Tabnet
0️⃣ Tabnet
Tree 기반 모델의 변수 선택 특징을 네트워크 구조에 반영한 딥러닝 모델
1️⃣ 배경
✔ 기존 딥러닝 모델은 이미지, 음성, 언어와 같은 비정형 데이터에만 적용되었음
✔ 정형 데이터 Tabular Data 는 최근까지도 kaggle 같은 여러 대회에서 XGBoost, LightGBM, CatBoost와같은 Tree기반의 앙상블 모델을 주로 사용했음
👀 딥러닝의 점진적 학습 특성 + 사전학습 가능성은 새로운 분석 기회를 도출
👀 트리기반 모델 + 신경망 모델 구조 의 장점을 모두 갖는 Tabnet 을 제안 👉 feature selection & engineering + 모델 해석력을 갖춘 신경망 모델
2️⃣ Tabnet 논문 리뷰
🧐 앙상블 모델이 딥러닝 모델보다 우수한 이유
(1) 정형데이터는 대략적인 초평면 경계를 가지는 manifold 이고, 부스팅 모델들은 이러한 manifold 에서 결정을 할 때 더 효율적으로 작동한다. 이미지와 언어같은 비정형 데이터는 정형 데이터에 비해 상대적으로 같은 원천에서 발생된 데이터이므로 대략적인 초평면 경계가 뚜렷하지 않다.
(2) 트리 기반의 모델들이 학습이 빠르고 쉽게 개발이 가능하다.
(3) 트리기반의 모델들은 높은 해석력을 가진다. 트리기반 모델의 특성 상 변수 중요도를 구할 수 있어 딥러닝 모델에 비해 상대적으로 해석에 용이하다.
(4) CNN, MLP 같은 딥러닝 모델은 지나치게 Overparametrized 되어서 정형 데이터 내 매니폴드에서 일반화된 해결책을 찾는데 어려움을 발생시킬 수 있다.
🤔 정형 데이터에 딥러닝 모델을 적용하는 것도 나쁘지 않아
(1) 매우 많은 훈련 데이터 셋에 대해 성능을 높일 수 있다.
(2) 정형 데이터와 이미지(텍스트) 등 다른 데이터 타입을 학습에 함께 사용 가능하다. (multi - modal Learning)
(3) 트리 기반 알고리즘에서 필수적인 Feature engineering 같은 단계를 크게 요구하지 않는다.
(4) 딥러닝 모델은 Streaming 데이터로부터 학습이 용이하다. (지속적인 학습)
😎 Tabnet 은 말이야
(1) Feature 의 전처리 없이 원 데이터를 입력으로 사용할 수 있고, 경사 하강법 기반 최적화 방식을 사용해 End-to-End learning 을 가능하게 한다.
(2) 성능과 해석력 향상을 위해 Sequential attention mechanism 을 통해 사용할 feature 를 선택한다.
(3) 기존 정형 분류, 회귀 모델보다 성능의 우수성을 가지며 해석력에서 입력 피처의 중요도를 파악할 수 있고, 피처의 결합을 시각화하여 확인해볼 수 있으며, 입력 피처들이 얼마나 자주 결합되는지에 대한 해석력을 제시한다.
3️⃣ Tabnet 알고리즘 구조
📌 개요
- 순차적인 어텐션을 사용해 각 의사결정 단계에서 추론할 피처를 선택해가면서 피드백을 주며 학습해나아가는 구조이다 👉 더 나은 해석 능력과 학습이 가능 + 숨겨진 특징을 예측하기 위해 사전 비지도 학습 (Self-supervised Learning) 을 사용 가능
- tabnet 의 feature selection 은 특정 피처만 선택하는 것이 아니라, 각 피처에 가중치를 부여하는 것이다. Sparse Feature selection
- Tabnet 의 구조는 Encoder - Decoder 를 거쳐 결측값을 예측할 수 있는 Autoencoder 구조이기 때문에 데이터셋에 결측값이 있어도 별도의 전처리 없이 값들을 채울 수 있다.
👀 Encoder
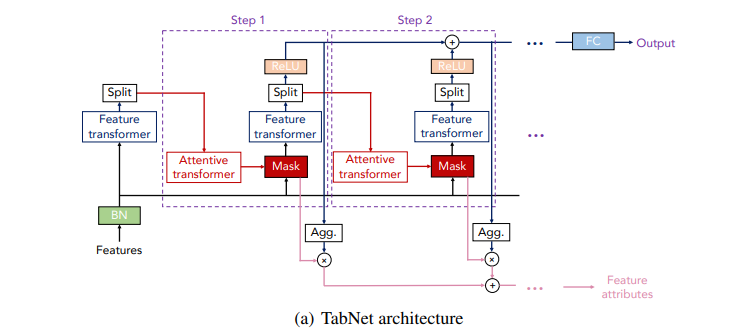
- input 을 시작으로 각 의사결정 단계 Step 로 구성되어 있고, 단계마다 Feature transformer, Attentive transformer, Feature masking 으로 구성되어 있다.
- feature transformer 와 attentive transformer 블록을 통과하여 최적의 mask 를 학습한다.
- 다음 decision step 으로 이전의 decision 에 대한 정보들이 전달되는 과정이 트리기반 부스팅 모델의 잔차를 줄여나가는 부분과 유사하다.

