_pretrained(model_id)
• 분류 헤드가 포함된 모델 불러오기
from transformers import AutoModelForSequenceClassification
model_id = 'SamLowe/roberta-base-go_emotions'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)
• 분류 헤드가 랜덤으로 초기화된 모델 불러오기
from transformers import AutoModelForSequenceClassification
model_id = 'klue/roberta-base'
classification_model = AutoModelForSequenceClassification.from_pretrained(model_id)
◯ 토크나이저 활용하기
• 텍스트를 토큰 단위로 나누고 각 토큰을 대응하는 토큰 아이디로 변환, 필요한 경우 특수 토큰을 추가
• 토크나이저도 학습 데이터를 통해 어휘 사전을 구축하므로 모델과 함께 저장하는 것이 일반적
• 모델과 토크나이저를 불러오는 경우 동일한 모델 아이디를 설정
from transformers import AutoTokenizer
model_id = 'klue/roberta-base'
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenized = tokenizer("토크나이저는 텍스트를 토큰 단위로 나눈다")
print(tokenized)
# {'input_ids': [0, 9157, 7461, 2190, 2259, 8509, 2138, 1793, 2855, 5385, 2200, 20950, 2],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
print(tokenizer.convert_ids_to_tokens(tokenized['input_ids']))
# ['[CLS]', '토크', '##나이', '##저', '##는', '텍스트', '##를', '토', '##큰', '단위', '##로', '나눈다', '[SEP]']
print(tokenizer.decode(tokenized['input_ids']))
# [CLS] 토크나이저는 텍스트를 토큰 단위로 나눈다 [SEP]
print(tokenizer.decode(tokenized['input_ids'], skip_special_tokens=True))
# 토크나이저는 텍스트를 토큰 단위로 나눈다
◯ 데이터셋 활용하기
from datasets import load_dataset
klue_mrc_dataset = load_dataset('klue', 'mrc')
4. 모델 학습하기
◯ 연합뉴스 데이터 실습
• 한국어 기사 제목을 바탕으로 기사의 카테고리를 분류하는 텍스트 분류 모델
• 트레이너 API를 사용해 학습
1) 데이터 가져오기
from datasets import load_dataset
klue_tc_train = load_dataset('klue', 'ynat', split='train')
klue_tc_eval = load_dataset('klue', 'ynat', split='validation')
klue_tc_trainklue_tc_train.features['label'].names
# ['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치']
2) 데이터 준비
train_dataset = klue_tc_train.train_test_split(test_size=10000, shuffle=True, seed=42)['test']
dataset = klue_tc_eval.train_test_split(test_size=1000, shuffle=True, seed=42)
test_dataset = dataset['test']
valid_dataset = dataset['train'].train_test_split(test_size=1000, shuffle=True, seed=42)['test']
3) Trainer를 사용한 학습
import torch
import numpy as np
from transformers import (
Trainer,
TrainingArguments,
AutoModelForSequenceClassification,
AutoTokenizer
)
# 1) 준비
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", truncation=True)
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
train_dataset = train_dataset.map(tokenize_function, batched=True)
valid_dataset = valid_dataset.map(tokenize_function, batched=True)
test_dataset = test_dataset.map(tokenize_function, batched=True)
# 2) 학습 파라미터와 평가함수 정의
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
evaluation_strategy="epoch",
learning_rate=5e-5,
push_to_hub=False
)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy": (predictions == labels).mean()}
# 3) 학습 진행
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.evaluate(test_dataset) # 정확도 0.84
• Trainer API를 사용하지 않는다면 torch로 구현 해야 함 (모델 구현 코드 동작과정에 대한 이해도가 높아지긴 함)
5. 모델 추론하기
◯ 파이프라인을 활용한 추론
• 모델을 활용하기 쉽도록 추상화한 파이프라인을 활용하는 방법과 직접 모델과 토크나이저를 불러와 활용하는 방법 존재
• 파이프라인 활용 추론
from transformers import pipeline
model_id = "본인의 아이디 입력/roberta-base-klue-ynat-classification"
model_pipeline = pipeline("text-classification", model=model_id)
model_pipeline(dataset["title"][:5])
• Custom pipeline 정의해서 구현할 수도 있긴 함 (class , def 활용)
'1️⃣ AI•DS > 🌏 LLM' 카테고리의 다른 글
| [책 스터디] 2. 트랜스포머 아키텍처 살펴보기 (0) | 2024.12.11 |
|---|---|
| [책 스터디] 13.LLM 운영하기 (0) | 2024.12.03 |
| [책 스터디] 1. LLM 기초 : sLLM, RAG (0) | 2024.12.01 |
댓글