- feature masking 은 local 해석에 사용되며 전체를 취합하여 global 한 해석을 할 수 있게 된다.
👀 Decoder

- 각 step 에서 feature transformer 블록으로 구성된다.
- 일반적인 학습에선 Decoder 를 사용하진 않지만 Self-Supervised (Semi-supervised) 학습 진행시 인코더 다음에 붙여져 기존 결측값 보완 및 표현 학습을 진행한다.
📌 세부 구조
🤨 Tabnet 아키텍쳐를 따라가며 위의 (a) 그림에 제시된 각 박스 부분에 대해 설명하고자 한다.
📕 Feature transformer 💨 임베딩을 수행
- 선택된 피처로 정확히 예측하기 위한 임베딩 기능


- 입력 Feature : numerical 피처는 그대로 사용하고, categorical 피처는 임베딩 레이어를 구성해준다 👉 모델 생성시 cat_idxs, cat_dims, cat_emb_dim 인자와 관련됨
- BatchNorm (BN) : 정형 데이터를 분석할 때 보통 Min-Max scaler, Standard Scaler 를 수행하는데, 이러한 정규화 과정을 BatchNorm 레이어로 대체하여 사용했다.
- batch 를 분할한 nano batch 사용으로 잡음을 추가해 지역 최적화를 예방한다.

- Feature transformer : FC-BN-GLU 를 4번 반복한 구조
- FC : fully connected layer 전결합층
- GLU : Gated Linear unit, 선형 매핑을 통해 나온 결과물을 반으로 나누어 Residual connection, sigmoidfunction 을 거친 후 element-wise 로 계산하는 구조. 각 정보 별 정보의 양을 얼마나 흘려보낼지 결정하기 위해 비선형 함수를 사용한다.

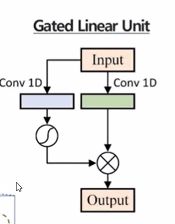
- 앞의 2개 네트워크 묶음은 모든 파라미터를 공유하며 글로벌 성향을 학습하고, 뒤의 2개 네트워크 묶음은 각 스텝에서만 전용으로 사용되는 블록으로 각 로컬 성향을 학습한다.
👀 Split block

- feature transformer 로부터 나온 결과를 두 개로 나누어, 하나는 ReLU 로 보내어 최종 아웃풋 (Decision output) 으로 보내고 다른 하나는 다음 Attentive transformer 로 넘겨준다.
- 향후 각 decision output의 결과를 합산해 전체 의사결정 임베딩을 생성할 수 있고 이 임베딩이 FC layer 를 거치면 최종 classification/regression 예측 결과가 산출된다.
- ReLU layer 의 결과에서 hidden unit 채널의 값들을 모두 합산해 해당 step 의 피처중요도를 산출할 수 있다. 각 단계의 피처중요도 결과를 합산하면 최종 피처 중요도가 도출된다.
📗 Attentive transformer 💨 Mask 를 생성 (변수선택 기능)

- FC , BN, Sparsemax 를 순차적으로 수행하며 Mask 를 생성한다.
- Mask 에는 어떤 피처를 주로 사용할 것인지에 대한 정보가 포함되어 있다.
- 생성된 Mask 에 피처를 곱하여 피처선택이 이루어진다. 이전 step 의 피처와 곱하여 Masked feature 를 생성한다. 이는 다시 Feature transformer 로 연결되며 Step 이 반복된다.
- Prior scale 사전 정보량 : 이전 decision step 들에서 각 feature 가 얼마나 많이 사용되었는지 집계한 정보로, 이전 step 에서 사용한 Mask 를 얼마나 재사용할지 조절할 수 있다. 선택된 변수의 반영률을 조절하는 요인.
- masking 을 통해 학습에 큰 영향을 미치지 않은 변수들의 영향력 감소시킴 👉 mask 를 구하기 위해 attentive transformer 를 사용
- Sparsemax : Softmax의 sparse한 버전으로 sparse 한 데이터셋에 적용했을 때 좋은 성능을 보인 정규화기법이다. 각 변수 별 계수 값들의 일반화를 위해 사용한다. 변수의 양이 많아질수록 값이 0과 1로 수렴되는 경우가 많아짐 👉 더 강력한 피처 선택 의사 결정 과정 (결정의 효과를 높인다)

📘 feature Masking
- feature importance 를 계산
- 이전 Step 의 feature 에 곱하여 Masked feature 를 생성
- 다음 Step 의 Mask 에서 적용할 Prior scale term 계산

- Masked feature 는 다음 step 의 input 이 된다.
👀 Agg(regate) block
- 어떤 feature 가 중요한지 알 수 있다.
📙 feature importance mask

- 각 decision step (M1, M2, ..) 별로 어떤 피처들이 중요하게 사용되었는지를 시각화 한 것이다. 각 단계에서 어떤 변수들이 주요하게 사용되었는지 해석할 수 있다.
4️⃣ 코드 실습
import torch
import torch.nn as nn
from pytorch_tabnet.tab_model import TabNetClassifier
clf = TabNetClassifier() #TabNetRegressor()
clf.fit(
X_train, Y_train,
eval_set=[(X_valid, y_valid)]
)
preds = clf.predict(X_test)
5️⃣ Plus
1. Sparse feature selection = decision blocks
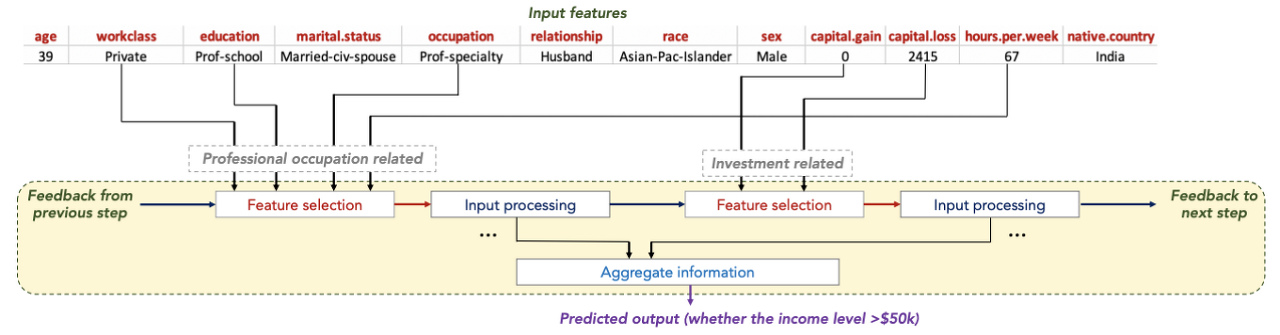
- 여러개의 의사결정 블록을 사용
- 그림에서는 성인 인구조사 데이터를 바탕으로 소득을 예측하는 Tabnet 의 연산 과정을 보여주고 있다. 소득수준을 예측하기 위해 2개의 의사결정 블록이 각각 전문직 여부와 투자액에 관련된 변수가 선택한 것을 볼 수 있다.
2. Mask

- Mask 란 입력변수들 중 선택 변수 외 다른 변수들을 가리는 방법이다.
- 두 변수 x1, x2가 Sparse matrix Mask 를 통과하게 되면 특정 변수를 선택한 것 같은 효과를 얻을 수 있다.
- Ck : 가중치. 이 값이 커질수록 분류를 위한 결정경계가 뚜렷해진다.
- 변수 선택 이후 의미 추출 과정에서 다른 변수들이 개입되지 않으므로 ReLU 를 통과한 결과들은 서로 상호 독립적이다.
- ReLU 를 통해 결과로 나온 output 을 합쳐 의사결정에 사용하는 것이 앙상블 트리 구조와 유사하다.
3. Self-supervised tabular learning
- Tabnet 에서는 자기지도학습 (self - supervised) 을 위해 무작위로 가려진 변수값을 예측하는 autoencoder 구조의 비지도 학습을 수행해 비지도 표현을 학습해 encoder 구조의 지도학습 모델 성능을 향상시킬 수 있다.
- 특정 영역이 masking 된 인코딩 데이터를 원본대로 복원할 수 있도록 학습하는 사전 학습을 통해 예측 성능을 향상, 학습 시간 단축 및 결측치에 대한 보간 효과
- encoder 에서 정보를 압축하고 decoder 에서 확장하여 해석하면서 결측치를 보정할 수 있게 된다.

4. Attenstion
- Encoder : 정보를 압축
- Decoder : 정보를 확장해서 해석
- 벡터 하나에 모든 시퀀스의 정보를 의존하지 않으므로 길이나 순서에 영향을 덜 받음
6️⃣ Tabnet 장점
1. 전처리 과정이 필요하지 않다.
2. Decision step 으로 feature selection 을 진행한다.
3. decision step 별 혹은 모델 전체에 대해 feature importance 를 수치화할 수 있다.
4. 무작위로 가려진 feature 값을 예측하는 unsupervised pretrain 단계를 적용하여 상당한 성능 향상을 보여준다.
5. 실제 데이터는 끊임없이 유입되고 변화하기 때문에 한번의 학습으로 영원히 사용할 수 있는 모델은 없다. 때문에 딥러닝의 pretraining, Incremental learning (iterative train) 특성은 지속 학습 가능한 측면에서 좋은 대안이다.
🐾 참고자료
1. https://wsshin.tistory.com/5
2. https://lv99.tistory.com/83
3. https://housekdk.gitbook.io/ml/ml/tabular/tabnet-overview
4. https://themore-dont-know.tistory.com/2
5. https://today-1.tistory.com/54
6. http://dmqm.korea.ac.kr/activity/seminar/327